Configure pipeline settings for Delta Live Tables
This article has details on configuring pipeline settings for Delta Live Tables. Delta Live Tables has a user interface for configuring and editing pipeline settings. The UI also has an option to display and edit settings in JSON.
Note
You can configure most settings with either the UI or a JSON specification. Some advanced options are only available using the JSON configuration.
Databricks recommends familiarizing yourself with Delta Live Tables settings using the UI. If necessary, you can directly edit the JSON configuration in the workspace. JSON configuration files are also helpful when deploying pipelines to new environments or using the CLI or REST API.
For a complete reference to the Delta Live Tables JSON configuration settings, see Delta Live Tables pipeline configurations.
Choose a product edition
Select the Delta Live Tables product edition with the best features for your pipeline requirements. The following product editions are available:
Coreto run streaming ingest workloads. Select theCoreedition if your pipeline doesn’t require advanced features such as change data capture (CDC) or Delta Live Tables expectations.Proto run streaming ingest and CDC workloads. TheProproduct edition supports all of theCorefeatures, plus support for workloads that require updating tables based on changes in source data.Advancedto run streaming ingest workloads, CDC workloads, and workloads that require expectations. TheAdvancedproduct edition supports the features of theCoreandProeditions, and also supports enforcement of data quality constraints with Delta Live Tables expectations.
You can select the product edition when you create or edit a pipeline. You can choose a different edition for each pipeline. See the Delta Live Tables product page.
Note: If your pipeline includes features not supported by the selected product edition, such as expectations, you will receive an error message explaining the reason for the error. You can then edit the pipeline to select the appropriate edition.
Choose a pipeline mode
You can update your pipeline continuously or with manual triggers based on the pipeline mode. See Continuous vs. triggered pipeline execution.
Select a cluster policy
Users must have permission to deploy compute to configure and update Delta Live Tables pipelines. Workspace admins can configure cluster policies to provide users with access to compute resources for Delta Live Tables. See Define limits on Delta Live Tables pipeline compute.
Note
Cluster policies are optional. Check with your workspace administrator if you lack compute privileges required for Delta Live Tables.
To ensure that cluster policy default values are correctly applied, set the
apply_policy_default_valuesvalue totruein the cluster configurations in your pipeline configuration:{ "clusters": [ { "label": "default", "policy_id": "<policy-id>", "apply_policy_default_values": true } ] }
Configure source code libraries
You can use the file selector in the Delta Live Tables UI to configure the source code defining your pipeline. Pipeline source code is defined in Databricks notebooks or SQL or Python scripts stored in workspace files. When you create or edit your pipeline, you can add one or more notebooks or workspace files or a combination of notebooks and workspace files.
Because Delta Live Tables automatically analyzes dataset dependencies to construct the processing graph for your pipeline, you can add source code libraries in any order.
You can also modify the JSON file to include Delta Live Tables source code defined in SQL and Python scripts stored in workspace files. The following example includes notebooks and workspace files:
{
"name": "Example pipeline 3",
"storage": "dbfs:/pipeline-examples/storage-location/example3",
"libraries": [
{ "notebook": { "path": "/example-notebook_1" } },
{ "notebook": { "path": "/example-notebook_2" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.sql" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.py" } }
]
}
Specify a storage location
You can specify a storage location for a pipeline that publishes to the Hive metastore. The primary motivation for specifying a location is to control the object storage location for data written by your pipeline.
Because all tables, data, checkpoints, and metadata for Delta Live Tables pipelines are fully managed by Delta Live Tables, most interaction with Delta Live Tables datasets happens through tables registered to the Hive metastore or Unity Catalog.
Specify a target schema for pipeline output tables
While optional, you should specify a target to publish tables created by your pipeline anytime you move beyond development and testing for a new pipeline. Publishing a pipeline to a target makes datasets available for querying elsewhere in your Databricks environment. See Publish data from Delta Live Tables to the Hive metastore or Use Unity Catalog with your Delta Live Tables pipelines.
