Unity Catalogのベストプラクティス
本文書では、データガバナンスのニーズを満たすためにUnity CatalogとDelta Sharingを使用するための推奨事項を説明します。
Unity Catalogは、DatabricksプラットフォームのデータとAIのためのきめの細かいガバナンスソリューションです。データアクセスを管理および監査するための中央の場所を提供することで、データのセキュリティとガバナンスの簡素化に役立ちます。Delta共有は、Databricks内のデータを組織外のユーザーと共有できる安全なデータ共有プラットフォームです。Unity Catalogを使用して共有動作を管理および監査します。
データガバナンスとデータ分離の構成要素
組織に適したデータガバナンスモデルとデータ分離計画を開発するには、Databricksでデータガバナンスソリューションを作成するときに利用できる主要な構成要素を理解することが役立ちます。
次の図は、Unity Catalogのプライマリデータ階層を示しています(一部のセキュリティ保護可能なオブジェクトは、カタログで管理されるオブジェクトの階層を強調するためにグレーアウトされています)。
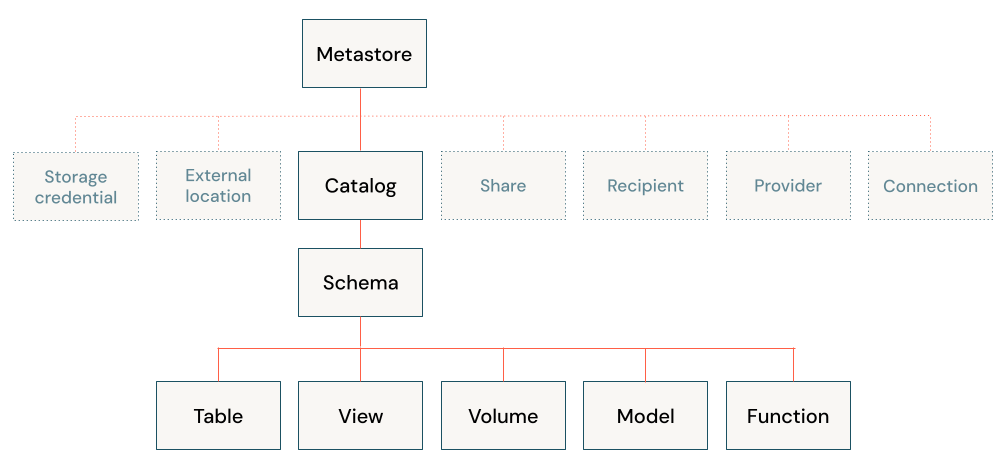
プライマリデータ階層内のオブジェクトには、次のものが含まれます:
メタストア:メタストアは、Unity Catalog内のオブジェクトの最上位のコンテナです。メタストアはアカウントレベルで存在し、Databricksのデータガバナンスモデルのピラミッドの頂点として機能します。
メタストアは、データ資産(テーブル、ビュー、ボリューム)と、それらへのアクセスを制御する権限を管理します。Databricksアカウント管理者は、リージョンごとにメタストアを作成し、同じリージョン内のDatabricksワークスペースに割り当てることができます。メタストア管理者は、メタストア内のすべてのオブジェクトを管理できます。メタストアに登録されているテーブルを直接読み書きすることはできませんが、データオブジェクトの所有権を譲渡できるため、間接的にアクセスできます。
デフォルトでは、特定のメタストアの物理ストレージは、アカウント内の他のメタストアのストレージから分離されています。
メタストアはリージョンの分離を提供しますが、データの分離単位としては意図されていません。データの分離は、カタログレベルで開始する必要があります。
カタログ:カタログは、Unity Catalog Metastoreによって管理されるデータ階層(カタログ > スキーマ > テーブル/ビュー/ボリューム)の最上位レベルです。これらは、典型的なDatabricksデータガバナンスモデルにおけるデータ分離の主要な単位として意図されています。
カタログはスキーマの論理グループを表し、通常はデータアクセス要件によって制限されます。カタログは、多くの場合、組織単位またはソフトウェア開発ライフサイクルの範囲を反映しています。たとえば、本番データ用のカタログと開発データ用のカタログ、または非顧客データ用のカタログと機密性の高い顧客データ用のカタログを選択できます。
カタログはメタストアレベルで保存することも、カタログを親メタストアの残りの部分とは別に保存するように構成することもできます。ワークスペースがUnity Catalogに対して自動的に有効になっている場合は、メタストアレベルのストレージは存在しないため、カタログを作成するときにストレージの場所を指定する必要があります。
カタログがDatabricksデータガバナンスモデルにおけるデータ分離の主要な単位である場合、ワークスペースはデータ資産をオペレーションするための主要な環境です。メタストア管理者とカタログ所有者は、ワークスペースとは独立してカタログへのアクセスを管理したり、カタログを特定のワークスペースにバインドして、特定の種類のデータがそれらのワークスペースでのみ処理されるようにしたりできます。たとえば、実稼働ワークスペースと開発ワークスペースを個別に用意したり、個人データを処理するためのワークスペースを個別に用意したりすることが必要な場合があります。
既定では、セキュリティ保護可能なオブジェクトのアクセス許可は、そのオブジェクトの子によって継承され、カタログは階層の最上位に配置されます。これにより、データの既定のアクセスルールを設定し、階層の各レベルで必要な場合にのみ異なるルールを指定することが容易になります。
スキーマ(データベース):データベースとも呼ばれるスキーマは、テーブル形式のデータ(テーブルとビュー)、非テーブル形式のデータ(ボリューム)、関数、および機械学習モデルを論理的にグループ化したものです。これらは、カタログよりも詳細にデータへのアクセスを整理および制御する方法を提供します。通常、これらは単一のユースケース、プロジェクト、またはチームのサンドボックスを表します。
