Orchestrate notebooks and modularize code in notebooks
Learn how to orchestrate notebooks and modularize code in notebooks. See examples and understand when to use alternative methods for notebook orchestration.
Orchestration and code modularization methods
The following table compares the methods available for orchestrating notebooks and modularizing code in notebooks.
Method |
Use case |
Notes |
|---|---|---|
Notebook orchestration (recommended) |
Recommended method for orchestrating notebooks. Supports complex workflows with task dependencies, scheduling, and triggers. Provides a robust and scalable approach for production workloads, but requires setup and configuration. |
|
Notebook orchestration |
Use Starts a new ephemeral job for each call, which can increase overhead and lacks advanced scheduling features. |
|
Code modularization (recommended) |
Recommended method for modularizing code. Modularize code into reusable code files stored in the workspace. Supports version control with repos and integration with IDEs for better debugging and unit testing. Requires additional setup to manage file paths and dependencies. |
|
Code modularization |
Use Simply import functions or variables from other notebooks by executing them inline. Useful for prototyping but can lead to tightly coupled code that’s harder to maintain. Does not support parameter passing or version control. |
%run vs. dbutils.notebook.run()
The %run command allows you to include another notebook within a notebook. You can use %run to modularize your code by putting supporting functions in a separate notebook. You can also use it to concatenate notebooks that implement the steps in an analysis. When you use %run, the called notebook is immediately executed and the functions and variables defined in it become available in the calling notebook.
The dbutils.notebook API complements %run because it lets you pass parameters to and return values from a notebook. This allows you to build complex workflows and pipelines with dependencies. For example, you can get a list of files in a directory and pass the names to another notebook, which is impossible with %run. You can also create if-then-else workflows based on return values.
Unlike %run, the dbutils.notebook.run() method starts a new job to run the notebook.
Like all of the dbutils APIs, these methods are available only in Python and Scala. However, you can use dbutils.notebook.run() to invoke an R notebook.
Use %run to import a notebook
In this example, the first notebook defines a function, reverse, which is available in the second notebook after you use the %run magic to execute shared-code-notebook.

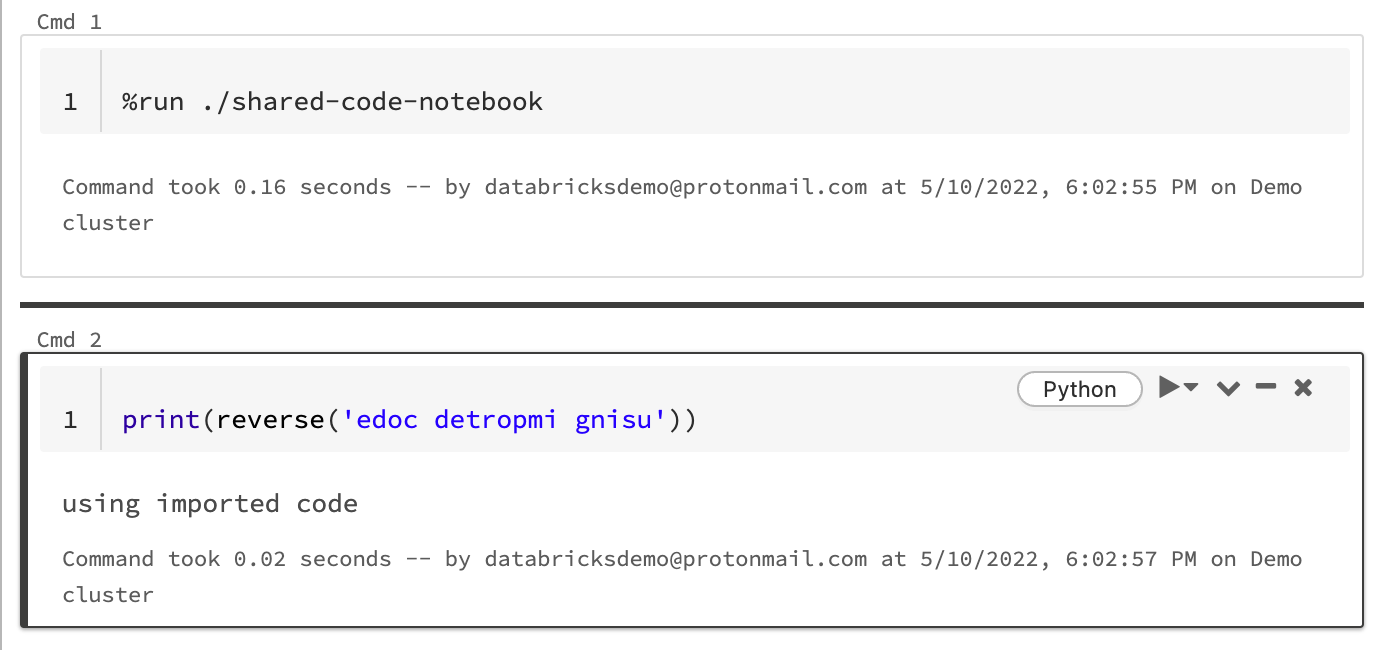
Because both notebooks are in the same directory in the workspace, use the prefix ./ in ./shared-code-notebook to indicate that the path should be resolved relative to the currently running notebook. You can organize notebooks into directories, such as %run ./dir/notebook, or use an absolute path like %run /Users/username@organization.com/directory/notebook.
Note
%runmust be in a cell by itself, because it runs the entire notebook inline.You cannot use
%runto run a Python file andimportthe entities defined in that file into a notebook. To import from a Python file, see Modularize your code using files. Or, package the file into a Python library, create a Databricks library from that Python library, and install the library into the cluster you use to run your notebook.When you use
%runto run a notebook that contains widgets, by default the specified notebook runs with the widget’s default values. You can also pass values to widgets; see Use Databricks widgets with %run.
Use dbutils.notebook.run to start a new job
Run a notebook and return its exit value. The method starts an ephemeral job that runs immediately.
The methods available in the dbutils.notebook API are run and exit. Both parameters and return values must be strings.
run(path: String, timeout_seconds: int, arguments: Map): String
The timeout_seconds parameter controls the timeout of the run (0 means no timeout). The call to
run throws an exception if it doesn’t finish within the specified time. If Databricks is down for more than 10 minutes,
the notebook run fails regardless of timeout_seconds.
The arguments parameter sets widget values of the target notebook. Specifically, if the notebook you are running has a widget
named A, and you pass a key-value pair ("A": "B") as part of the arguments parameter to the run() call,
then retrieving the value of widget A will return "B". You can find the instructions for creating and
working with widgets in the Databricks widgets article.
Note
The
argumentsparameter accepts only Latin characters (ASCII character set). Using non-ASCII characters returns an error.Jobs created using the
dbutils.notebookAPI must complete in 30 days or less.
Pass structured data between notebooks
This section illustrates how to pass structured data between notebooks.
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Handle errors
This section illustrates how to handle errors.
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Run multiple notebooks concurrently
You can run multiple notebooks at the same time by using standard Scala and Python constructs such as Threads (Scala, Python) and Futures (Scala, Python). The example notebooks demonstrate how to use these constructs.
Download the following four notebooks. The notebooks are written in Scala.
Import the notebooks into a single folder in the workspace.
Run the Run concurrently notebook.