Configure your compute settings
Each Delta Live Tables pipeline has two associated clusters:
The
updatescluster processes pipeline updates.The
maintenancecluster runs daily maintenance tasks.
The configuration used by these clusters is determined by the clusters attribute specified in your pipeline settings.
You can add compute settings that apply to only a specific cluster type by using cluster labels. There are three labels you can use when configuring pipeline clusters:
Note
The cluster label setting can be omitted if you are defining only one cluster configuration. The default label is applied to cluster configurations if no setting for the label is provided. The cluster label setting is required only if you need to customize settings for different cluster types.
The
defaultlabel defines compute settings to apply to both theupdatesandmaintenanceclusters. Applying the same settings to both clusters improves the reliability of maintenance runs by ensuring that required configurations such as data access credentials for a storage location are applied to the maintenance cluster.The
maintenancelabel defines compute settings that apply to only themaintenancecluster. You can also use themaintenancelabel to override settings configured by thedefaultlabel.The
updateslabel defines settings that apply to only theupdatescluster. Use theupdateslabel to configure settings that should not be applied to themaintenancecluster.
Settings defined using the default and updates labels are merged to create the final configuration for the updates cluster. If the same setting is defined using both default and updates labels, the setting defined with the updates label overrides the setting defined with the default label.
The following example defines a Spark configuration parameter that is added only to the configuration for the updates cluster:
{
"clusters": [
{
"label": "default",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
},
{
"label": "updates",
"spark_conf": {
"key": "value"
}
}
]
}
Delta Live Tables has similar options for cluster settings as other compute on Databricks. Like other pipeline settings, you can modify the JSON configuration for clusters to specify options not present in the UI. See Compute.
Note
Because the Delta Live Tables runtime manages the lifecycle of pipeline clusters and runs a custom version of Databricks Runtime, you cannot manually set some cluster settings in a pipeline configuration, such as the Spark version or cluster names. See Cluster attributes that are not user settable.
You can configure Delta Live Tables pipelines to leverage Photon. See What is Photon?.
Select instance types to run a pipeline
By default, Delta Live Tables selects the instance types for the driver and worker nodes that run your pipeline, but you can also manually configure the instance types. For example, you might want to select instance types to improve pipeline performance or address memory issues when running your pipeline. You can configure instance types when you create or edit a pipeline with the REST API, or in the Delta Live Tables UI.
To configure instance types when you create or edit a pipeline in the Delta Live Tables UI:
Click the Settings button.
In the Advanced section of the pipeline settings, in the Worker type and Driver type drop-down menus, select the instance types for the pipeline.
To configure instance types in the pipeline’s JSON settings, click the JSON button and enter the instance type configurations in the cluster configuration:
Note
To avoid assigning unnecessary resources to the maintenance cluster, this example uses the updates label to set the instance types for only the updates cluster. To assign the instance types to both updates and maintenance clusters, use the default label or omit the setting for the label. The default label is applied to pipeline cluster configurations if no setting for the label is provided. See Configure your compute settings.
{
"clusters": [
{
"label": "updates",
"node_type_id": "n1-highmem-16",
"driver_node_type_id": "n1-standard-4",
"..." : "..."
}
]
}
Use autoscaling to increase efficiency and reduce resource usage
Use Enhanced Autoscaling to optimize the cluster utilization of your pipelines. Enhanced Autoscaling adds additional resources only if the system determines those resources will increase pipeline processing speed. Resources are freed when no longer needed, and clusters are shut down as soon as all pipeline updates are complete.
To learn more about Enhanced Autoscaling, including configuration details, see Optimize the cluster utilization of Delta Live Tables pipelines with Enhanced Autoscaling.