スキーマは、親カタログと同じ物理ストレージに保存することも、親カタログの残りの部分とは別に保存されるようにスキーマを構成することもできます。
メタストア管理者、親カタログ所有者、およびスキーマ所有者は、スキーマへのアクセスを管理できます。
テーブル:テーブルは、Unity Catalogの3レベルの名前空間の3番目のレイヤーに存在します。テーブルにはデータ行が格納されています。
Unity Catalogを使用すると、マネージドテーブルと外部テーブルを作成できます。
マネージドテーブルの場合、Unity Catalogはライフサイクルとファイルレイアウトを完全に管理します。既定では、マネージドテーブルは、メタストアの作成時に設定したルートストレージの場所に格納されます。代わりに、マネージドテーブルのストレージをカタログレベルまたはスキーマレベルで分離することを選択できます。
外部テーブルは、Unity Catalogではなく、クラウドプロバイダーやその他のデータプラットフォームを使用してデータライフサイクルとファイルレイアウトが管理されるテーブルです。通常、大量の既存データを登録する場合、またはDatabricksクラスターおよびDatabricks SQLウェアハウスの外部のツールを使用してデータへの書き込みアクセスも必要な場合は、外部テーブルを使用します。外部テーブルがUnity Catalog Metastoreに登録されると、マネージドテーブルの場合と同様に、そのテーブルへのDatabricksアクセスを管理および監査できます。
親カタログ所有者とスキーマ所有者は、メタストア管理者と同様に、(間接的に)テーブルへのアクセスを管理できます。
ビュー:ビューは、メタストア内の1つ以上のテーブルとビューから派生した読み取り専用オブジェクトです。
行と列: 行レベルおよび列レベルのアクセスは、データマスキングと共に、動的ビューまたは行フィルターと列マスクを使用して付与されます。動的ビューは読み取り専用です。
ボリューム:ボリュームは、Unity Catalogの3階層ネームスペースの第3層に存在します。これらのボリュームは非表形式のデータを管理します。ボリュームを使用して、構造化データ、半構造化データ、非構造化データなど、あらゆる形式のファイルを保存、整理、アクセスできます。ボリューム内のファイルをテーブルとして登録することはできません。
モデルと関数:厳密に言えば、データ資産ではありませんが、登録されたモデルとユーザー定義関数もUnity Catalogで管理でき、オブジェクト階層の最下位レベルに存在します。詳しくは、「Unity Catalogでのモデルのライフサイクルの管理」および「Unity Catalogのユーザー定義関数 (UDF)」を参照してください。
データ分離モデルを計画する
組織がDatabricksのようなデータプラットフォームを使用する場合、多くの場合、環境間(開発と運用など)または組織の運用単位間にデータ分離境界を設ける必要があります。
分離基準は組織によって異なる場合がありますが、通常は次のことが期待されています:
ユーザーは、指定されたアクセスルールに基づいてのみデータにアクセスできる。
データは、指定された人物またはチームのみが管理できる。
データはストレージ内で物理的に分離されている。
データは指定された環境でのみアクセスできる。
データ分離の必要性により、環境がサイロ化され、データガバナンスとコラボレーションの両方が不必要に困難になる可能性があります。Databricksは、統一されたデータガバナンスプラットフォームを維持しながら、多数のデータ分離オプションを提供するUnity Catalogを使用してこの問題を解決します。このセクションでは、Databricksで利用できるデータ分離オプションと、集中型データガバナンスモデルを好むか、分散型データガバナンスモデルを好むかに応じたその使用方法について説明します。
ユーザーは、指定されたアクセスルールに基づいてのみデータにアクセスできる
ほとんどの組織では、内部要件や規制要件に基づいて、データアクセスに関する厳しい要件が定められています。安全性を確保しなければならないデータの典型例としては、従業員の給与情報やクレジットカードの決済情報などがあります。この種の情報へのアクセスは通常厳しく管理され、定期的に監査されます。Unity Catalogは、このような業界標準を満たすために、カタログ内のデータ資産をきめ細かく制御します。Unity Catalogが提供するコントロールにより、ユーザーは閲覧およびクエリーする権利があるデータのみを閲覧およびクエリーすることができます。
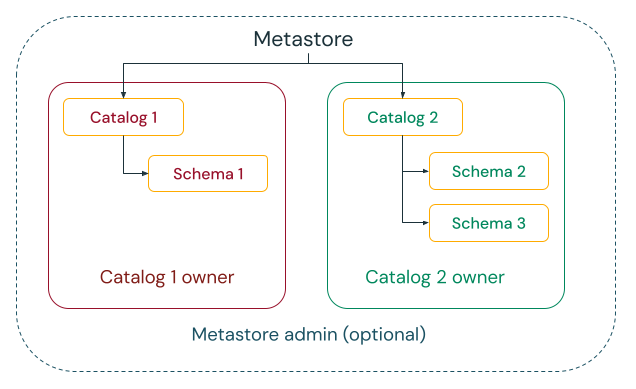
