Introduction to Databricks Workflows
Databricks Workflows orchestrates data processing, machine learning, and analytics pipelines on the Databricks Data Intelligence Platform. Workflows has fully managed orchestration services integrated with the Databricks platform, including Databricks Jobs to run non-interactive code in your Databricks workspace and Delta Live Tables to build reliable and maintainable ETL pipelines.
To learn more about the benefits of orchestrating your workflows with the Databricks platform, see Databricks Workflows.
An example Databricks workflow
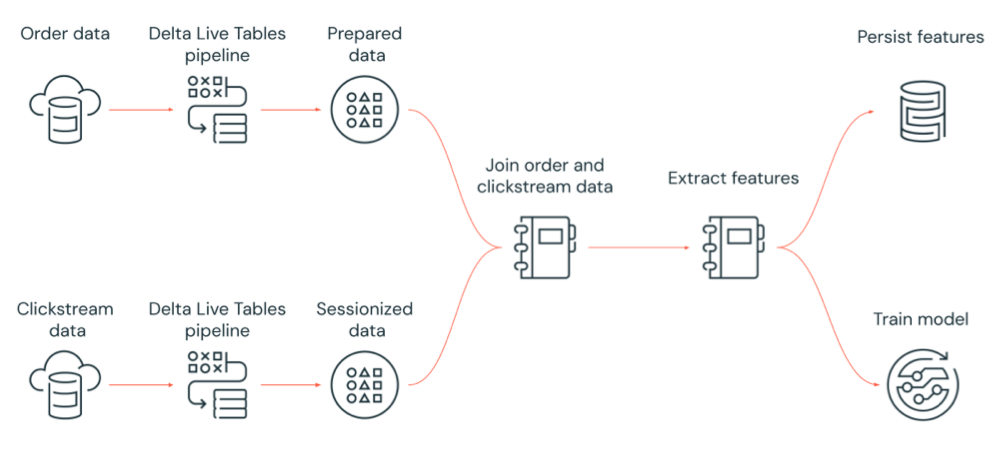
The following diagram illustrates a workflow that is orchestrated by a Databricks job to:
Run a Delta Live Tables pipeline that ingests raw clickstream data from cloud storage, cleans and prepares the data, sessionizes the data, and persists the final sessionized data set to Delta Lake.
Run a Delta Live Tables pipeline that ingests order data from cloud storage, cleans and transforms the data for processing, and persist the final data set to Delta Lake.
Join the order and sessionized clickstream data to create a new data set for analysis.
Extract features from the prepared data.
Perform tasks in parallel to persist the features and train a machine learning model.
What is Databricks Jobs?
Note
The CLI feature is unavailable on Databricks on Google Cloud as of this release.
A Databricks job is a way to run your data processing and analysis applications in a Databricks workspace. Your job can consist of a single task or can be a large, multi-task workflow with complex dependencies. Databricks manages the task orchestration, cluster management, monitoring, and error reporting for all of your jobs. You can run your jobs immediately, periodically through an easy-to-use scheduling system, or continuously to ensure an instance of the job is always running. You can also run jobs interactively in the notebook UI.
You can create and run a job using the Jobs UI, the Databricks CLI, or by invoking the Jobs API. You can repair and re-run a failed or canceled job using the UI or API. You can monitor job run results using the UI, CLI, API, and notifications (for example, email, webhook destination, or Slack notifications).
To learn about using the Databricks CLI, see What is the Databricks CLI?. To learn about using the Jobs API, see the Jobs API.
The following sections cover important features of Databricks Jobs.
Important
A workspace is limited to 1000 concurrent task runs. A
429 Too Many Requestsresponse is returned when you request a run that cannot start immediately.The number of jobs a workspace can create in an hour is limited to 10000 (includes “runs submit”). This limit also affects jobs created by the REST API and notebook workflows.
Implement data processing and analysis with job tasks
You implement your data processing and analysis workflow using tasks. A job is composed of one or more tasks. You can create job tasks that run notebooks, JARS, Delta Live Tables pipelines, or Python, Scala, Spark submit, and Java applications. Your job tasks can also orchestrate Databricks SQL queries, alerts and dashboards to create analyses and visualizations, or you can use the dbt task to run dbt transformations in your workflow. Legacy Spark Submit applications are also supported.
