O que é RAG?
Visualização
Esse recurso está em Prévia Pública.
O RAG é composto por um conjunto de ferramentas no site Databricks criado para ajudar os desenvolvedores a criar, implantar e avaliar agentes com qualidade de produção, como os aplicativos Retrieval Augmented Generation (RAG).
Este artigo aborda o que é RAG e os benefícios de desenvolver aplicativos RAG em Databricks.
O que é RAG?
O RAG é uma técnica de design de IA generativa que aprimora modelos de linguagem grandes (LLM) com conhecimento externo. Essa técnica melhora os LLMs das seguintes maneiras:
Conhecimento proprietário: O RAG pode incluir informações proprietárias não usadas inicialmente para ensinar o LLM, como memorandos, e-mails e documentos para responder a perguntas específicas do domínio.
Informações atualizadas: Um aplicativo RAG pode fornecer ao site LLM informações de fontes de dados atualizadas.
Citação de fontes: O RAG permite que os LLMs citem fontes específicas, permitindo que os usuários verifiquem a precisão factual das respostas.
Segurança de dados e listas de controle de acesso (ACL): A recuperação pode ser projetada para recuperar seletivamente informações pessoais ou proprietárias com base nas credenciais do usuário.
Sistemas compostos de IA
Um aplicativo RAG é um exemplo de um sistema de IA composto: ele expande os recursos de linguagem do LLM combinando-o com outras ferramentas e procedimentos.
Na forma mais simples, um aplicativo RAG faz o seguinte:
Recuperação: A solicitação do usuário é usada para consultar um armazenamento de dados externo, como um armazenamento de vetores, uma pesquisa de texto por palavra-chave ou um banco de dados SQL. O objetivo é obter dados de apoio para a resposta do LLM.
Aumento: Os dados recuperados são combinados com a solicitação do usuário, geralmente usando um padrão com formatação e instruções adicionais, para criar um prompt.
Geração: O prompt é passado para o LLM, que gera uma resposta à consulta.
Casos de uso de RAG e IA geral
A tabela a seguir lista alguns casos de uso do RAG.
Caso de uso |
Descrição |
|---|---|
Q&A chatbots |
Use LLMs com chatbots para obter respostas precisas de documentos e bases de conhecimento da empresa. Os chatbots podem automatizar o suporte ao cliente e acompanhar os leads do site para responder rapidamente a perguntas e resolver problemas. |
Aumento da pesquisa |
Use LLMs com mecanismos de pesquisa para aumentar os resultados da pesquisa com respostas geradas pelo site LLM, facilitando para os usuários encontrarem as informações de que precisam. |
Mecanismo de conhecimento |
Use os dados da empresa, como documentos de RH e compliance, como contexto para os LLMs para permitir que os funcionários obtenham facilmente respostas a perguntas sobre benefícios, políticas, segurança e compliance. |
Dados RAG não estruturados vs. estruturados
A arquitetura RAG pode trabalhar com dados de suporte não estruturados ou estruturados. Os dados que o senhor usa com o RAG dependem do seu caso de uso.
Dados não estruturados: Dados sem uma estrutura ou organização específica. Documentos que incluem texto e imagens ou conteúdo multimídia, como áudio ou vídeos.
PDFs
Documentos do Google/Office
Wikis
Imagens
Vídeos
Dados estruturados: Dados tabulares organizados em linhas e colunas com um esquema específico, como tabelas em um banco de dados.
Registros de clientes em um sistema BI ou data warehouse
Dados de transação de um banco de dados SQL
Dados de APIs de aplicativos (por exemplo, SAP, Salesforce, etc.)
As seções a seguir descrevem um aplicativo RAG para dados não estruturados.
RAG pipeline de dados
O pipeline de dados do RAG pré-processa e indexa documentos para uma recuperação rápida e precisa.
O diagrama abaixo mostra um exemplo de pipeline de dados para um dataset não estruturado usando um algoritmo de pesquisa semântica. Databricks Workflows orquestrar cada passo.