Delay compute shutdown
Because a Delta Live Tables cluster automatically shuts down when not in use, referencing a cluster policy that sets autotermination_minutes in your cluster configuration results in an error. To control cluster shutdown behavior, you can use development or production mode or use the pipelines.clusterShutdown.delay setting in the pipeline configuration. The following example sets the pipelines.clusterShutdown.delay value to 60 seconds:
{
"configuration": {
"pipelines.clusterShutdown.delay": "60s"
}
}
When production mode is enabled, the default value for pipelines.clusterShutdown.delay is 0 seconds. When development mode is enabled, the default value is 2 hours.
Create a single node cluster
If you set num_workers to 0 in cluster settings, the cluster is created as a Single Node cluster. Configuring an autoscaling cluster and setting min_workers to 0 and max_workers to 0 also creates a Single Node cluster.
If you configure an autoscaling cluster and set only min_workers to 0, then the cluster is not created as a Single Node cluster. The cluster has at least one active worker at all times until terminated.
An example cluster configuration to create a Single Node cluster in Delta Live Tables:
{
"clusters": [
{
"num_workers": 0
}
]
}
Configure cluster tags
You can use cluster tags to monitor usage for your pipeline clusters. Add cluster tags in the Delta Live Tables UI when you create or edit a pipeline, or by editing the JSON settings for your pipeline clusters.
Cloud storage configuration
To access a bucket in Google Cloud Storage (GCS), you must create a service account with access to that GCS bucket and add that service account to the cluster configurations. For more information about creating a Google Cloud service account, see Connect to Google Cloud Storage. You can add the service account configuration when you create or edit a pipeline with the Delta Live Tables API or in the Delta Live Tables UI:
On the Pipeline details page for your pipeline, click the Settings button. The Pipeline settings page appears.
Click the JSON button.
Enter the service account configuration in the
gcp_attributes.google_service_accountfield in the cluster configuration:
{
"clusters": [
{
"gcp_attributes": {
"google_service_account": "test-gcs-doc@databricks-dev.iam.gserviceaccount.com"
}
}
]
}
Parameterize dataset declarations in Python or SQL
The Python and SQL code that defines your datasets can be parameterized by the pipeline’s settings. Parameterization enables the following use cases:
Separating long paths and other variables from your code.
Reducing the amount of data processed in development or staging environments to speed up testing.
Reusing the same transformation logic to process from multiple data sources.
The following example uses the startDate configuration value to limit the development pipeline to a subset of the input data:
CREATE OR REFRESH MATERIALIZED VIEW customer_events
AS SELECT * FROM sourceTable WHERE date > '${mypipeline.startDate}';
@dlt.table
def customer_events():
start_date = spark.conf.get("mypipeline.startDate")
return read("sourceTable").where(col("date") > start_date)
{
"name": "Data Ingest - DEV",
"configuration": {
"mypipeline.startDate": "2021-01-02"
}
}
{
"name": "Data Ingest - PROD",
"configuration": {
"mypipeline.startDate": "2010-01-02"
}
}
Pipelines trigger interval
You can use pipelines.trigger.interval to control the trigger interval for a flow updating a table or an entire pipeline. Because a triggered pipeline processes each table only once, the pipelines.trigger.interval is used only with continuous pipelines.
Databricks recommends setting pipelines.trigger.interval on individual tables because of different defaults for streaming versus batch queries. Set the value on a pipeline only when your processing requires controlling updates for the entire pipeline graph.
You set pipelines.trigger.interval on a table using spark_conf in Python, or SET in SQL:
@dlt.table(
spark_conf={"pipelines.trigger.interval" : "10 seconds"}
)
def <function-name>():
return (<query>)
SET pipelines.trigger.interval=10 seconds;
CREATE OR REFRESH MATERIALIZED VIEW TABLE_NAME
AS SELECT ...