You can also add a task to a job that runs a different job. This feature allows you to break a large process into multiple smaller jobs, or create generalized modules that can be reused by multiple jobs.
You control the execution order of tasks by specifying dependencies between the tasks. You can configure tasks to run in sequence or parallel.
Run jobs interactively, continuously, or using job triggers
You can run your jobs interactively from the Jobs UI, API, or CLI or you can run a continuous job. You can create a schedule to run your job periodically or run your job when new files arrive in an external location such as Amazon S3, Azure storage or Google Cloud storage.
Monitor job progress with notifications
You can receive notifications when a job or task starts, completes, or fails. You can send notifications to one or more email addresses or system destinations (for example, webhook destinations or Slack). See Add email and system notifications for job events.
Run your jobs with Databricks compute resources
Databricks clusters and SQL warehouses provide the computation resources for your jobs. You can run your jobs with a job cluster, an all-purpose cluster, or a SQL warehouse:
A job cluster is a dedicated cluster for your job or individual job tasks. Your job can use a job cluster that’s shared by all tasks or you can configure a cluster for individual tasks when you create or edit a task. An job cluster is created when the job or task starts and terminated when the job or task ends.
An all-purpose cluster is a shared cluster that is manually started and terminated and can be shared by multiple users and jobs.
To optimize resource usage, Databricks recommends using a job cluster for your jobs. To reduce the time spent waiting for cluster startup, consider using an all-purpose cluster. See Use Databricks compute with your jobs.
You use a SQL warehouse to run dbt transformations with the dbt task.
Next steps
To get started with Databricks Jobs:
Create your first Databricks job with the quickstart.
Learn how to create and run workflows with the Databricks Jobs user interface.
Learn about monitoring job runs in the Databricks Jobs user interface.
Learn about configuration options for jobs.
Learn more about building, managing, and troubleshooting workflows with Databricks Jobs:
Learn how to communicate information between tasks in a Databricks job with task values.
Learn how to pass context about job runs into job tasks with task parameter variables.
Learn how to configure your job tasks to run conditionally based on the status of the task’s dependencies.
Learn how to troubleshoot and fix failed jobs.
Get notified when your job runs start, complete or fail with job run notifications.
Trigger your jobs on a custom schedule or run a continuous job.
Learn how to run your Databricks job when new data arrives with file arrival triggers.
Learn how to use Databricks compute resources to run your jobs.
Learn about Updating from Jobs API 2.0 to 2.1 to support creating and managing workflows with Databricks jobs.
Use how-to guides and tutorials to learn more about implementing data workflows with Databricks Jobs.
What is Delta Live Tables?
Delta Live Tables is a framework that simplifies ETL and streaming data processing. Delta Live Tables provides efficient ingestion of data with built-in support for Auto Loader, SQL and Python interfaces that support declarative implementation of data transformations, and support for writing transformed data to Delta Lake. You define the transformations to perform on your data, and Delta Live Tables manages task orchestration, cluster management, monitoring, data quality, and error handling.
To get started, see What is Delta Live Tables?.
Databricks Jobs and Delta Live Tables
Databricks Jobs and Delta Live Tables provide a comprehensive framework for building and deploying end-to-end data processing and analysis workflows.
Use Delta Live Tables for all ingestion and transformation of data. Use Databricks Jobs to orchestrate workloads composed of a single task or multiple data processing and analysis tasks on the Databricks platform, including Delta Live Tables ingestion and transformation.
As a workflow orchestration system, Databricks Jobs also supports:
Running jobs on a triggered basis, for example, running a workflow on a schedule.
Data analysis through SQL queries, machine learning and data analysis with notebooks, scripts, or external libraries, and so forth.
Running a job composed of a single task, for example, running an Apache Spark job packaged in a JAR.
Workflow orchestration with Apache AirFlow
Although Databricks recommends using Databricks Jobs to orchestrate your data workflows, you can also use Apache Airflow to manage and schedule your data workflows. With Airflow, you define your workflow in a Python file, and Airflow manages scheduling and running the workflow. See Orchestrate Databricks jobs with Apache Airflow.