データは指定された人またはチームのみが管理できる
Unity Catalogを使用すると、集中型ガバナンスモデルと分散型ガバナンスモデルのどちらかを選択できます。
集中管理モデルでは、ガバナンス管理者はメタストアの所有者であり、あらゆるオブジェクトの所有権を取得し、権限を付与および取り消すことができます。
分散ガバナンスモデルでは、カタログまたはカタログのセットがデータドメインとなります。そのカタログのオーナーは、すべてのアセットを作成して所有し、そのドメイン内のガバナンスを管理することができます。あるドメインの所有者は、他のドメインの所有者から独立して活動することができます。
データドメインとしてメタストアを選択するかカタログを選択するかに関係なく、Databricksではグループをメタストア管理者またはカタログ所有者として設定することを強くお勧めします。
オーナーは、ユーザー、サービスプリンシパル、およびグループに MANAGE 権限を付与して、オブジェクトに対するパーミッションの付与と取り消しを許可できます。
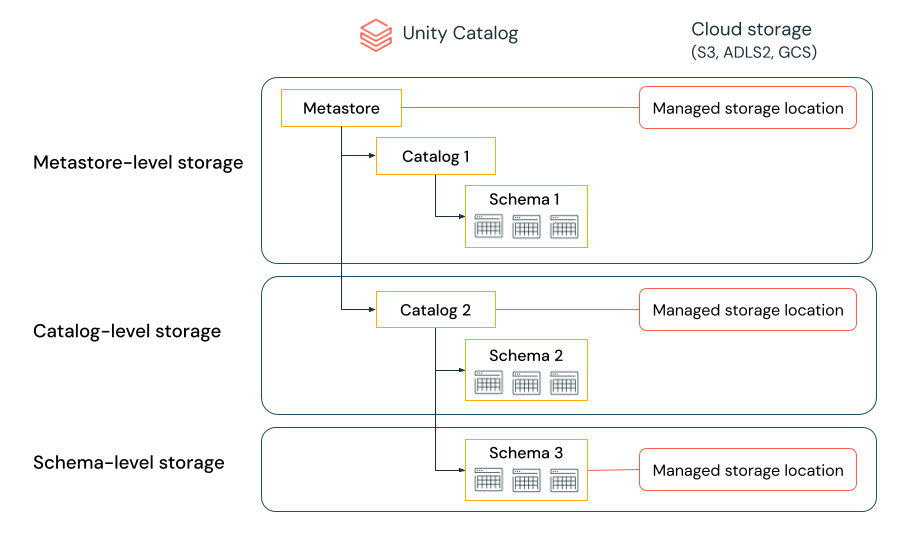
データはストレージ内で物理的に分離されている
特定のタイプのデータをクラウドテナントの特定のアカウントまたはバケットに保存するように要求できます。
Unity Catalogを使用すると、メタストア、カタログ、またはスキーマレベルでストレージロケーションを設定して、それらの要件を満たせるようにすることができます。
たとえば、貴社の組織に、人事に関する本番運用データをgs: //mycompany-hr-prodというバケットに保存することを義務付ける会社のコンプライアンスポリシーがあるとします。Unity Catalogでは、カタログレベルでロケーションを設定し、たとえばhr_prodというカタログを作成し、ロケーションgs://mycompany-hr-prod/unity-catalogをそれに割り当てることでこの要件を達成できます。つまり、hr_prodカタログで作成されたマネージドテーブルまたはボリューム(たとえばCREATE TABLE hr_prod.default.table …を使用)は、そのデータをgs://mycompany-hr-prod/unity-catalogに格納します。必要に応じて、スキーマレベルの場所を提供して、 hr_prod catalog 内のデータをより詳細なレベルで整理することを選択できます。
こうしたストレージの分離が必要ない場合は、メタストアレベルでストレージロケーションを設定して構いません。そうすることで、このロケーションは、メタストア内のカタログとスキーマの両方に対して、マネージドテーブルとマネージドボリュームを格納するデフォルトの場所として機能します。
システムは、スキーマからカタログ、メタストアまでのストレージ場所の階層を評価します。
たとえば、テーブル myCatalog.mySchema.myTable が my-region-metastoreで作成されている場合、このテーブルのストレージロケーションは次のルールに従って決定されます。
ロケーションが
mySchemaに対して指定されている場合、テーブルはそこに格納されます。ロケーションが
myCatalogに指定されている場合、テーブルはそこに格納されます。myCatalogに指定されているロケーションがない場合は、my-region-metastoreに関連付けられたロケーションに格納されます。
指定された環境でのみデータにアクセス可能
多くの場合、組織やコンプライアンスの要件では、個人データなどの特定のデータには特定の環境でのみアクセスできるようにすることが規定されています。また、本番データを開発環境から隔離したり、特定のデータセットやドメインが決して結合されないようにしたい場合もあります。
Databricks では、ワークスペースがプライマリ データ処理環境であり、カタログがプライマリ データ ドメインです。 Unity Catalog を使用すると、メタストア管理者、カタログ所有者、および MANAGE アクセス許可を持つユーザーは、カタログを特定のワークスペースに割り当て ("バインド") できます。 これらの環境対応バインディングを使用すると、ユーザーに付与されたデータ・オブジェクトに対する特定の権限に関係なく、ワークスペース内で特定のカタログのみを使用可能にすることができます。
ここで、ニーズを満たすためにUnity Catalogをセットアップするプロセスを詳しく見てみましょう。
Unity Catalog Metastoreを構成する
メタストアは、Unity Catalogのオブジェクトのトップレベルコンテナです。メタストアは、データアセット(テーブル、ビュー、ボリューム)や、Unity Catalogが管理するその他のセキュアなオブジェクトも管理します。セキュリティ保護可能なオブジェクトの完全なリストについては、「Unity Catalog内のセキュリティ保護可能なオブジェクト」を参照してください。