To set pipelines.trigger.interval on a pipeline, add it to the configuration object in the pipeline settings:
{
"configuration": {
"pipelines.trigger.interval": "10 seconds"
}
}
Allow non-admin users to view the driver logs from a Unity Catalog-enabled pipeline
By default, only the pipeline owner and workspace admins have permission to view the driver logs from the cluster that runs a Unity Catalog-enabled pipeline. You can enable access to the driver logs for any user with CAN MANAGE, CAN VIEW, or CAN RUN permissions by adding the following Spark configuration parameter to the configuration object in the pipeline settings:
{
"configuration": {
"spark.databricks.acl.needAdminPermissionToViewLogs": "false"
}
}
Add email notifications for pipeline events
You can configure one or more email addresses to receive notifications when the following occurs:
A pipeline update completes successfully.
A pipeline update fails, either with a retryable or a non-retryable error. Select this option to receive a notification for all pipeline failures.
A pipeline update fails with a non-retryable (fatal) error. Select this option to receive a notification only when a non-retryable error occurs.
A single data flow fails.
To configure email notifications when you create or edit a pipeline:
Click Add notification.
Enter one or more email addresses to receive notifications.
Click the check box for each notification type to send to the configured email addresses.
Click Add notification.
Control tombstone management for SCD type 1 queries
The following settings can be used to control the behavior of tombstone management for DELETE events during SCD type 1 processing:
pipelines.applyChanges.tombstoneGCThresholdInSeconds: Set this value to match the highest expected interval, in seconds, between out-of-order data. The default is 172800 seconds (2 days).pipelines.applyChanges.tombstoneGCFrequencyInSeconds: This setting controls how frequently, in seconds, tombstones are checked for cleanup. The default is 1800 seconds (30 minutes).
See The APPLY CHANGES APIs: Simplify change data capture with Delta Live Tables.
Configure pipeline permissions
You must have the CAN MANAGE or IS OWNER permission on the pipeline in order to manage permissions on it.
In the sidebar, click Delta Live Tables.
Select the name of a pipeline.
Click the kebab menu
 , and select Permissions.
, and select Permissions.In Permissions Settings, select the Select User, Group or Service Principal… drop-down menu and then select a user, group, or service principal.
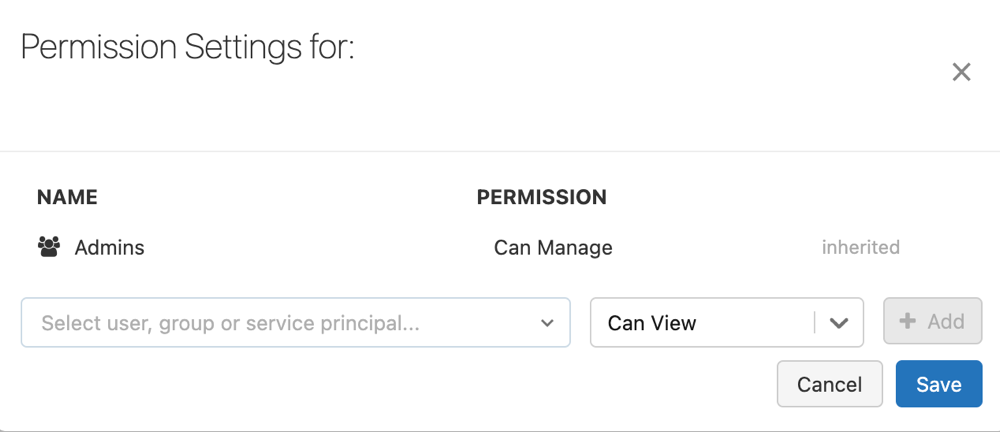
Select a permission from the permission drop-down menu.
Click Add.
Click Save.
Enable RocksDB state store for Delta Live Tables
You can enable RocksDB-based state management by setting the following configuration before deploying a pipeline:
{
"configuration": {
"spark.sql.streaming.stateStore.providerClass": "com.databricks.sql.streaming.state.RocksDBStateStoreProvider"
}
}
To learn more about the RocksDB state store, including configuration recommendations for RocksDB, see Configure RocksDB state store on Databricks.