Jobs system table reference
Note
The lakeflow schema was previously known as workflow. The content of both schemas is identical. To make the lakeflow schema visible, you must enable it separately.
Note
These tables are unavailable in the asia-south1 region.
This article is a reference for how to use the lakeflow system tables to monitor jobs in your account. These tables include records from all workspaces in your account deployed in the same cloud region. To see records from another region, you must view the tables from a workspace deployed in that region.
Requirements
The
system.lakeflowschema must be enabled by an account admin. See Enable system table schemas.To access these system tables, users must either:
Be both a metastore admin and an account admin, or
Have
USEandSELECTpermissions on the system schemas. See Grant access to system tables.
Available jobs tables
All jobs-related system tables live in the system.lakeflow schema. Currently, the schema hosts four tables:
Table |
Description |
Supports streaming |
Free retention period |
Includes global or regional data |
|---|---|---|---|---|
jobs (Public Preview) |
Tracks all jobs created in the account |
Yes |
365 days |
Regional |
job_tasks (Public Preview) |
Tracks all job tasks that run in the account |
Yes |
365 days |
Regional |
job_run_timeline (Public Preview) |
Tracks the job runs and related metadata |
Yes |
365 days |
Regional |
job_task_run_timeline (Public Preview) |
Tracks job task runs and related metadata |
Yes |
365 days |
Regional |
Detailed schema reference
The following sections provide schema references for each of the jobs-related system tables.
Jobs table schema
The jobs table is a slowly changing dimension table (SCD2). When a row changes, a new row is emitted, logically replacing the previous one.
Table path: system.lakeflow.jobs
Column name |
Data type |
Description |
Notes |
|---|---|---|---|
|
string |
The ID of the account this job belongs to |
|
|
string |
The ID of the workspace this job belongs to |
|
|
string |
The ID of the job |
Only unique within a single workspace |
|
string |
The user-supplied name of the job |
|
|
string |
The user-supplied description of the job |
This field is empty if you have customer-managed keys configured. Not populated for rows emitted before late August 2024 |
|
string |
The ID of the principal who created the job |
|
|
string |
The user-supplied custom tags associated with this job |
|
|
timestamp |
The time when the job was last modified |
Timezone recorded as +00:00 (UTC) |
|
timestamp |
The time when the job was deleted by the user |
Timezone recorded as +00:00 (UTC) |
|
string |
The ID of the user or service principal whose permissions are used for the job run |
Job task table schema
The job tasks table is a slowly changing dimension table (SCD2). When a row changes, a new row is emitted, logically replacing the previous one.
Table path: system.lakeflow.job_tasks
Column name |
Data type |
Description |
Notes |
|---|---|---|---|
|
string |
The ID of the account this job belongs to |
|
|
string |
The ID of the workspace this job belongs to |
|
|
string |
The ID of the job |
Only unique within a single workspace |
|
string |
The reference key for a task in a job |
Only unique within a single job |
|
array |
The task keys of all upstream dependencies of this task |
|
|
timestamp |
The time when the task was last modified |
Timezone recorded as +00:00 (UTC) |
|
timestamp |
The time when a task was deleted by the user |
Timezone recorded as +00:00 (UTC) |
Job run timeline table schema
The job run timeline table is immutable and complete at the time it is produced.
Table path: system.lakeflow.job_run_timeline
Column name |
Data type |
Description |
Notes |
|---|---|---|---|
|
string |
The ID of the account this job belongs to |
|
|
string |
The ID of the workspace this job belongs to |
|
|
string |
The ID of the job |
This key is only unique within a single workspace |
|
string |
The ID of the job run |
|
|
timestamp |
The start time for the run or for the time period |
Timezone information is recorded at the end of the value with |
|
timestamp |
The end time for the run or for the time period |
Timezone information is recorded at the end of the value with |
|
string |
The type of trigger that can fire a run |
For possible values, see Trigger type values |
|
string |
The type of job run |
For possible values, see Run type values |
|
string |
The user-supplied run name associated with this job run |
|
|
array |
Array containing the job compute IDs for the parent job run |
Use for identifying job cluster used by Not populated for rows emitted before late August 2024 |
|
string |
The outcome of the job run |
For possible values, see Result state values |
|
string |
The termination code of the job run |
For possible values, see Termination code values. Not populated for rows emitted before late August 2024 |
|
map |
The job-level parameters used in the job run |
The deprecated notebook_params settings are not included in this field. Not populated for rows emitted before late August 2024 |
Example query
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
Job task run timeline table schema
The job task run timeline table is immutable and complete at the time it is produced.