このセクションでは、メタストアの作成と構成に関するヒントを提供します。ワークスペースがUnity Catalogに対して自動的に有効になっている場合は、メタストアを作成する必要はありません。ただし、このセクションに示す情報は依然として役立つ可能性があります。「Unity Catalogの自動有効化」を参照してください。
メタストアを構成するためのヒント:
Databricksワークスペースがあるリージョンごとに1つのメタストアを設定する必要があります。
1つのリージョンメタストアに接続されているすべてのワークスペースは、メタストアによって管理されるデータにアクセスできます。メタストア間でデータを共有する場合は、Delta Sharingを使用します。
各メタストアは、クラウドテナント内のマネージドストレージの場所(ルートストレージとも呼ばれます)を使用して構成され、マネージドテーブルとマネージドボリュームの格納に使用できます。
メタストアレベルのマネージドロケーションを作成する場合は、ユーザーがそのロケーションに直接(つまり、そのロケーションを持つクラウドアカウントを介して)アクセスできないようにする必要があります。このストレージロケーションへのアクセスを許可すると、ユーザーがUnity Catalog Metastoreのアクセス制御をバイパスし、監査機能を妨害する可能性があります。これらの理由から、メタストアのマネージドストレージは専用のバケットにする必要があります。DBFSルートファイルシステムでもあるバケット、または以前にDBFSルートファイルシステムであったバケットを再利用しないでください。
また、メタストアのルートストレージの場所をオーバーライドして、カタログレベルとスキーマレベルで管理ストレージを定義するオプションもあります。ただしほとんど場合は、マネージドデータをカタログレベルで保存することを推奨しています。
Unity Catalogで有効になっているワークスペースのワークスペース管理者の権限を理解し、既存のワークスペース管理者の割り当てを確認する必要があります。
ワークスペース管理者は、ユーザーやサービスプリンシパルの追加、クラスターの作成、他のユーザーをワークスペース管理者に委任するなど、ワークスペースの操作を管理できます。ワークスペースがUnity Catalogに対して自動的に有効になっている場合、ワークスペース管理者はデフォルトでカタログやその他の多くのUnity Catalogオブジェクトを作成できます。「ワークスペースがUnity Catalogで自動的に有効になっている場合のワークスペース管理者権限」を参照してください。
ワークスペース管理者は、ジョブの所有権の管理やノートブックの表示などのワークスペース管理タスクを実行することもできます。これにより、Unity Catalogに登録されているデータに間接的にアクセスできる場合があります。ワークスペース管理者は特権ロールであり、慎重に配置する必要があります。
ワークスペースを使用してユーザーデータアクセスを分離する場合は、ワークスペースとカタログのバインドを使用できます。ワークスペースとカタログのバインドを使用すると、ワークスペースの境界によってカタログへのアクセスを制限できます。たとえば、ワークスペース管理者とユーザーが、運用ワークスペース環境
prod_workspaceからのみprod_catalogの運用データにアクセスできるようにすることができます。デフォルトでは、現在のメタストアに接続されているすべてのワークスペースとカタログを共有します。「カタログへのアクセスを特定のワークスペースに制限する」を参照してください。ワークスペースでUnity Catalogが自動的に有効になっていた場合、事前にプロビジョニングされたワークスペースカタログは、デフォルトでワークスペースにバインドされます。
「Unity Catalogメタストアの作成」を参照してください。
外部ロケーションとストレージ資格情報を設定する
外部ロケーションを使用すると、Unity Catalogはユーザーに代わってクラウドテナント上のデータを読み書きできます。外部ロケーションは、クラウドストレージへのパスとして定義され、その場所へのアクセスに使用できるストレージ資格情報と組み合わされます。
外部ロケーションを使用して、Unity Catalogの外部テーブルおよび外部ボリュームを登録できます。これらの事業体のコンテンツは、ユーザーがボリュームまたはテーブルを作成するときに参照される外部ロケーションのサブパスに物理的に配置されます。
