Data objects in the Databricks lakehouse
The Databricks lakehouse organizes data stored with Delta Lake in cloud object storage with familiar relations like database, tables, and views. This model combines many of the benefits of an enterprise data warehouse with the scalability and flexibility of a data lake. Learn more about how this model works, and the relationship between object data and metadata so that you can apply best practices when designing and implementing Databricks lakehouse for your organization.
What data objects are in the Databricks lakehouse?
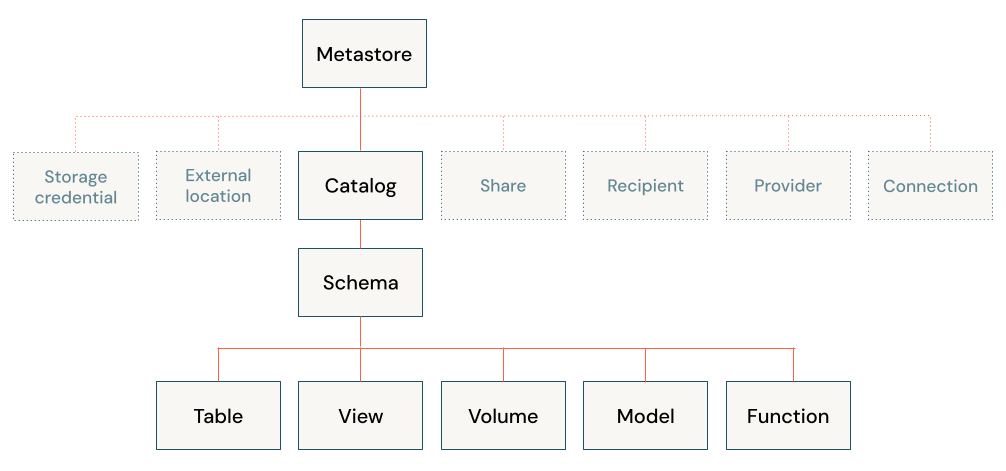
The Databricks lakehouse architecture combines data stored with the Delta Lake protocol in cloud object storage with metadata registered to a metastore. There are five primary objects in the Databricks lakehouse:
Catalog: a grouping of databases.
Database or schema: a grouping of objects in a catalog. Databases contain tables, views, and functions.
Table: a collection of rows and columns stored as data files in object storage.
View: a saved query typically against one or more tables or data sources.
Function: saved logic that returns a scalar value or set of rows.
For information on securing objects with Unity Catalog, see securable objects model.
What is a metastore?
The metastore contains all of the metadata that defines data objects in the lakehouse. Databricks provides the following metastore options:
Unity Catalog metastore: Unity Catalog provides centralized access control, auditing, lineage, and data discovery capabilities. You create Unity Catalog metastores at the Databricks account level, and a single metastore can be used across multiple workspaces.
Each Unity Catalog metastore is configured with a root storage location in a GCS bucket in your Google Cloud account. This storage location is used by default for storing data for managed tables.
In Unity Catalog, data is secure by default. Initially, users have no access to data in a metastore. Access can be granted by either a metastore admin or the owner of an object. Securable objects in Unity Catalog are hierarchical and privileges are inherited downward. Unity Catalog offers a single place to administer data access policies. Users can access data in Unity Catalog from any workspace that the metastore is attached to. For more information, see Manage privileges in Unity Catalog.
Built-in Hive metastore (legacy): Each Databricks workspace includes a built-in Hive metastore as a managed service. An instance of the metastore deploys to each cluster and securely accesses metadata from a central repository for each customer workspace.
The Hive metastore provides a less centralized data governance model than Unity Catalog. By default, a cluster allows all users to access all data managed by the workspace’s built-in Hive metastore unless table access control is enabled for that cluster. For more information, see Hive metastore table access control (legacy).
Table access controls are not stored at the account-level, and therefore they must be configured separately for each workspace. To take advantage of the centralized and streamlined data governance model provided by Unity Catalog, Databricks recommends that you upgrade the tables managed by your workspace’s Hive metastore to the Unity Catalog metastore.
External Hive metastore (legacy): You can also bring your own metastore to Databricks. Databricks clusters can connect to existing external Apache Hive metastores. You can use table access control to manage permissions in an external metastore. Table access controls are not stored in the external metastore, and therefore they must be configured separately for each workspace. Databricks recommends that you use Unity Catalog instead for its simplicity and account-centered governance model.
Regardless of the metastore that you use, Databricks stores all table data in object storage in your cloud account.
What is a catalog?
A catalog is the highest abstraction (or coarsest grain) in the Databricks lakehouse relational model. Every database will be associated with a catalog. Catalogs exist as objects within a metastore.
Before the introduction of Unity Catalog, Databricks used a two-tier namespace. Catalogs are the third tier in the Unity Catalog namespacing model:
catalog_name.database_name.table_name
The built-in Hive metastore only supports a single catalog, hive_metastore.