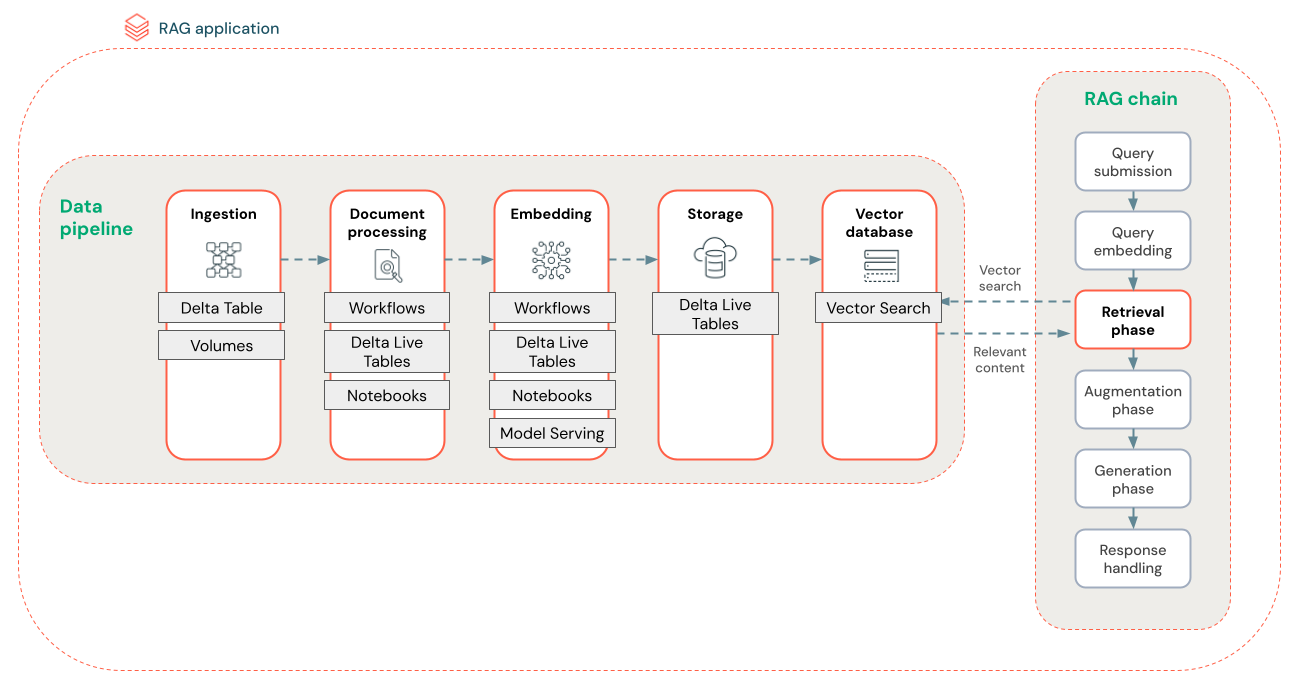
ingestão de dados - ingestão de dados de sua fonte proprietária. Armazene esses dados em uma tabela Delta ou no Unity Catalog Volume.
Processamento de documentos: O senhor pode realizar essas tarefas usando Databricks Workflows, Databricks Notebook e Delta Live Tables.
Analisar documentos brutos: Transformar os dados brutos em um formato utilizável. Por exemplo, extrair o texto, as tabelas e as imagens de uma coleção de PDFs ou usar técnicas de reconhecimento óptico de caracteres para extrair texto de imagens.
Extrair metadados: Extraia metadados de documentos, como títulos de documentos, números de páginas e URLs, para ajudar a recuperar a consulta com mais precisão.
Agrupar documentos: Dividir os dados em partes que se encaixam na janela de contexto do LLM. A recuperação desses blocos focados, em vez de documentos inteiros, oferece ao LLM um conteúdo mais direcionado para gerar respostas.
Incorporação de pedaços - Um modelo de incorporação consome os pedaços para criar representações numéricas das informações chamadas de incorporação de vetores. Os vetores representam o significado semântico do texto, não apenas palavras-chave de nível superficial. Nesse cenário, o senhor compute os embeddings e usa o servindo modelo para servir o modelo de embedding.
Armazenamento de incorporação - Armazene as incorporações de vetores e o texto do bloco em uma tabela Delta sincronizada com o Vector Search.
Banco de dados vet orial - Como parte do Vector Search, os embeddings e os metadados são indexados e armazenados em um banco de dados vetorial para facilitar a consulta pelo agente RAG. Quando um usuário faz uma consulta, sua solicitação é incorporada a um vetor. Em seguida, o banco de dados usa o índice vetorial para localizar e retornar os blocos mais semelhantes.
Cada passo envolve decisões de engenharia que afetam a qualidade do aplicativo RAG. Por exemplo, a escolha do tamanho correto do bloco no passo (3) garante que o site LLM receba informações específicas e contextualizadas, enquanto a seleção de um modelo de incorporação adequado no passo (4) determina a precisão dos blocos retornados durante a recuperação.
Pesquisa vetorial da Databricks
O cálculo da similaridade costuma ser caro do ponto de vista computacional, mas os índices vetoriais, como o Databricks Vector Search, otimizam isso organizando eficientemente os embeddings. As pesquisas vetoriais classificam rapidamente os resultados mais relevantes sem comparar cada incorporação com a consulta do usuário individualmente.
O Vector Search sincroniza automaticamente os novos embeddings adicionados à sua tabela Delta e atualiza o índice do Vector Search.
O que é um agente RAG?