ストレージ資格情報は、クラウドストレージにアクセスするための長期的なクラウド資格情報をカプセル化します。たとえば、GCPでは、サービスアカウントを設定して、GCSバケットへのロールベースのアクセスを許可できます。
データの分離を強化するために、ストレージの資格情報と外部の場所を特定のワークスペースにバインドできます。 「(オプション) 特定のワークスペースに外部ロケーションを割り当てる」および「(オプション) 特定のワークスペースにストレージ資格情報を割り当てる」を参照してください。
ヒント
外部ロケーションは、ストレージ資格情報とストレージパスを組み合わせることにより、ストレージアクセスの強力な制御と監査可能性を実現します。ユーザーがUnity Catalogによって提供されるアクセス制御をバイパスできないようにするには、外部ロケーションとして使用されているバケットに直接アクセスできるユーザーの数を制限する必要があります。同じ理由から、ストレージアカウントが外部ロケーションとしても使用されている場合もDBFSにマウントしないでください。Databricksでは、Catalog Explorerを使用してクラウドストレージの場所のマウントをUnity Catalogの外部ロケーションに移行することを推奨しています。
外部ロケーションを管理するためのベストプラクティスリストについては、「外部ロケーション、外部テーブル、および外部ボリュームの管理」を参照してください。「外部ロケーションを作成してクラウドストレージをDatabricksに接続する」も参照してください。
データを整理する
Databricksでは、組織の情報アーキテクチャを分類するためにカタログを使用することを推奨しています。これは多くの場合、カタログがソフトウェア開発環境の範囲、チーム、またはビジネスユニットに対応することを意味します。たとえば、本番環境と開発環境に異なるワークスペースを使用したり、機密性の高いデータを扱う特定のワークスペースを使用したりするなど、ワークスペースをデータ分離ツールとして使用する場合、カタログを特定のワークスペースにバインドすることもできます。これにより、指定されたデータのすべての処理が適切なワークスペースで処理されるようになります。「カタログへのアクセスを特定のワークスペースに制限する」を参照してください。
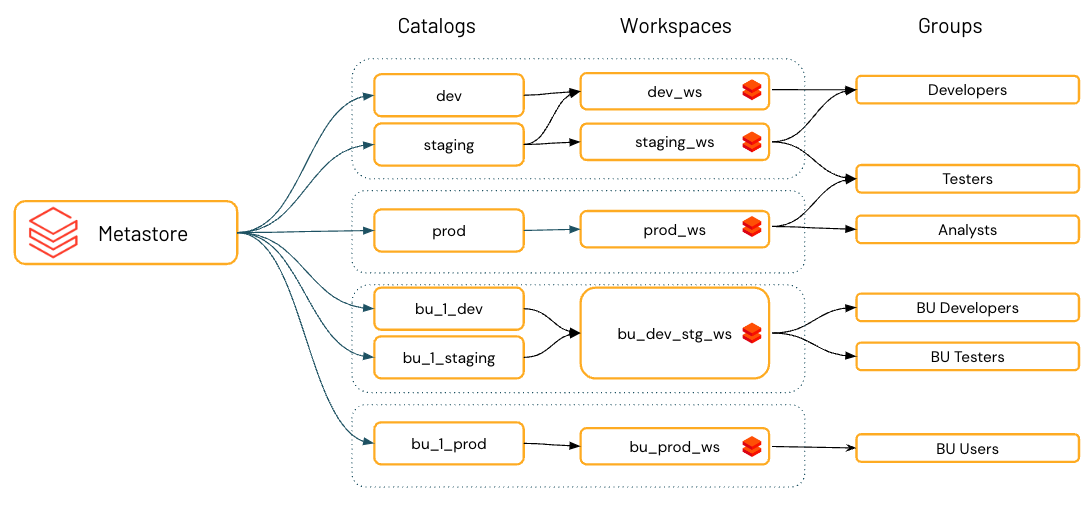
スキーマ(データベースとも呼ばれます)は、Unity Catalogの3層から成る名前空間の2番目の層であり、テーブル、ビュー、ボリュームを整理します。スキーマを使用してアセットを整理し、権限を定義することができます。
Unity Catalogが管理するオブジェクトは、マネージドあるいは外部のものにすることもできます:
マネージドオブジェクトは、Unity Catalogでデータオブジェクトを作成するデフォルトの方法です。
Unity Catalogは、これらのセキュリティ保護可能なリソースのライフサイクルとファイルレイアウトを管理します。Databricksの外部でツールを使用して、マネージドテーブルまたはボリューム内のファイルを直接操作しないでください。
マネージドテーブルとマネージドボリュームは、マネージドストレージに格納されます。このストレージは、任意のテーブルまたはボリューム向けにメタストア、カタログ、またはスキーマレベルで用意することができます。詳しくは、「データはストレージ内で物理的に分離されている」を参照してください。
マネージドテーブルとマネージドボリュームは、外部ロケーションとストレージ資格情報を作成および管理するためのオーバーヘッドなしに、コンテンツの管理された場所をプロビジョニングする場合に便利なソリューションです。
マネージドテーブルでは常にDeltaテーブル形式が使用されます。
外部オブジェクトは、データのライフサイクルとファイルレイアウトがUnity Catalogによって管理されないセキュリティ保護可能なリソースです。
外部ボリュームとテーブルは外部ロケーションに登録され、データコピーアクティビティを必要とせずにクラウドストレージにすでに存在する多数のファイルへのアクセスを提供します。他のシステムによって生成されたファイルがあり、Databricks内からアクセスできるようにステージングする場合、またはDatabricksの外部のツールがこれらのファイルに直接アクセスする必要がある場合は、外部オブジェクトを使用します。
外部テーブルは、Delta Lakeや、Parquet、JSON、CSVなどの他の多くのデータ形式をサポートしています。マネージドボリュームと外部ボリュームの両方を使用して、任意の形式のファイルにアクセスして保存できます。データは構造化、半構造化、または非構造化のいずれかです。
テーブルとボリュームの作成の詳細については、「 テーブルとビューとは」を参照してください。 およびUnity Catalog ボリュームとは。
