What is RAG?
Preview
This feature is in Public Preview.
RAG comprises a set of tools on Databricks designed to help developers build, deploy, and evaluate production-quality agents like Retrieval Augmented Generation (RAG) applications.
This article covers what RAG is and the benefits of developing RAG applications on Databricks.
What is RAG?
RAG is a generative AI design technique that enhances large language models (LLM) with external knowledge. This technique improves LLMs in the following ways:
Proprietary knowledge: RAG can include proprietary information not initially used to train the LLM, such as memos, emails, and documents to answer domain-specific questions.
Up-to-date information: A RAG application can supply the LLM with information from updated data sources.
Citing sources: RAG enables LLMs to cite specific sources, allowing users to verify the factual accuracy of responses.
Data security and access control lists (ACL): The retrieval step can be designed to selectively retrieve personal or proprietary information based on user credentials.
Compound AI systems
A RAG application is an example of a compound AI system: it expands on the language capabilities of the LLM by combining it with other tools and procedures.
In the simplest form, a RAG application does the following:
Retrieval: The user’s request is used to query an outside data store, such as a vector store, a text keyword search, or a SQL database. The goal is to get supporting data for the LLM’s response.
Augmentation: The retrieved data is combined with the user’s request, often using a template with additional formatting and instructions, to create a prompt.
Generation: The prompt is passed to the LLM, which then generates a response to the query.
RAG and gen AI use cases
The following table lists a few RAG use cases.
Use case |
Description |
|---|---|
Q&A chatbots |
Use LLMs with chatbots to derive accurate answers from company documents and knowledge bases. Chatbots can automate customer support and follow up on website leads to quickly answer questions and resolve issues. |
Search augmentation |
Use LLMs with search engines to augment search results with LLM-generated answers, making it easier for users to find the information they need. |
Knowledge engine |
Use company data, like HR and compliance documents, as context for LLMs to let employees easily get answers to questions about benefits, policies, security, and compliance. |
Unstructured vs. structured RAG data
RAG architecture can work with either unstructured or structured supporting data. The data you use with RAG depends on your use case.
Unstructured data: Data without a specific structure or organization. Documents that include text and images or multimedia content such as audio or videos.
PDFs
Google/Office documents
Wikis
Images
Videos
Structured data: Tabular data arranged in rows and columns with a specific schema, such as tables in a database.
Customer records in a BI or Data Warehouse system
Transaction data from a SQL database
Data from application APIs (e.g., SAP, Salesforce, etc.)
The following sections describe a RAG application for unstructured data.
RAG data pipeline
The RAG data pipeline pre-processes and indexes documents for fast and accurate retrieval.
The diagram below shows a sample data pipeline for an unstructured dataset using a semantic search algorithm. Databricks Workflows orchestrate each step.
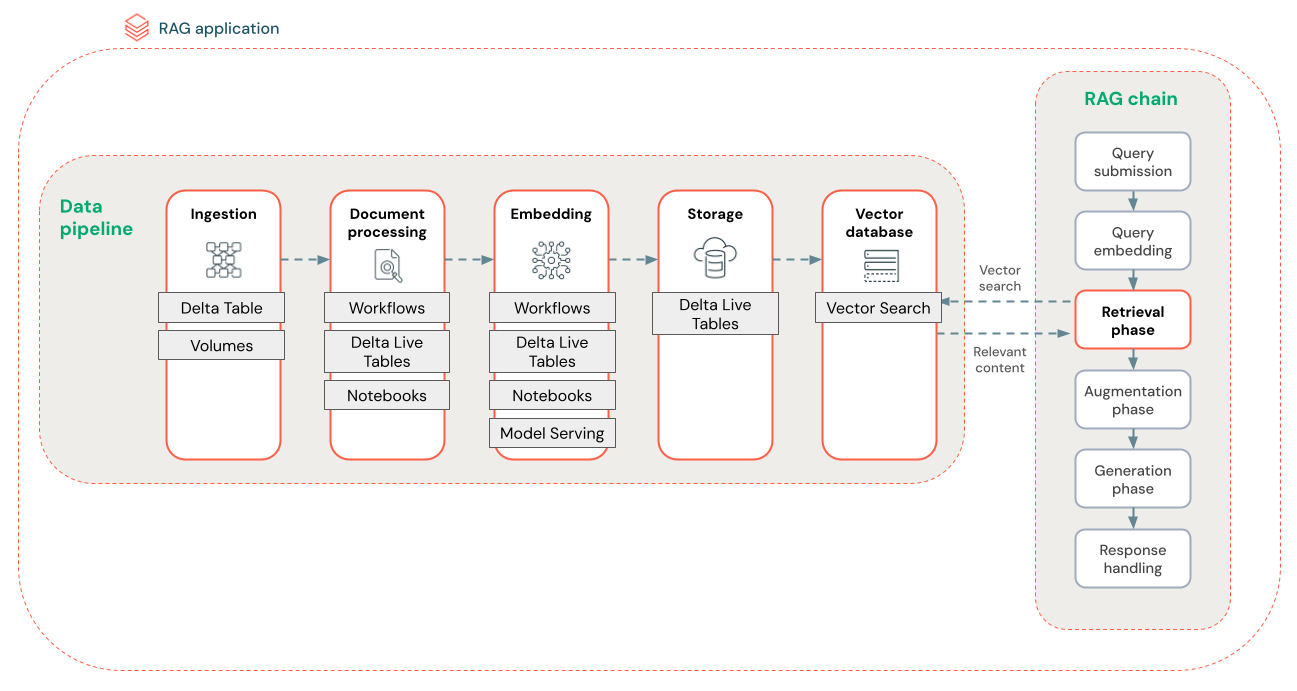
Data ingestion - Ingest data from your proprietary source. Store this data in a Delta table or Unity Catalog Volume.
