What are Unity Catalog volumes?
Volumes are Unity Catalog objects that enable governance over non-tabular datasets. Volumes represent a logical volume of storage in a cloud object storage location. Volumes provide capabilities for accessing, storing, governing, and organizing files.
While tables provide governance over tabular datasets, volumes add governance over non-tabular datasets. You can use volumes to store and access files in any format, including structured, semi-structured, and unstructured data.
Databricks recommends using volumes to govern access to all non-tabular data. Like tables, volumes can be managed or external.
Important
You cannot use volumes as a location for tables. Volumes are intended for path-based data access only. Use tables when you want to work with tabular data in Unity Catalog.
The following articles provide more information about working with volumes:
Note
When you work with volumes, you must use a SQL warehouse or a cluster running Databricks Runtime 13.3 LTS or above, unless you are using Databricks UIs such as Catalog Explorer.
What is a managed volume?
A managed volume is a Unity Catalog-governed storage volume created within the managed storage location of the containing schema. See Specify a managed storage location in Unity Catalog.
Managed volumes allow the creation of governed storage for working with files without the overhead of external locations and storage credentials. You do not need to specify a location when creating a managed volume, and all file access for data in managed volumes is through paths managed by Unity Catalog.
What is an external volume?
An external volume is a Unity Catalog-governed storage volume registered against a directory within an external location using Unity Catalog-governed storage credentials.
Unity Catalog does not manage the lifecycle and layout of the files in external volumes. When you drop an external volume, Unity Catalog does not delete the underlying data.
What path is used for accessing files in a volume?
Volumes sit at the third level of the Unity Catalog three-level namespace (catalog.schema.volume):
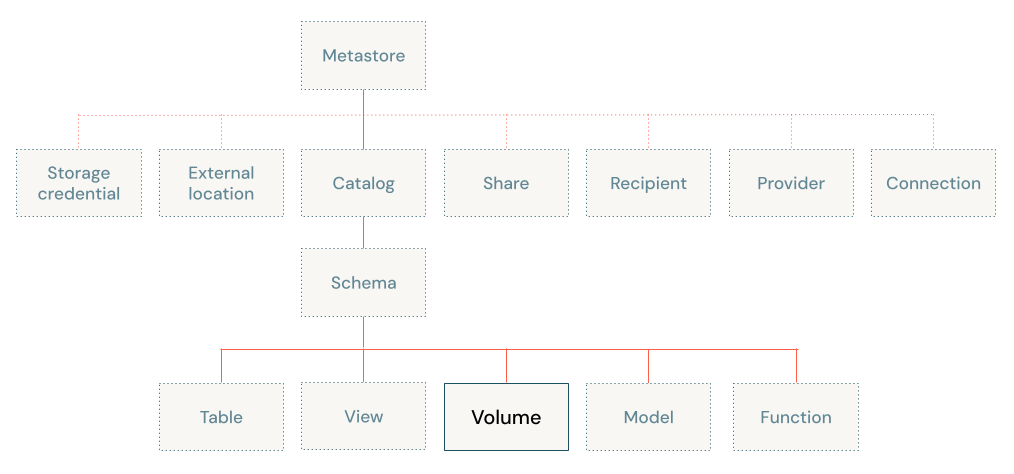
The path to access volumes is the same whether you use Apache Spark, SQL, Python, or other languages and libraries. This differs from legacy access patterns for files in object storage bound to a Databricks workspace.
The path to access files in volumes uses the following format:
/Volumes/<catalog>/<schema>/<volume>/<path>/<file-name>
Databricks also supports an optional dbfs:/ scheme when working with Apache Spark, so the following path also works:
dbfs:/Volumes/<catalog>/<schema>/<volume>/<path>/<file-name>
The sequence /<catalog>/<schema>/<volume> in the path corresponds to the three Unity Catalog object names associated with the file. These path elements are read-only and not directly writeable by users, meaning it is not possible to create or delete these directories using filesystem operations. They are automatically managed and kept in sync with the corresponding Unity Catalog entities.
Note
You can also access data in external volumes using cloud storage URIs.
Reserved paths for volumes
Volumes introduces the following reserved paths used for accessing volumes:
dbfs:/Volumes/Volumes
Note
Paths are also reserved for potential typos for these paths from Apache Spark APIs and dbutils, including /volumes, /Volume, /volume, whether or not they are preceded by dbfs:/. The path /dbfs/Volumes is also reserved, but cannot be used to access volumes.
Volumes are only supported on Databricks Runtime 13.3 LTS and above. In Databricks Runtime 12.2 LTS and below, operations against /Volumes paths might succeed, but they can only write data to ephemeral storage disks attached to compute clusters rather than persisting data to Unity Catalog volumes as expected.
Important
If you have pre-existing data stored in a reserved path on the DBFS root, you can file a support ticket to gain temporary access to this data to move it to another location.
Limitations
You must use Unity Catalog-enabled compute to interact with Unity Catalog volumes. Volumes do not support all workloads.
The following table outlines Unity Catalog volume limitations based on the version of Databricks Runtime:
Databricks Runtime version |
Limitations |
|---|---|
14.3 LTS and above |
|
14.2 and below |
|
All supported Databricks Runtime versions |
|