What is a database?
A database is a collection of data objects, such as tables or views (also called “relations”), and functions. In Databricks, the terms “schema” and “database” are used interchangeably (whereas in many relational systems, a database is a collection of schemas).
Databases will always be associated with a location on cloud object storage. You can optionally specify a LOCATION when registering a database, keeping in mind that:
The
LOCATIONassociated with a database is always considered a managed location.Creating a database does not create any files in the target location.
The
LOCATIONof a database will determine the default location for data of all tables registered to that database.Successfully dropping a database will recursively drop all data and files stored in a managed location.
This interaction between locations managed by database and data files is very important. To avoid accidentally deleting data:
Do not share database locations across multiple database definitions.
Do not register a database to a location that already contains data.
To manage data life cycle independently of database, save data to a location that is not nested under any database locations.
What is a table?
A Databricks table is a collection of structured data. A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema. As Delta Lake is the default storage provider for tables created in Databricks, all tables created in Databricks are Delta tables, by default. Because Delta tables store data in cloud object storage and provide references to data through a metastore, users across an organization can access data using their preferred APIs; on Databricks, this includes SQL, Python, PySpark, Scala, and R.
Note that it is possible to create tables on Databricks that are not Delta tables. These tables are not backed by Delta Lake, and will not provide the ACID transactions and optimized performance of Delta tables. Tables falling into this category include tables registered against data in external systems and tables registered against other file formats in the data lake. See Connect to data sources.
There are two kinds of tables in Databricks, managed and unmanaged (or external) tables.
Note
The Delta Live Tables distinction between live tables and streaming live tables is not enforced from the table perspective.
What is a managed table?
Databricks manages both the metadata and the data for a managed table; when you drop a table, you also delete the underlying data. Data analysts and other users that mostly work in SQL may prefer this behavior. Managed tables are the default when creating a table. The data for a managed table resides in the LOCATION of the database it is registered to. This managed relationship between the data location and the database means that in order to move a managed table to a new database, you must rewrite all data to the new location.
There are a number of ways to create managed tables, including:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
What is an unmanaged table?
Databricks only manages the metadata for unmanaged (external) tables; when you drop a table, you do not affect the underlying data. Unmanaged tables will always specify a LOCATION during table creation; you can either register an existing directory of data files as a table or provide a path when a table is first defined. Because data and metadata are managed independently, you can rename a table or register it to a new database without needing to move any data. Data engineers often prefer unmanaged tables and the flexibility they provide for production data.
There are a number of ways to create unmanaged tables, including:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
What is a view?
A view stores the text for a query typically against one or more data sources or tables in the metastore. In Databricks, a view is equivalent to a Spark DataFrame persisted as an object in a database. Unlike DataFrames, you can query views from any part of the Databricks product, assuming you have permission to do so. Creating a view does not process or write any data; only the query text is registered to the metastore in the associated database.
What is a temporary view?
A temporary view has a limited scope and persistence and is not registered to a schema or catalog. The lifetime of a temporary view differs based on the environment you’re using:
In notebooks and jobs, temporary views are scoped to the notebook or script level. They cannot be referenced outside of the notebook in which they are declared, and will no longer exist when the notebook detaches from the cluster.
In Databricks SQL, temporary views are scoped to the query level. Multiple statements within the same query can use the temp view, but it cannot be referenced in other queries, even within the same dashboard.
Global temporary views are scoped to the cluster level and can be shared between notebooks or jobs that share computing resources. Databricks recommends using views with appropriate table ACLs instead of global temporary views.
What is a function?
Functions allow you to associate user-defined logic with a database. Functions can return either scalar values or sets of rows. Functions are used to aggregate data. Databricks allows you to save functions in various languages depending on your execution context, with SQL being broadly supported. You can use functions to provide managed access to custom logic across a variety of contexts on the Databricks product.
How do relational objects work in Delta Live Tables?
Delta Live Tables uses declarative syntax to define and manage DDL, DML, and infrastructure deployment. Delta Live Tables uses the concept of a “virtual schema” during logic planning and execution. Delta Live Tables can interact with other databases in your Databricks environment, and Delta Live Tables can publish and persist tables for querying elsewhere by specifying a target database in the pipeline configuration settings.
All tables created in Delta Live Tables are Delta tables. When using Unity Catalog with Delta Live Tables, all tables are Unity Catalog managed tables. If Unity Catalog is not active, tables can be declared as either managed or unmanaged tables.
While views can be declared in Delta Live Tables, these should be thought of as temporary views scoped to the pipeline. Temporary tables in Delta Live Tables are a unique concept: these tables persist data to storage but do not publish data to the target database.
Some operations, such as APPLY CHANGES INTO, will register both a table and view to the database; the table name will begin with an underscore (_) and the view will have the table name declared as the target of the APPLY CHANGES INTO operation. The view queries the corresponding hidden table to materialize the results.