Document processing: You can perform these tasks using Databricks Workflows, Databricks Notebooks, and Delta Live Tables.
Parse raw documents: Transform the raw data into a usable format. For example, extracting the text, tables, and images from a collection of PDFs or using optical character recognition techniques to extract text from images.
Extract metadata: Extract document metadata such as document titles, page numbers, and URLs to help the retrieval step query more accurately.
Chunk documents: Split the data into chunks that fit into the LLM context window. Retrieving these focused chunks, rather than entire documents, gives the LLM more targeted content to generate responses.
Embedding chunks - An embedding model consumes the chunks to create numerical representations of the information called vector embeddings. Vectors represent the semantic meaning of the text, not just surface-level keywords. In this scenario, you compute the embeddings and use Model Serving to serve the embedding model.
Embedding storage - Store the vector embeddings and the chunk’s text in a Delta table synced with Vector Search.
Vector database - As part of Vector Search, embeddings and metadata are indexed and stored in a vector database for easy querying by the RAG agent. When a user makes a query, their request is embedded into a vector. The database then uses the vector index to find and return the most similar chunks.
Each step involves engineering decisions that impact the RAG application’s quality. For example, choosing the right chunk size in step (3) ensures the LLM receives specific yet contextualized information, while selecting an appropriate embedding model in step (4) determines the accuracy of the chunks returned during retrieval.
Databricks Vector Search
Computing similarity is often computationally expensive, but vector indexes like Databricks Vector Search optimize this by efficiently organizing embeddings. Vector searches quickly rank the most relevant results without comparing each embedding to the user’s query individually.
Vector Search automatically syncs new embeddings added to your Delta table and updates the Vector Search index.
What is a RAG agent?
A Retrieval Augmented Generation (RAG) agent is a key part of a RAG application that enhances the capabilities of large language models (LLMs) by integrating external data retrieval. The RAG agent processes user queries, retrieves relevant data from a vector database, and passes this data to an LLM to generate a response.
Tools like LangChain or Pyfunc link these steps by connecting their inputs and outputs.
The diagram below shows a RAG agent for a chatbot and the Databricks features used to build each agent.
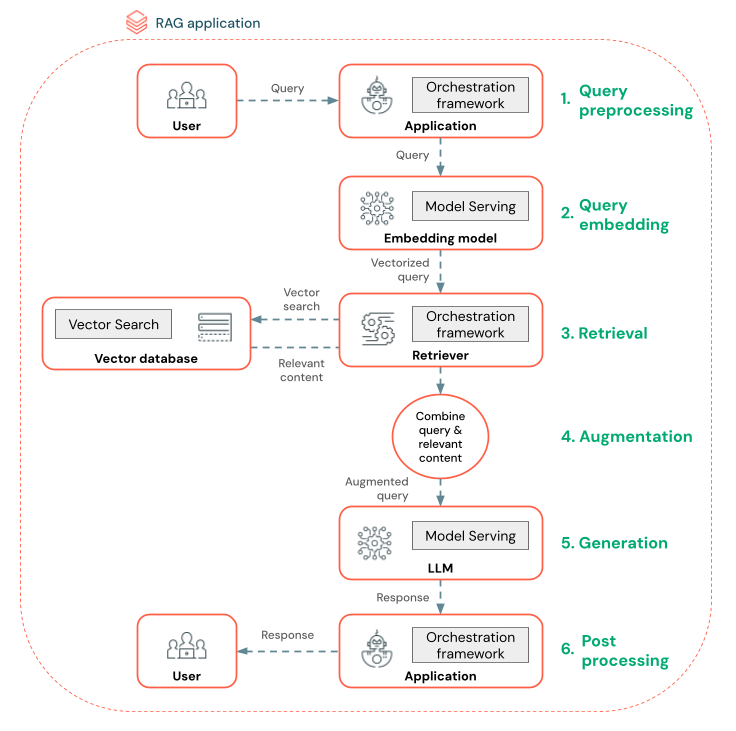
Query preprocessing - A user submits a query, which is then preprocessed to make it suitable for querying the vector database. This may involve placing the request in a template or extracting keywords.
Query vectorization - Use Model Serving to embed the request using the same embedding model used to embed the chunks in the data pipeline. These embeddings enable comparison of the semantic similarity between the request and the preprocessed chunks.
Retrieval phase - The retriever, an application responsible for fetching relevant information, takes the vectorized query and performs a vector similarity search using Vector Search. The most relevant data chunks are ranked and retrieved based on their similarity to the query.
Prompt augmentation - The retriever combines the retrieved data chunks with the original query to provide additional context to the LLM. The prompt is carefully structured to ensure that the LLM understands the context of the query. Often, the LLM has a template for formatting the response. This process of adjusting the prompt is known as prompt engineering.
LLM Generation phase - The LLM generates a response using the augmented query enriched by the retrieval results. The LLM can be a custom model or a foundation model.
Post-processing - The LLM’s response may be processed to apply additional business logic, add citations, or otherwise refine the generated text based on predefined rules or constraints
Various guardrails may be applied throughout this process to ensure compliance with enterprise policies. This might involve filtering for appropriate requests, checking user permissions before accessing data sources, and using content moderation techniques on the generated responses.
Evaluation & monitoring
Evaluation and monitoring help determine if your RAG application meets your quality, cost, and latency requirements. Evaluation occurs during development, while monitoring happens once the application is deployed to production.
RAG over unstructured data has many components that impact quality. For example, data formatting changes can influence the retrieved chunks and the LLM’s ability to generate relevant responses. So, it’s important to evaluate individual components in addition to the overall application.