Um agente Retrieval Augmented Generation (RAG) é uma key parte de um aplicativo RAG que aprimora os recursos de modelos de linguagem grandes (LLMs) integrando a recuperação de dados externos. O agente RAG processa as consultas do usuário, recupera os dados relevantes de um banco de dados vetorial e passa esses dados para um LLM para gerar uma resposta.
Ferramentas como LangChain ou Pyfunc vinculam esses passos conectando suas entradas e saídas.
O diagrama abaixo mostra um agente RAG para um chatbot e o recurso Databricks usado para criar cada agente.
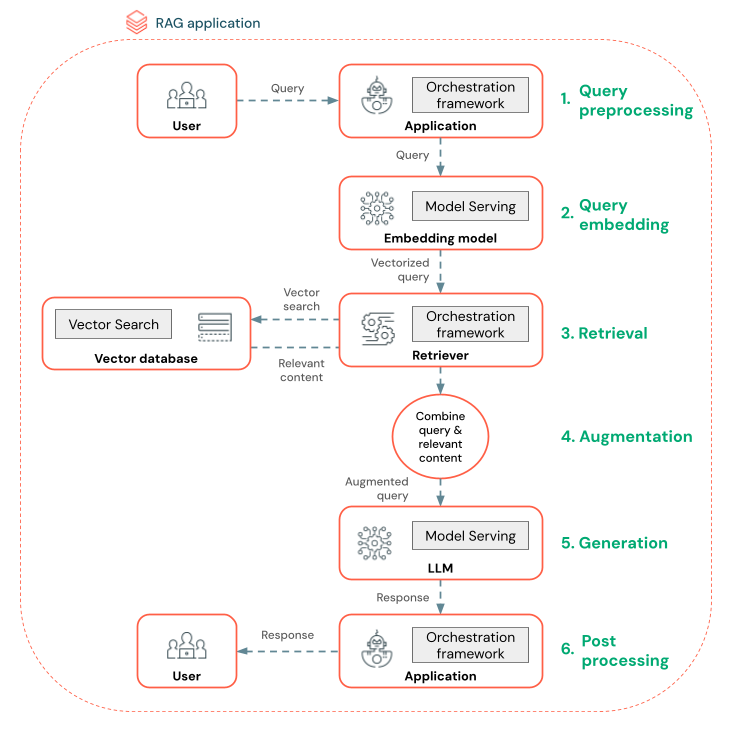
Pré-processamento de consultas - Um usuário envia uma consulta, que é pré-processada para torná-la adequada para a consulta ao banco de dados de vetores. Isso pode envolver a colocação da solicitação em um padrão ou a extração de palavras-chave.
Vetorização de consultas - Use o modelo servindo para incorporar a solicitação usando o mesmo modelo de incorporação usado para incorporar os pedaços no pipeline de dados. Essas incorporações permitem a comparação da similaridade semântica entre a solicitação e os blocos pré-processados.
Fase de recuperação - O recuperador, um aplicativo responsável por buscar informações relevantes, recebe a consulta vetorizada e executa uma pesquisa de similaridade vetorial usando o Vector Search. Os blocos de dados mais relevantes são classificados e recuperados com base em sua similaridade com a consulta.
Aumento do prompt - O recuperador combina os blocos de dados recuperados com a consulta original para fornecer contexto adicional ao LLM. O prompt é cuidadosamente estruturado para garantir que o LLM compreenda o contexto da consulta. Muitas vezes, o site LLM tem um padrão para formatar a resposta. Esse processo de ajuste do prompt é conhecido como engenharia de prompt.
Fase de geração do LLM - O LLM gera uma resposta usando a consulta aumentada enriquecida pelos resultados da recuperação. O LLM pode ser um modelo personalizado ou um modelo básico.
Pós-processamento - A resposta do LLM pode ser processada para aplicar lógica comercial adicional, adicionar citações ou refinar o texto gerado com base em regras ou restrições predefinidas
Várias proteções podem ser aplicadas ao longo desse processo para garantir compliance as políticas da empresa. Isso pode envolver a filtragem de solicitações apropriadas, a verificação das permissões do usuário antes de acessar a fonte de dados e o uso de técnicas de moderação de conteúdo nas respostas geradas.
Avaliação & monitoramento
A avaliação e o monitoramento ajudam a determinar se o aplicativo RAG atende aos requisitos de qualidade, custo e latência. A avaliação ocorre durante o desenvolvimento, enquanto o monitoramento acontece quando o aplicativo é implantado na produção.
O RAG sobre dados não estruturados tem muitos componentes que afetam a qualidade. Por exemplo, as alterações na formatação dos dados podem influenciar os blocos recuperados e a capacidade do LLM de gerar respostas relevantes. Portanto, é importante avaliar os componentes individuais, além do aplicativo como um todo.