Table path: system.lakeflow.job_task_run_timeline
Column name |
Data type |
Description |
Notes |
|---|---|---|---|
|
string |
The ID of the account this job belongs to |
|
|
string |
The ID of the workspace this job belongs to |
|
|
string |
The ID of the job |
Only unique within a single workspace |
|
string |
The ID of the task run |
|
|
string |
The ID of the job run |
Not populated for rows emitted before late August 2024 |
|
string |
The ID of the parent run |
Not populated for rows emitted before late August 2024 |
|
timestamp |
The start time for the task or for the time period |
Timezone information is recorded at the end of the value with |
|
timestamp |
The end time for the task or for the time period |
Timezone information is recorded at the end of the value with |
|
string |
The reference key for a task in a job |
This key is only unique within a single job |
|
array |
The compute_ids array contains IDs of job clusters, interactive clusters, and SQL warehouses used by the job task |
|
|
string |
The outcome of the job task run |
For possible values, see Result state values |
|
string |
The termination code of the task run |
For possible values, see Termination code values. Not populated for rows emitted before late August 2024 |
Common join patterns
The following sections provide sample queries that highlight commonly used join patterns for jobs system tables.
Join the jobs and job run timeline tables
Enrich job run with a job name
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Enrich usage with a job name
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
usage.*,
coalesce(usage_metadata.job_name, jobs.name) as job_name
FROM system.billing.usage
LEFT JOIN jobs ON usage.workspace_id=jobs.workspace_id AND usage.usage_metadata.job_id=jobs.job_id
WHERE
billing_origin_product="JOBS"
Join the job run timeline and usage tables
Enrich each billing log with job run metadata
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Calculate cost per job run
This query joins with the billing.usage system table to calculate a cost per job run.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Join the job task run timeline and clusters tables
Enrich job task runs with clusters metadata
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Find jobs running on all-purpose compute
This query joins with the compute.clusters system table to return recent jobs that are running on all-purpose compute instead of jobs compute.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Jobs monitoring dashboard
The following dashboard uses system tables to help you get started monitoring your jobs and operational health. It includes common use cases such as job performance tracking, failure monitoring, and resource utilization.
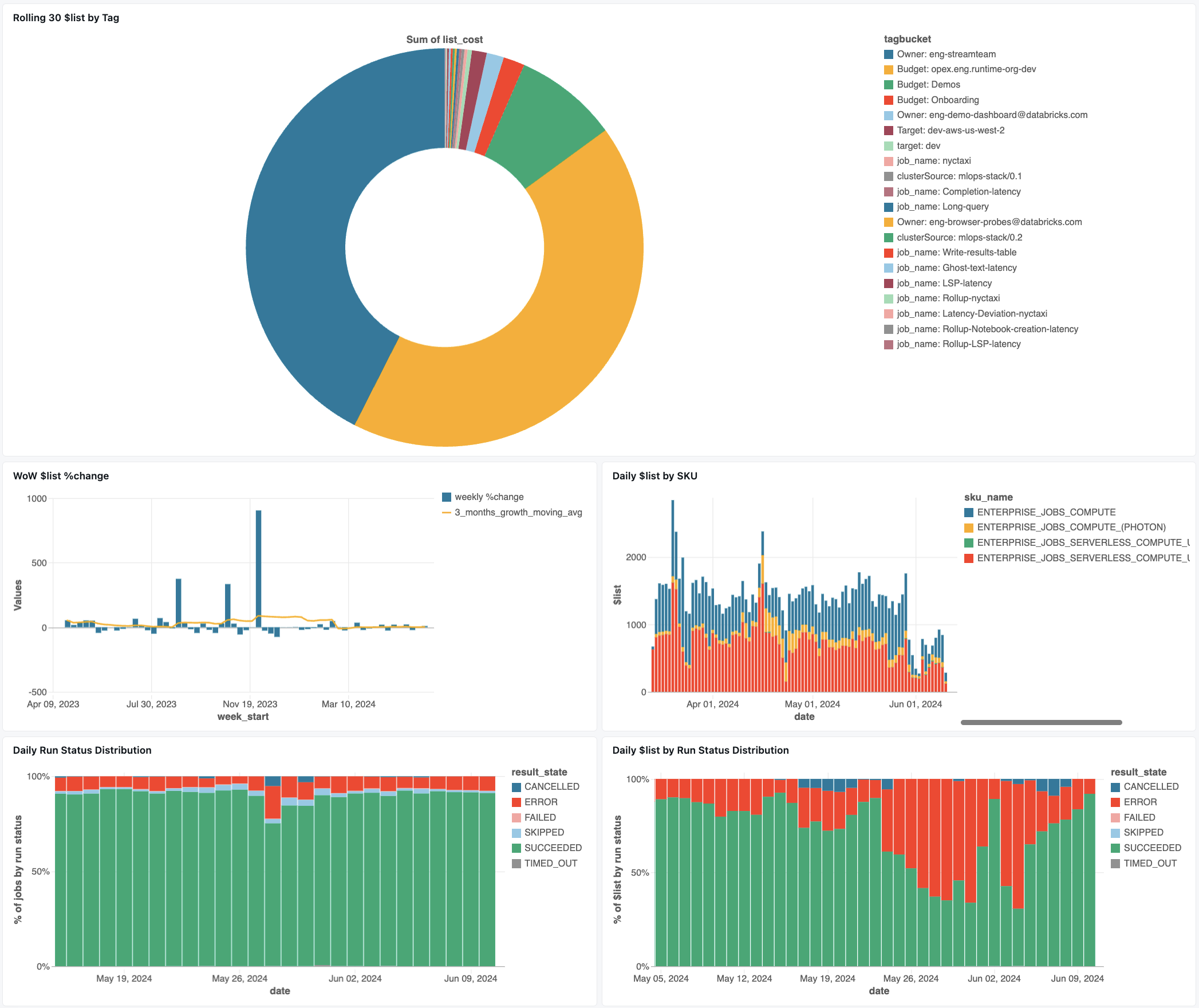
For information on downloading the dashboard, see Monitor job costs & performance with system tables
Troubleshooting
Job is not logged in the lakeflow.jobs table
If a job is not visible in the system tables:
The job wasn’t modified in the last 365 days
Modify any of the job’s fields present in the schema to emit a new record.
