Databricks上のファイルを操作する
Databricks 、次の場所にあるファイルを操作するための複数のユーティリティとAPIsあります。
Unity Catalogボリューム
ワークスペースファイル
クラウドオブジェクトストレージ
DBFS マウントと DBFS ルート
クラスターのドライバーノードに接続された一時ストレージ
この記事では、次のツールでこれらの場所にあるファイルを操作する例を示します。
Apache Spark
Spark SQL と Databricks SQL
Databricks ファイル システム ユーティリティ (
dbutils.fsまたは%fs)Databricks CLI
Databricks REST API
Bash シェル コマンド (
%sh)ノートブック スコープのライブラリは次を使用してインストールされます
%pippandas
OSS Python ファイル管理および処理ユーティリティ
重要
FUSE データ アクセスを必要とするファイル操作では、URI を使用してクラウド オブジェクト ストレージに直接アクセスすることはできません。 Databricks では、Unity Catalog ボリュームを使用して FUSE のこれらの場所へのアクセスを構成することをお勧めします。
Scala Unity Catalogと共有アクセス モードで構成されたコンピュート上のUnity Catalogボリュームとワークスペース ファイルの FUSE をサポートします。 Databricks RuntimeScalaUnity CatalogScalaシングルScala ユーザー アクセス モードおよび 14.3 以降で構成されたコンピュートでは、 、 コマンド などの から発生するサブプロセスを除き、 ボリュームおよびワークスペース ファイルの FUSE"cat /Volumes/path/to/file".!! をサポートします。
Spark およびその他の JVM プロセスは、Unity Catalog をサポートするリーダーとライターを使用してのみ、Unity Catalog ボリュームまたはワークスペース ファイルにアクセスできます。 たとえば、JAR SparkPySpark構成で ファイルを依存関係として指定したり、カスタムデータソース 使用することはできません。ボリュームまたはワークスペース ファイル内のファイルにアクセスする必要があるライブラリからの JVM ワークロードがある場合は、 Python コマンドや %sh mv. などのシェル コマンドを使用して、ファイルをコンピュート ローカル ストレージにコピーします。 JVM を使用する %fs や dbutils.fs は使用しないでください。 クラスターの起動時にファイルが存在する必要がある場合は、最初にinitスクリプトを使用してファイルを移動します。 「initスクリプトとは」を参照してください。
データにアクセスするためにURIスキームを提供する必要がありますか?
Databricks のデータ アクセス パスは、次のいずれかの標準に従います。
URI スタイルのパス には、URI スキームが含まれます。 Databricks ネイティブのデータ アクセス ソリューションの場合、ほとんどのユース ケースでは URI スキームはオプションです。 クラウド オブジェクト ストレージのデータに直接アクセスする場合は、ストレージ タイプに応じた正しい URI スキームを指定する必要があります。
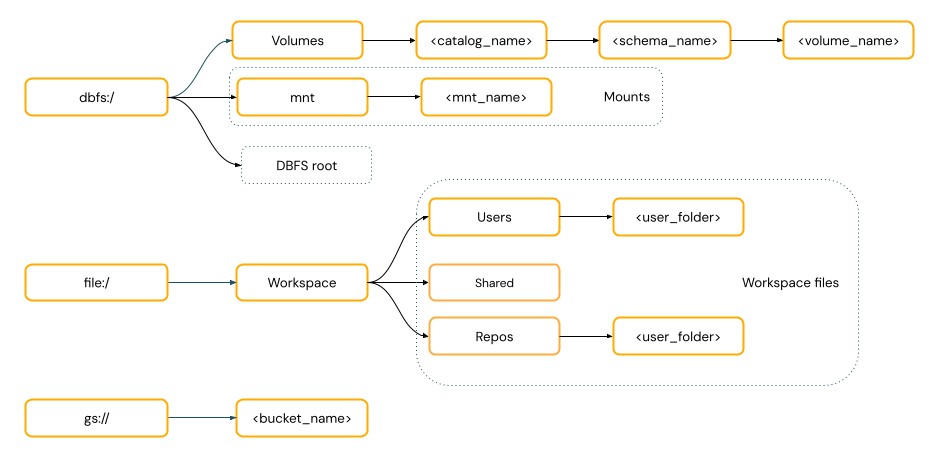
POSIX スタイルのパスは 、ドライバー ルート (
/) を基準としたデータ アクセスを提供します。 POSIX スタイルのパスは、スキームを必要としません。 Unity CatalogボリュームまたはDBFSマウントを使用して、クラウドオブジェクトストレージ内のデータへのPOSIXスタイルのアクセスを提供できます。多くの機械学習フレームワークやその他の OSS Python モジュールは FUSE を必要とし、POSIX スタイルのパスしか使用できません。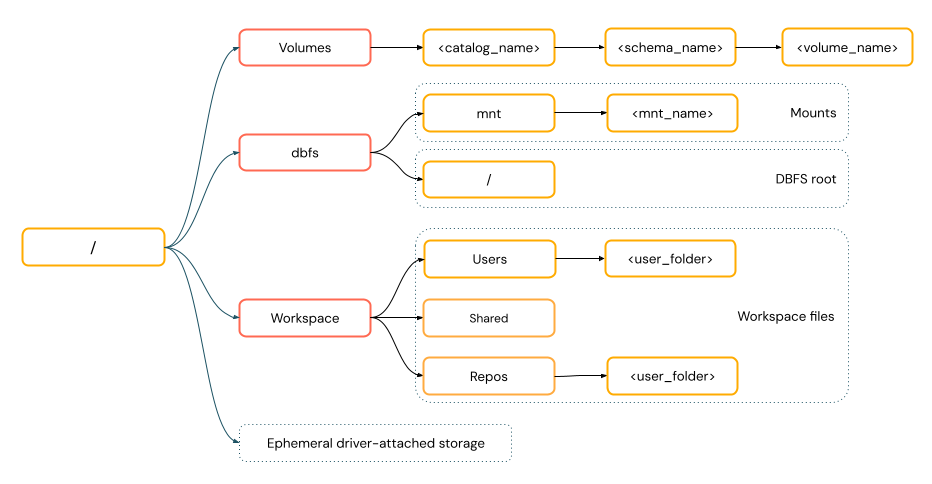
Unity Catalogボリューム内のファイルを操作する
Databricks 、クラウド オブジェクト ストレージに保存されている非表形式のデータ ファイルへのアクセスを構成するには、 Unity Catalogボリュームを使用することをお勧めします。 Unity Catalogボリュームとは何ですか?」を参照してください。
道具 |
例 |
|---|---|
Apache Spark |
|
Spark SQL と Databricks SQL |
|
Databricks ファイルシステムユーティリティ |
|
Databricks CLI |
|
Databricks REST API |
|
Bash シェルコマンド |
|
ライブラリのインストール |
|
Pandas |
|
OSS Python |
|
注
Databricks CLI を使用する場合は、 dbfs:/スキームが必要です。
ボリュームの制限
ボリュームには、次の制限があります。
Zip ファイルや Excel ファイルの書き込みなど、直接追加または非順次 (ランダム) 書き込みはサポートされていません。 直接追加またはランダム書き込みワークロードの場合は、最初にローカル ディスク上で操作を実行し、次に結果をUnity Catalogボリュームにコピーします。 例えば:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')
スパース ファイルはサポートされていません。 スパース ファイルをコピーするには、
cp --sparse=neverを使用します。$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
ワークスペース ファイルの操作
Databricksワークスペース ファイルは、ノートブックではないワークスペース内のファイルです。 ワークスペース ファイルを使用すると、ノートブックやその他のワークスペース アセットと一緒に保存されたデータやその他のファイルを保存したり、アクセスしたりできます。 ワークスペース ファイルにはサイズ制限があるため、Databricks では、主に開発とテスト用に小さなデータ ファイルのみをここに保存することをお勧めします。
道具 |
例 |
|---|---|
Apache Spark |
|
Spark SQL と Databricks SQL |
|
Databricks ファイルシステムユーティリティ |
|
Databricks CLI |
|
Databricks REST API |
|
Bash シェルコマンド |
|
ライブラリのインストール |
|
Pandas |
|
OSS Python |
|
注
file:/スキーマは、Databricks ユーティリティ、Apache Spark、または SQL を操作するときに必要です。
ワークスペースファイルの操作に関する制限事項については、 制限事項を参照してください。
削除されたワークスペースファイルはどこに行くのでしょうか?
ワークスペース ファイルを削除すると、そのファイルはゴミ箱に送信されます。 UI を使用して、ごみ箱からファイルを回復または完全に削除できます。
「オブジェクトの削除」を参照してください。
クラウドオブジェクトストレージ内のファイルの操作
Databricksでは、 Unity Catalogボリュームを使用して、クラウド オブジェクト ストレージ内のファイルへの安全なアクセスを構成することをお勧めします。 URI を使用してクラウド オブジェクト ストレージ内のデータに直接アクセスする場合は、アクセス許可を構成する必要があります。 「外部ロケーション、外部テーブル、外部ボリュームの管理」を参照してください。
次の例では、URI を使用してクラウドオブジェクトストレージ内のデータにアクセスします。
道具 |
例 |
|---|---|
Apache Spark |
|
Spark SQL と Databricks SQL |
|
Databricks ファイルシステムユーティリティ |
|
Databricks CLI |
サポートされていない |
Databricks REST API |
サポートされていない |
Bash シェルコマンド |
サポートされていない |
ライブラリのインストール |
|
Pandas |
サポートされていない |
OSS Python |
サポートされていない |
注
DBFS マウントおよび DBFSルート内のファイルを操作する
DBFS マウントは Unity Catalog を使用してセキュリティ保護することはできず、Databricks では推奨されなくなりました。 DBFSルートに保存されたデータは、ワークスペース内のすべてのユーザーがアクセスできます。 Databricks 、機密性の高いコードやデータを DBFS ルートに保存しないことを推奨しています。 「DBFS とは何ですか?」を参照してください。
道具 |
例 |
|---|---|
Apache Spark |
|
Spark SQL と Databricks SQL |
|
Databricks ファイルシステムユーティリティ |
|
Databricks CLI |
|
Databricks REST API |
|
Bash シェルコマンド |
|
ライブラリのインストール |
|
Pandas |
|
OSS Python |
|
注
Databricks CLI を使用する場合は、 dbfs:/スキームが必要です。
ドライバーノードに接続されたエフェメラルストレージ内のファイルを操作する
ドライバーノードに接続された一時ストレージは、POSIX ベースのパス アクセスを備えたブロック ストレージです。 この場所に保存されているデータは、クラスターが終了または再起動すると消えます。
道具 |
例 |
|---|---|
Apache Spark |
サポートされていない |
Spark SQL と Databricks SQL |
サポートされていない |
Databricks ファイルシステムユーティリティ |
|
Databricks CLI |
サポートされていない |
Databricks REST API |
サポートされていない |
Bash シェルコマンド |
|
ライブラリのインストール |
サポートされていない |
Pandas |
|
OSS Python |
|
注
file:/ スキーマは、Databricks ユーティリティを使用する場合に必要です。
エフェメラルストレージからボリュームへのデータの移動
Apache Spark を使用して、一時ストレージにダウンロードまたは保存されたデータにアクセスする必要がある場合があります。 一時ストレージはドライバーに接続されており、Spark は分散処理エンジンであるため、すべての操作がここでデータに直接アクセスできるわけではありません。 ドライバーファイルシステムからUnity Catalogボリュームにデータを移動する必要があるとします。 その場合、次の例のように、 マジック コマンドまたはDatabricks ユーティリティを使用してファイルをコピーできます。
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
関連リソース
ローカル ファイルのアップロードやインターネット ファイルの Databricksへのダウンロードに関する情報については、「Databricksへのファイルのアップロード」を参照してください。