What is asynchronous progress tracking?
Preview
This feature is in Public Preview.
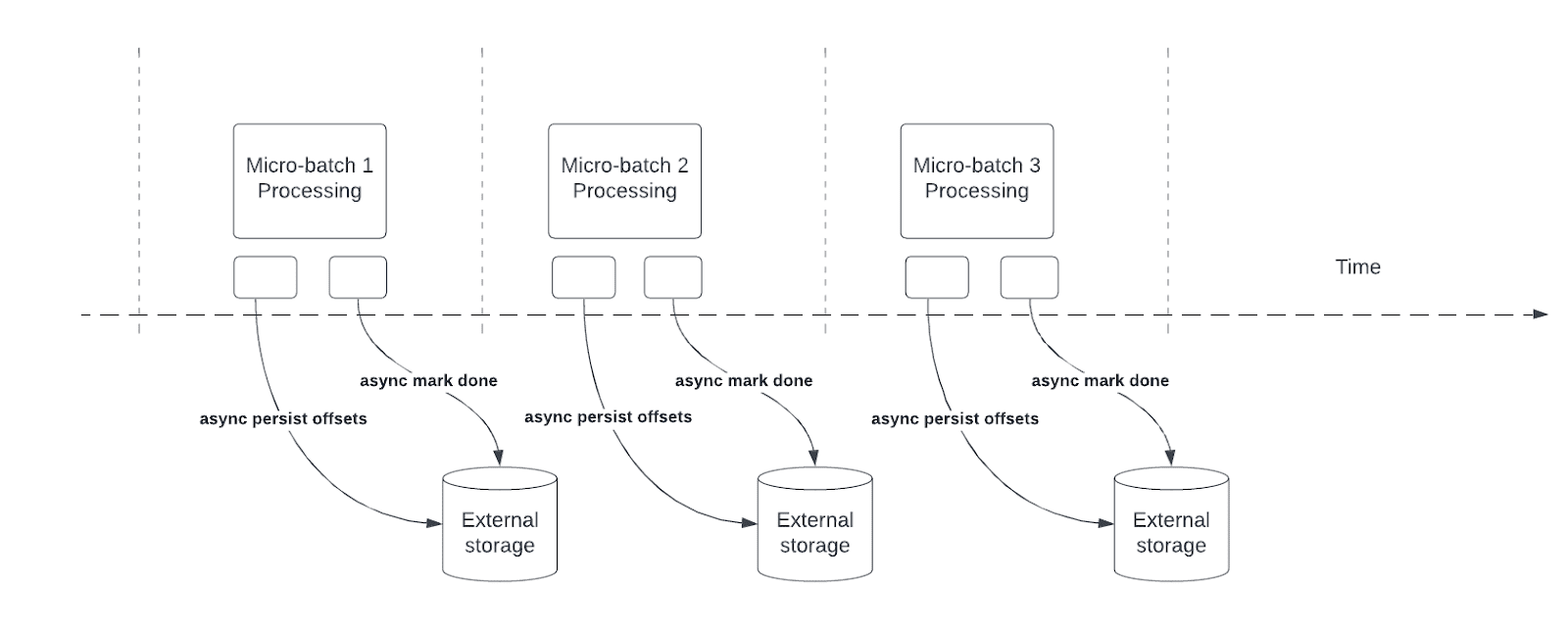
Asynchronous progress tracking allows Structured Streaming pipelines to checkpoint progress asynchronously and in parallel to the actual data processing within a micro-batch, reducing latency associated with maintaining the offsetLog and commitLog.
Note
Asynchronous progress tracking does not work with Trigger.once or Trigger.availableNow triggers. Attempting to enable this feature with these triggers results in query failure.
How does asynchronous progress tracking work to reduce latency?
Structured Streaming relies on persisting and managing offsets as progress indicators for query processing. Offset management operation directly impacts processing latency, because no data processing can occur until these operations are complete. Asynchronous progress tracking enables Structured Streaming pipelines to checkpoint progress without being impacted by these offset management operations.
When should you configure checkpoint frequency?
Users can configure the frequency at which progress is checkpointed. The default settings for checkpoint frequency provide good throughput for most queries. Configuring the frequency is helpful for scenarios in which offset management operations occur at a higher rate than they can be processed, which creates an ever increasing backlog of offset management operations. To stem this growing backlog, data processing is blocked or slowed, essentially reverting the processing behavior to eliminate the benefits of asynchronous progress tracking.
Note
Failure recovery time increases with the increase in checkpoint interval time. In case of failure, a pipeline has to reprocess all the data before the previous successful checkpoint. Users can consider this trade-off between lower latency during regular processing and recovery time in case of failure.
What configurations are associated with asynchronous progress tracking?
Option |
Value |
Default |
Description |
|---|---|---|---|
asyncProgressTrackingEnabled |
true/false |
false |
enable or disable asynchronous progress tracking |
asyncProgressTrackingCheckpointIntervalMs |
milliseconds |
1000 |
the interval in which we commit offsets and completion commits |
How can users enable asynchronous progress tracking?
Users can use code similar to the code below to enable this feature:
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Turning off asynchronous progress tracking
When async progress tracking is enabled, the framework does not checkpoint progress for every batch. To address this, before you disable asynchronous progress tracking, process at least two micro-batches with the following settings:
.option("asyncProgressTrackingEnabled", "true").option("asyncProgressTrackingCheckpointIntervalMs", 0)
Stop the query after at least two micro-batches have finished processing. Now you can safely disable the async progress tracking and restart the query.
If you have disabled asynchronous progress tracking without completing this step, you may encounter the following error:
java.lang.IllegalStateException: batch x doesn't exist
In the driver logs, you might see the following error:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Following the instructions in this section to disable asynchronous progress tracking allows you to address these errors and repair your streaming workload.
Limitations with asynchronous progress tracking
This feature has the following limitations:
Asynchronous progress tracking is only supported in stateless pipelines when using Kafka as a sink.
Exactly once end-to-end processing is not guaranteed with asynchronous progress tracking because offset ranges for batch can be changed in case of failure. Some sinks, such as Kafka, never provide exactly-once guarantees.