外部ロケーション、外部テーブル、外部ボリュームを管理する
以下の図は、1つのストレージ資格情報を共有する4つの外部ロケーションを持つ、単一のクラウドストレージバケットのファイルシステム階層を表しています。
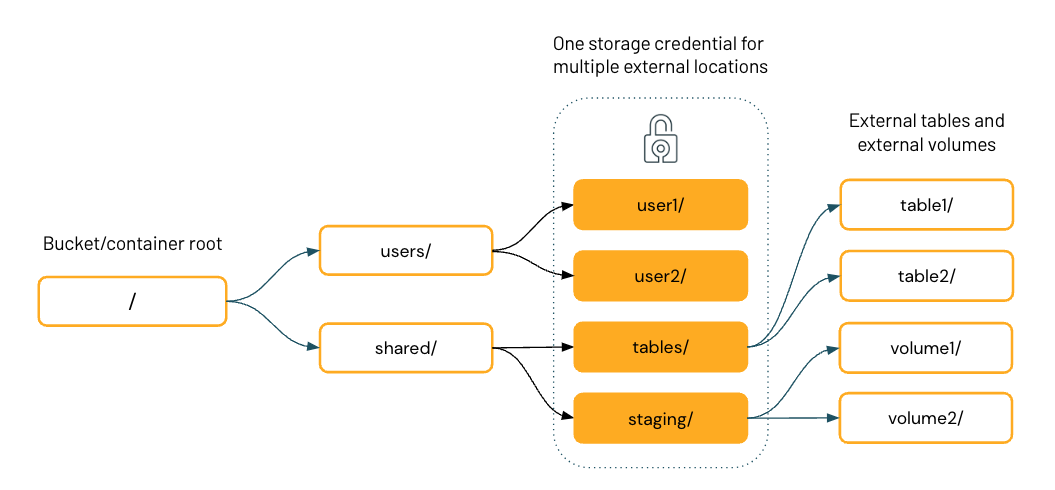
Unity Catalogで外部ロケーションを構成したら、外部ロケーション内のディレクトリに外部テーブルとボリュームを作成できます。その後、Unity Catalogを使用して、これらのテーブルとボリュームへのユーザーおよびグループのアクセスを管理できます。これにより、特定のユーザーまたはグループに特定のディレクトリとクラウド上のストレージバケットにあるファイルへのアクセスを提供できます。
注
外部ボリュームを定義すると、ボリューム パスの下のデータへのクラウド URI アクセスは、ボリュームが格納されている外部ロケーションで付与される特権ではなく、ボリュームで付与される特権によって制御されます。
外部ロケーションを使用する場合の推奨事項
外部ロケーションに対するアクセス許可を付与するための推奨事項:
外部ロケーションを作成する権限は、Unity Catalogとクラウドストレージ間の接続を設定するタスクである管理者、または信頼できるデータエンジニアにのみ付与します。
外部ロケーションは、Unity Catalog内からクラウドストレージ内の広範な場所(バケット全体(gs://mybucket)や広範なサブパス(gs://mybucket/alotofdata)など)へのアクセスを提供します。その目的は、クラウド管理者がいくつかの外部ロケーションの設定に関与し、それらの場所を管理する責任を組織内のDatabricks管理者に委任できるようにすることです。Databricks管理者は、外部ロケーションの下の特定のプレフィックスで外部ボリュームまたは外部テーブルを登録することで、外部ロケーションをより詳細なアクセス許可を持つ領域にさらに整理できます。
外部ロケーションは非常に包括的であるため、Databricksでは、Unity Catalogとクラウドストレージ間の接続を設定するタスクである管理者、または信頼できるデータエンジニアにのみ
CREATE EXTERNAL LOCATIONアクセス許可を付与することをお勧めします。他のユーザーにより詳細なアクセスを提供するために、Databricksでは、外部ロケーションの上に外部テーブルまたはボリュームを登録し、ボリュームまたはテーブルを使用してデータへのアクセス権をユーザーに付与することをお勧めします。テーブルとボリュームはカタログとスキーマの子であるため、カタログ管理者またはスキーマ管理者は、アクセス許可を最終的に制御できます。特定のワークスペースにバインドすることで、外部ロケーションへのアクセスを制御することもできます。詳しくは、「(オプション) 特定のワークスペースに外部ロケーションを割り当てる」を参照してください。
外部ロケーションに対する一般的な
READ FILESまたはWRITE FILESアクセス許可をエンドユーザーに付与しないでください。ボリュームが利用できるようになったため、ユーザーはテーブル、ボリューム、または管理された場所の作成以外に外部ロケーションを使用しないでください。データサイエンスやその他の表形式以外のデータのユースケースのパスベースのアクセスに外部ロケーションを使用しないでください。
ボリュームは、SQLコマンド、dbutils、Spark API、REST API、Terraformを使用したファイルオペレーションのサポートと、ファイルの参照、アップロード、ダウンロードのためのユーザーインターフェイスを提供します。さらに、ボリュームは、
/Volumes/<catalog_name>/<schema_name>/<volume_name>/の下のローカルファイルシステム上でアクセスできるFUSEマウントを提供します。FUSEマウントを使用すると、データサイエンティストやMLエンジニアは、多くの機械学習やオペレーティングシステムライブラリで必要とされるローカルファイルシステム内にあるかのようにファイルにアクセスできます。外部ロケーションにあるファイルへの直接アクセスを許可する必要がある場合(たとえば、ユーザーが外部テーブルまたはボリュームを作成する前にクラウドストレージ内のファイルを探索する場合)、
READ FILESを付与できます。WRITE FILESを付与するユースケースはまれです。
外部ロケーションを使用して、次のオペレーションを行う必要があります:
外部テーブルとボリュームを登録するには、
