Databricksでの AI と機械学習
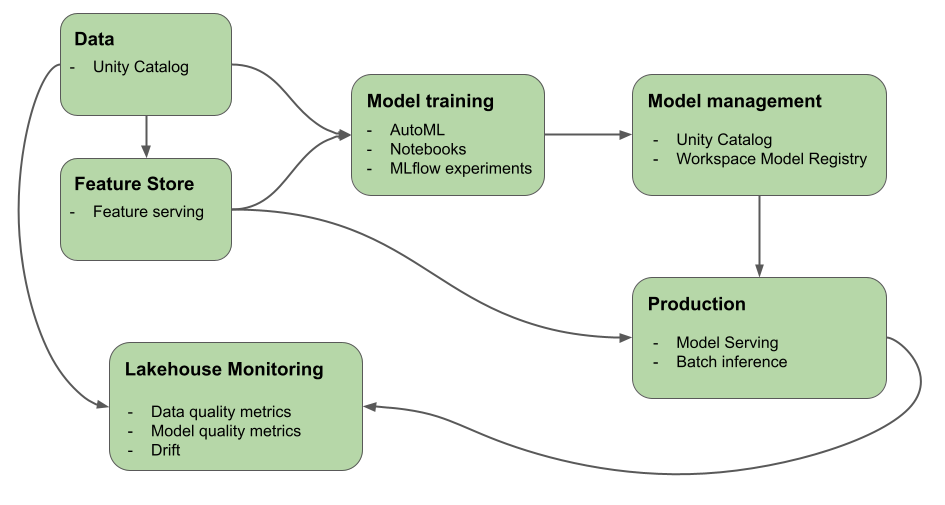
この記事では、Mosaic AI (旧称 Databricks Machine Learning) が提供する、AI システムと ML システムの構築に役立つツールについて説明します。 この図は、Databricks プラットフォーム上のさまざまな製品が、AI および ML システムの構築とデプロイのためのエンドツーエンドのワークフローの実装にどのように役立つかを示しています
Databricksにおける生成AI
Mosaic AI は、データの収集と準備から、モデル開発とLLMOps、提供とモニタリングまで、 AI ライフサイクルを統合します。 次の機能は、生成AI アプリケーションの開発を容易にするために特に最適化されています。
Unity Catalogによりデータ、機能、モデル、および関数のガバナンス、発見、バージョン管理、およびアクセス制御をすることができます。
Mosaic AI Gateway、サポートされている生成AIモデルとそれに関連するモデルサービングエンドポイントへの管理およびモニタリングアクセス用です。
Mosaic AI Model Serving:LLM のデプロイを行います。生成 AI モデルへのアクセスのために、モデルサービングエンドポイントを特別に構成することができます:
Databricks の外部でホストされているサードパーティモデル。「Mosaic AI Model Serving の外部モデル」をご覧ください。
生成AI とは
生成AIは、コンピューターがモデルを使用して画像、テキスト、コード、合成データなどのコンテンツを作成する機能に焦点を当てた人工知能の一種です。
生成AIアプリケーションは、生成AIモデル、つまり大規模言語モデル(LLM)と基盤モデルの上に構築されています。
LLMは 、言語処理タスクに秀でるために、膨大なデータセットを消費してトレーニングするディープラーニングモデルです。 彼らは、トレーニングデータに基づいて自然言語を模倣するテキストの新しい組み合わせを作成します。
生成AI モデルまたは基盤モデルは 、より具体的な言語理解と生成タスクのためにファインチューニングすることを意図して事前にトレーニングされた大規模な ML モデルです。 これらのモデルは、入力データ内のパターンを識別するために使用されます。
学習プロセスを完了した後、プロンプトを入力すると、これらのモデルは集合的に動作し、統計的に確率の高い出力を生成します。これにより、次のようなさまざまなタスクを実行できます。
既存の画像に基づいて画像を生成したり、1つの画像のスタイルを利用して画像を変更したり新しい画像を作成したりします。
テープ起こし、翻訳、質問/回答生成、テキストの意図や意味の解釈などの音声タスクを遂行します。
重要
多くのLLMやその他の生成AIモデルは安全装置を備えていますが、それでも有害な情報や不正確な情報が生成される可能性があります。
生成AIには以下のような設計パターンがあります。
プロンプトエンジニアリング:LLMの動作を導く専門的なプロンプトの作成
検索拡張生成(RAG):LLMと外部ナレッジ検索の組み合わせ
ファインチューニング:事前トレーニングされたLLMを特定のデータセットやドメインに適応
事前学習:ゼロからのLLMトレーニング
Databricksにおける機械学習
Mosaic AIを使用すると、生データから、提供されたモデルのすべてのリクエストとレスポンスを保存する推論テーブルまで、MLの開発とデプロイのすべてのステップを単一のプラットフォームで処理できます。 data scientists、データエンジニア、 ML エンジニア、および DevOps は、データの同じツールセットと単一の真実のソースを使用して、それぞれの仕事をすることができます。
Mosaic AIは、データレイヤーとMLプラットフォームを統合します。 すべてのデータ資産と成果物 (モデルや関数など) は、1 つのカタログで検出および管理できます。 データとモデルを一元管理することで、生データから本番運用モデルまでのリネージの追跡が可能になります。 組み込み Data and Model モニタリング は、プラットフォームにも保存されるテーブルに品質メトリクスを保存するため、モデルのパフォーマンス問題の根本原因を簡単に特定できます。 DatabricksMLが ライフサイクルとMLOps 全体をサポートする方法の詳細については、「MLOps スタックとDatabricks MLOpsスタック でのワークフロー : コードとしてのモデル開発プロセス 」を参照してください。
データインテリジェンスプラットフォームの主要なコンポーネントには、次のようなものがあります。
タスク |
コンポーネント |
|---|---|
データ、機能、モデル、機能を管理および管理します。 検出、バージョン管理、リネージも行います。 |
|
機能の開発と管理 |
|
モデルのトレーニング |
|
モデル開発の追跡 |
|
カスタムモデルを提供する |
|
自動化されたワークフローと本番運用対応のETLパイプラインを構築する |
|
Git連携 |
Databricks でのディープラーニング
ディープラーニング・アプリケーション用のインフラストラクチャの構成は、困難な場合があります。 Databricks Runtime for Machine Learning は、最も一般的なディープラーニング ライブラリ (TensorFlow、PyTorch、Kerasなど) の組み込み互換バージョンを持つクラスターを使用して、それを処理します。
Databricks Runtime ML クラスターには、ドライバーとサポート ライブラリを使用した事前構成済みの GPU サポートも含まれています。 また、Ray のようなライブラリをサポートしており、ワークフローやMLアプリケーションのスケーリングのためにコンピュート処理ML並列化します。
機械学習アプリケーションの場合、Databricks では、Databricks Runtime for Machine Learning を実行しているクラスターを使用することをお勧めします。 「Databricks Runtime ML を使用してクラスターを作成する」を参照してください。
Databricksでディープラーニングを開始するには、以下を参照してください。