The job was created in a different region
Recent job creation (table lag)
Can’t find a job seen in the job_run_timeline table
Not all job runs are visible everywhere. While JOB_RUN entries appear in all job-related tables, WORKFLOW_RUN (notebook workflow runs) are recorded only in job_run_timeline and SUBMIT_RUN (one-time submitted runs) are only recorded in both timeline tables. These runs are not populated to other job system tables like jobs or job_tasks.
See the Run types table below for a detailed breakdown of where each type of run is visible and accessible.
Job run not visible in billing.usage table
In system.billing.usage, the usage_metadata.job_id is only populated for jobs that run on job compute or serverless compute.
Additionally, WORKFLOW_RUN jobs do not have their own usage_metadata.job_id or usage_metadata.job_run_id attribution in system.billing.usage.
Instead, their compute usage is attributed to the parent notebook that triggered them.
This means when a notebook launches a workflow run, all compute costs appear under the parent notebook’s usage, not as a separate workflow job.
See Usage metadata reference for more information.
Calculate the cost of a job running on an all-purpose compute
Precise cost calculation for jobs running on purpose compute is not possible with 100% accuracy. When a job runs on an interactive (all-purpose) compute, multiple workloads like notebooks, SQL queries, or other jobs often run simultaneously on that same compute resource. Because the cluster resources are shared, there’s no direct 1:1 mapping between computing costs and individual job runs.
For accurate job cost tracking, Databricks recommends running jobs on dedicated job compute or serverless compute, where the usage_metadata.job_id and usage_metadata.job_run_id allow for precise cost attribution.
If you must use all-purpose compute, you can:
Monitor overall cluster usage and costs in
system.billing.usagebased onusage_metadata.cluster_id.Track job runtime metrics separately.
Consider that any cost estimate will be approximate due to shared resources.
See Usage metadata reference for more information on cost attribution.
Reference values
The following section includes references for select columns in jobs-related tables.
Trigger type values
The possible values for the trigger_type column are:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Run type values
The possible values for the run_type column are:
Type |
Description |
UI Location |
API Endpoint |
System Tables |
|---|---|---|---|---|
|
Standard job execution |
Jobs & Job Runs UI |
/jobs and /jobs/runs endpoints |
jobs, job_tasks, job_run_timeline, job_task_run_timeline |
|
One-time run via POST /jobs/runs/submit |
Job Runs UI only |
/jobs/runs endpoints only |
job_run_timeline, job_task_run_timeline |
|
Run initiated from notebook workflow |
Not visible |
Not accessible |
job_run_timeline |
Result state values
The possible values for the result_state column are:
State |
Description |
|---|---|
|
The run completed successfully |
|
The run completed with an error |
|
Run was never executed because a condition was not met |
|
The run was canceled at the user’s request |
|
The run was stopped after reaching the timeout |
|
The run completed with an error |
|
The run was blocked on an upstream dependency |
Termination code values
The possible values for the termination_code column are:
Termination code |
Description |
|---|---|
|
The run was completed successfully |
|
The run was canceled during execution by the Databricks platform; for example, if the maximum run duration was exceeded |
|
Run was never executed, for example, if the upstream task run failed, the dependency type condition was not met, or there were no material tasks to execute |
|
The run encountered an error while communicating with the Spark Driver |
|
The run failed due to a cluster error |
|
Failed to complete the checkout due to an error when communicating with the third party service |
|
The run failed because it issued an invalid request to start the cluster |
|
The workspace has reached the quota for the maximum number of concurrent active runs. Consider scheduling the runs over a larger time frame |
|
The run failed because it tried to access a feature unavailable for the workspace |
|
The number of cluster creation, start, and upsize requests has exceeded the allotted rate limit. Consider spreading the run execution over a larger time frame |
|
The run failed due to an error when accessing the customer blob storage |
|
The run was completed with task failures |
|
The run failed due to a permission issue while accessing a resource |
|
The run failed while installing the user-requested library. The causes might include, but are not limited to: The provided library is invalid, there are insufficient permissions to install the library, and so forth |
|
The scheduled run exceeds the limit of maximum concurrent runs set for the job |
|
The run is scheduled on a cluster that has already reached the maximum number of contexts it is configured to create |
|
A resource necessary for run execution does not exist |
|
The run failed due to an invalid configuration |
|
The run failed due to a cloud provider issue |
|
The run was skipped due to reaching the job level queue size limit |