CREATE EXTERNAL VOLUMEコマンドまたはCREATE TABLEコマンドを使用します。特定のプレフィックスで外部テーブルまたはボリュームを作成する前に、クラウドストレージ内の既存のファイルを探索します。
READ FILES特権は前提条件です。Metastoreルートバケットの代わりに、カタログとスキーマのマネージドストレージとして場所を登録します。
CREATE MANAGED STORAGE特権は前提条件です。
外部ロケーションを使用するためのその他の推奨事項:
パスの重複の競合を回避する:外部ロケーションのルートに外部ボリュームまたはテーブルを作成しないでください。
外部ロケーションのルートに外部ボリュームまたは外部テーブルを作成する場合、その外部ロケーションに追加の外部ボリュームまたは外部テーブルを作成することはできません。代わりに、外部ロケーション内のサブディレクトリに外部ボリュームまたは外部テーブルを作成します。
外部ボリュームの使用に関する推奨事項
外部ボリュームを使用して、次のことを行う必要があります:
外部システムによって生成された生データのランディングエリアを登録して、ETLパイプラインやその他のデータエンジニアリング活動の初期段階での処理をサポートします。
たとえば、Auto Loader、
COPY INTO、またはCTAS(CREATE TABLE AS)ステートメントを使用して、インジェストするステージング場所を登録します。マネージドボリュームがオプションではない場合に、データサイエンティスト、データアナリスト、機械学習エンジニアが探索的データ分析やその他のデータサイエンスタスクの一部として使用できるファイルストレージの場所を提供します。
他のシステムによってクラウドストレージに生成および保存された任意のファイルにDatabricksユーザーがアクセスできるようにします。そうしたファイルには、監視システムやIoTデバイスによってキャプチャされた非構造化データ(画像、音声、動画、PDFファイルなど)の大量コレクションや、ローカルの依存関係管理システムやCI/CDパイプラインからエクスポートされたライブラリファイル(JARやPython wheelファイル)などが該当します。
マネージドボリュームがオプションにならない場合、ロギングファイルやチェックポイントファイルなどの運用データを保管します。
外部ボリュームの使用に関するその他の推奨事項:
Databricksでは、1つのスキーマ内の1つの外部ロケーションから外部ボリュームを作成することをお勧めします。
ヒント
データが別の場所にコピーされる取り込みユースケース(たとえばAuto LoaderやCOPY INTOを使用する)の場合は、外部ボリュームを使用します。コピーを使用せずに、テーブルとしてその場でデータをクエリーする場合は、外部テーブルを使用します。
外部テーブルの使用に関する推奨事項
マネージドテーブルを作成できない場合は、クラウドストレージに保存されているデータに対する通常のクエリーパターンをサポートするために外部テーブルを使用する必要があります。
外部テーブルの使用に関するその他の推奨事項:
スキーマごとに1つの外部ロケーションを使って外部テーブルを作成することをお勧めします。
Databricksでは、整合性の問題が発生するリスクがあるため、テーブルを複数のメタストアに外部テーブルとして登録しないことを強く推奨しています。たとえば、あるメタストアでスキーマを変更しても、2番目のメタストアには登録されません。メタストア間のデータ共有には、デルタ共有を使用してください。詳しくは、「Delta Sharingを使用したデータの安全な共有」を参照してください。
アクセスコントロールの設定
Unity Catalog の各セキュリティ保護可能なオブジェクトには所有者がいます。 オブジェクトを作成するプリンシパルが、その初期所有者になります。 オブジェクトの所有者は、テーブルに対する SELECT や MODIFY など、オブジェクトに対するすべての権限と、セキュリティ保護可能なオブジェクトに対する権限を他のプリンシパルに付与する権限を持ちます。 所有者は、そのオブジェクトに対する権限を他のプリンシパルに付与できます (オブジェクトに対する権限を付与する権限を委任する MANAGE 権限を含む)。 所有者、メタストア管理者、および MANAGE 権限を持つユーザーは、セキュリティ保護可能なオブジェクトの所有権をグループに譲渡できます。 また、オブジェクトがカタログ (テーブルやビューなど) に含まれている場合、カタログとスキーマの所有者はオブジェクトの所有権を変更できます。
Unity Catalogのセキュリティ保護可能なオブジェクトは階層構造で、権限は上位から下位に継承されます。これは、カタログまたはスキーマに対する権限を付与すると、カタログまたはスキーマ内の現在および将来のすべてのオブジェクトにその権限が自動的に付与されることを意味します。詳細については、「継承モデル」を参照してください。
