IA e machine learning em Databricks
Este artigo descreve as ferramentas que o site Mosaic AI (anteriormente Databricks Machine Learning) fornece para ajudá-lo a criar sistemas IA e ML. O diagrama mostra como vários produtos da plataforma Databricks ajudam o senhor a implementar seu fluxo de trabalho de ponta a ponta para criar e implantar sistemas de IA e ML
IA generativa na Databricks
O Mosaic AI unifica o ciclo de vida da IA, desde a coleta e a preparação de dados, passando pelo desenvolvimento de modelos e LLMOps, até o atendimento e o monitoramento. Os recursos a seguir são especificamente otimizados para facilitar o desenvolvimento de aplicativos de AI generativa:
Unity Catalog para governança, descoberta, controle de versão e controle de acesso para dados, recursos, modelos e funções.
MLflow para acompanhamento de desenvolvimento de modelos e avaliação de LLMs.
Mosaic AI Gateway para governar e monitorar o acesso aos modelos generativos AI suportados e seu endpoint de modelo de serviço associado.
Mosaic AI Model Serving para a implantação de LLMs. Você pode configurar um endpoint de servindo modelo especificamente para acessar modelos de IA generativa:
Modelos de terceiros hospedados fora do Databricks. Consulte Modelos externos no Mosaic AI Model Serving.
O que é IA generativa?
A IA generativa é um tipo de inteligência artificial focada na capacidade dos computadores de usar modelos para criar conteúdo como imagens, texto, código e dados sintéticos.
Os aplicativos de IA generativa são criados com base em modelos de IA generativa: grandes modelos de linguagem (LLMs) e modelos básicos.
Os LLMs são modelos de aprendizagem profunda que consomem e ensinam sobre conjuntos de dados maciços para se destacar na tarefa de processamento de linguagem. Eles criam novas combinações de texto que imitam a linguagem natural com base em seus dados de treinamento.
Os modelos generativos AI ou modelos de base são modelos ML grandes pré-treinados com a intenção de serem ajustados para tarefas mais específicas de compreensão e geração de linguagem. Esses modelos são usados para discernir padrões nos dados de entrada.
Após esses modelos completarem seus processos de aprendizado, juntos eles geram saídas estatisticamente prováveis quando solicitados e podem ser utilizados para realizar várias tarefas, incluindo:
Geração de imagens com base em imagens existentes ou utilizando o estilo de uma imagem para modificar ou criar uma nova.
Tarefas de fala, como transcrição, tradução, geração de perguntas/respostas e interpretação da intenção ou significado do texto.
Importante
Embora muitos LLMs ou outros modelos de IA generativa tenham salvaguardas, ainda podem gerar informações prejudiciais ou imprecisas.
A IA generativa tem os seguintes padrões de design:
Engenharia de prompts: elaboração de prompts especializados para orientar o comportamento do LLM
Geração Aumentada por Recuperação (RAG): Combinar um LLM com recuperação de conhecimento externo
Ajuste fino: adaptando um LLM pré-treinado a conjuntos de dados ou domínios específicos
Pré-treinamento: treinando um LLM do zero
Aprendizado de máquina no Databricks
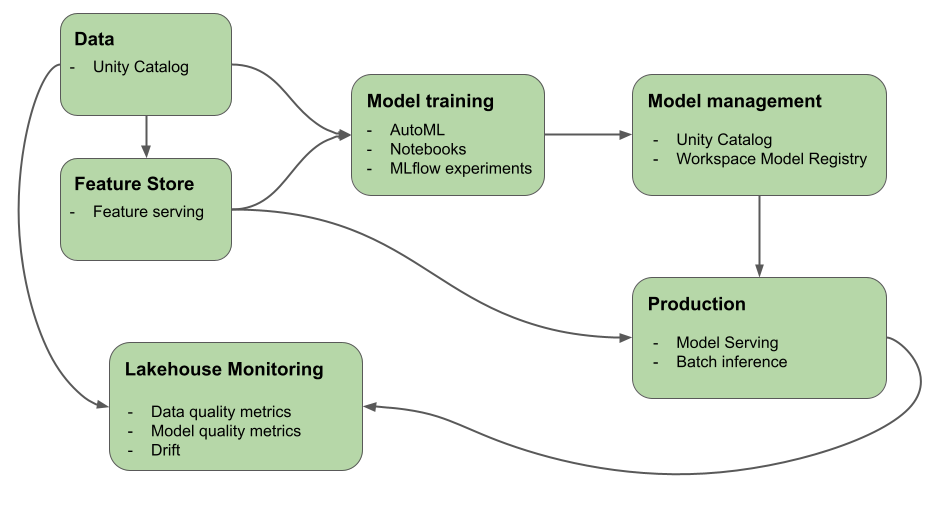
Com o Mosaic AI, uma única plataforma atende a todos os passos do desenvolvimento e da implementação do ML, desde dados brutos até tabelas de inferência que salvam todas as solicitações e respostas de um modelo atendido. data scientistsO senhor pode usar o mesmo conjunto de ferramentas e uma única fonte de verdade para os dados, os engenheiros de dados, os engenheiros do ML e o DevOps.
O Mosaic AI unifica a camada de dados e a plataforma de ML. Todos os dados ativos e artefatos, como modelos e funções, podem ser descobertos e controlados em um único catálogo. O uso de uma única plataforma para dados e modelos possibilita o rastreamento da linhagem, desde os dados brutos até o modelo de produção. O monitoramento integrado de dados e modelos salva as métricas de qualidade em tabelas que também são armazenadas na plataforma, facilitando a identificação da causa raiz dos problemas de desempenho do modelo. Para obter mais informações sobre como Databricks suporta o ciclo de vida completo de ML e MLOps, consulte MLOps fluxo de trabalho em Databricks e MLOps Stacks: modelar o processo de desenvolvimento como código.
Alguns dos key componentes da plataforma de inteligência de dados são:
Tarefas |
Componente |
|---|---|
Administrar e gerenciar dados, recursos, modelos e funções. Além disso, descoberta, controle de versão e linhagem. |
|
desenvolvimento e gerenciamento de recursos |
|
Modelos de ensino |
|
Acompanhar o desenvolvimento do modelo |
|
Servir modelos personalizados |
|
Criar um fluxo de trabalho automatizado e um pipeline ETL pronto para produção |
|
Integração do Git |
aprendizagem profunda na Databricks
Configurar a infraestrutura para aplicativos de aprendizagem profunda pode ser difícil. Databricks Runtime O Machine Learning cuida disso para o senhor, com o site clusters que tem versões compatíveis integradas da biblioteca profunda de aprendizagem mais comum, como TensorFlow, PyTorch e Keras.
Databricks Runtime ML clusters também incluem suporte pré-configurado para GPU com drivers e biblioteca de suporte. Ele também oferece suporte a bibliotecas como a Ray para paralelizar o processamento compute para dimensionar o fluxo de trabalho ML e os aplicativos ML.
Para aplicativos machine learning, a Databricks recomenda o uso de um cluster executando Databricks Runtime para Machine Learning. Consulte Criar um cluster usando o Databricks Runtime ML.
Para começar a usar aprendizagem profunda no Databricks, consulte: