MLflow Tracing for agents
Important
This feature is in Public Preview.
This article describes MLflow Tracing on Databricks and how to use it to add observability to your generative AI applications.
What is MLflow Tracing?
MLflow Tracing captures detailed information about the execution of gen AI applications. Tracing logs inputs, outputs, and metadata associated with each intermediate step of a request so you can pinpoint the source of bugs and unexpected behavior. For example, if your model hallucinates, you can quickly inspect each step that led to the hallucination.
MLflow Tracing is integrated with Databricks tools and infrastructure, allowing you to store and display traces in Databricks notebooks or the MLflow experiment UI.
Why use MLflow Tracing?
MLflow Tracing provides several benefits:
Review an interactive trace visualization and use the investigation tool to diagnose issues.
Verify that prompt templates and guardrails produce reasonable results.
Analyze the latency of different frameworks, models, and chunk sizes.
Measure application costs by seeing token use across different models.
Establish benchmark “golden” datasets to evaluate the performance of different versions.
Add traces to your agent
MLflow Tracing supports three methods for adding traces to your generative AI applications. For API reference details, see the MLflow documentation.
API |
Recommended use case |
Description |
|---|---|---|
Development with integrated GenAI libraries |
Autologging automatically logs traces for supported open source frameworks like LangChain, LlamaIndex, and OpenAI. |
|
Custom agent with Pyfunc |
Low-code APIs for adding traces without worrying about managing the tree structure of the trace. MLflow determines the appropriate parent-child span relationships automatically using the Python stack. |
|
Advanced use cases such as multi-threading |
|
Install MLflow Tracing
MLflow Tracing is available in MLflow versions 2.13.0 and above, which is preinstalled in <DBR< 15.4 LTS ML and above. If necessary, install MLflow with the following code:
%pip install mlflow>=2.13.0 -qqqU
%restart_python
Alternatively, you can install the latest version of databricks-agents, which includes a compatible MLflow version:
%pip install databricks-agents
Use autologging to add traces to your agents
If your GenAI library supports tracing, such as LangChain or OpenAI, enable autologging by adding mlflow.<library>.autolog() to your code. For example:
mlflow.langchain.autolog()
Note
As of Databricks Runtime 15.4 LTS ML, MLflow tracing is enabled by default within notebooks. To disable tracing, for example, with LangChain, you can execute mlflow.langchain.autolog(log_traces=False) in your notebook.
MLflow supports additional libraries for trace auto logging. For a full list of integrated libraries, see the MLflow Tracing documentation.
Use Fluent APIs to manually add traces to your agent
Fluent APIs in MLflow automatically create trace hierarchies based on your code’s execution flow.
Decorate your function
Use the @mlflow.trace decorator to create a span for the scope of the decorated function.
The MLflow Span object organizes tracing steps. Spans captures information on individual operations or steps, such as API calls or vector store queries, within a workflow.
The span starts when the function is invoked and ends when it returns. MLflow records the input and output of the function and any exceptions raised from the function.
For example, the following code creates a span named my_function that captures input arguments x and y and the output.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
Use the tracing context manager
If you want to create a span for an arbitrary block of code, not just a function, you can use mlflow.start_span() as a context manager that wraps the code block. The span starts when the context is entered and ends when the context is exited. The span input and outputs should be provided manually using setter methods of the span object yielded by the context manager.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Wrap an external function
To trace external library functions, wrap the function with mlflow.trace.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
### Fluent API example
The following example shows how to use the Fluent APIs `mlflow.trace` and `mlflow.start_span` to trace the `quickstart-agent`:
```python
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
After adding the trace, run the function. The following continues the example with the predict() function in the previous section. The traces are automatically shown when you run the invocation method, predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
MLflow Client APIs
MlflowClient exposes granular, thread-safe APIs to start and end traces, manage spans, and set span fields. It provides complete control of the trace lifecycle and structure. These APIs are useful when the Fluent APIs are insufficient for your requirements, such as multi-threaded applications and callbacks.
The following are steps to create a complete trace using the MLflow Client.
Create an instance of MLflowClient by
client = MlflowClient().Start a trace using the
client.start_trace()method. This initiates the trace context, starts an absolute root span, and returns a root span object. This method must be run before thestart_span()API.Set your attributes, inputs, and outputs for the trace in
client.start_trace().
Note
There is not an equivalent to the
start_trace()method in the Fluent APIs. This is because the Fluent APIs automatically initialize the trace context and determine whether it is the root span based on the managed state.The start_trace() API returns a span. Get the request ID, a unique identifier of the trace also referred to as the
trace_id, and the ID of the returned span usingspan.request_idandspan.span_id.Start a child span using
client.start_span(request_id, parent_id=span_id)to set your attributes, inputs, and outputs for the span.This method requires
request_idandparent_idto associate the span with the correct position in the trace hierarchy. It returns another span object.
End the child span by calling
client.end_span(request_id, span_id).Repeat Steps 3 - 5 for any child spans you want to create.
After all the child spans end, call
client.end_trace(request_id)to close the trace and record it.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
Reviewing traces
To review traces after running the agent, use one of the following options:
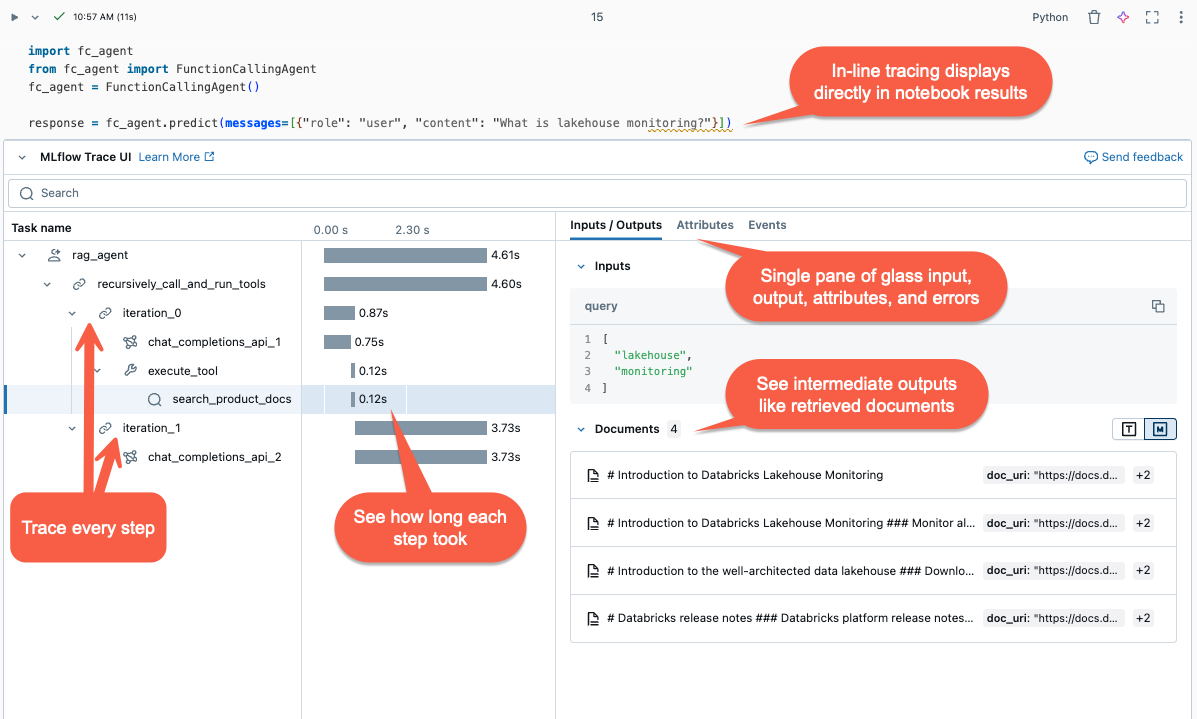
The trace visualization is rendered inline in the cell output.
The traces are logged to your MLflow experiment. You can review and search the full list of historical traces in the Traces tab on the Experiment page. When the agent runs under an active MLflow Run, traces appear on the Run page.
Programmatically retrieve traces using search_traces() API.
Limitations
MLflow Tracing is available in Databricks notebooks and notebook jobs.
LangChain autologging may not support all LangChain prediction APIs. For the complete list of supported APIs, see MLflow documentation.