テーブルまたはビューからデータを読み取るには、ユーザーは次の権限を持っている必要があります:
SELECTテーブルやビューUSE SCHEMAテーブルを所有するスキーマUSE CATALOGスキーマを所有するカタログ
USE CATALOG は、権限受領者がカタログをトラバースしてその子オブジェクトにアクセスできるようにします。USE SCHEMAは、権限受領者がスキーマをトラバースしてその子オブジェクトにアクセスできるようにします。たとえば、テーブルからデータを選択するには、ユーザーはそのテーブルに対するSELECT権限と、その親カタログに対するUSE CATALOG権限、さらにその親スキーマに対するUSE SCHEMA権限を持っている必要があります。したがって、この権限を使用すれば、データ名前空間のセクションへのアクセスを特定のグループに限定できます。この一般的な使い方としては、チームごとにスキーマを設定し、そのチームのみがそのスキーマにUSE SCHEMAとCREATEを持つようにするといった使い方が考えられます。この場合、チームメンバーが作成したテーブルはチーム内にのみ共有されることになります。
次のSQL構文を使用して、テーブルへのアクセスを保護できます:
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
次のSQL構文に示すように、セカンダリスキーマのダイナミックビューを使用して列へのアクセスを保護できます:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
id,
CASE WHEN is_account_group_member(< group_name >) THEN email ELSE 'REDACTED' END AS email,
country,
product,
total
FROM
< catalog_name >.< schema_name >.< table_name >;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
次のSQL構文に示すように、セカンダリスキーマの動的ビューを使用して行へのアクセスを保護できます:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
*
FROM
< catalog_name >.< schema_name >.< table_name >
WHERE
CASE WHEN is_account_group_member(managers) THEN TRUE ELSE total <= 1000000 END;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
行フィルターと列マスクを使用して、ユーザーにテーブルへの安全なアクセスを許可することもできます。詳細については、「行フィルターと列マスクを使用して機密テーブル データをフィルター処理する」を参照してください。
Unity Catalogのすべての権限の詳細については、「Unity Catalogで権限を管理する」を参照してください。
コンピュート構成の管理
Databricks では、コンピュート ポリシーを使用して、一連のルールに基づいてクラスタリングを構成する機能を制限することをお勧めします。 コンピュート ポリシーを使用すると、Unity Catalog が有効になっているクラスタリングのみを作成するようにアクセスを制限できます。 コンピュート ポリシーを使用すると、使用可能な選択肢が減り、ユーザーのクラスタリング作成プロセスが大幅に簡素化され、ユーザーがシームレスにデータにアクセスできるようになります。 コンピュート ポリシーを使用すると、クラスタリングごとの最大コストを制限することで、コストを制御することもできます。
アクセス制御の整合性を確保し、強力な分離保証を適用するために、Unity Catalogはコンピューティングリソースにセキュリティ要件を課します。このため、Unity Catalogではクラスターのアクセスモードの概念が導入されています。Unity Catalogはデフォルトで安全です。クラスターが適切なアクセスモードが設定されていない場合、クラスターはUnity Catalog内のデータにアクセスできません。「コンピュートの要件」を参照してください。
Databricks では、すべてのワークロードに対して共有アクセス モードをお勧めします。 シングル ユーザー アクセス モードは、必要な機能が共有アクセス モードでサポートされていない場合にのみ使用してください。 「アクセスモード」を参照してください。
以下のJSONは、共有アクセスモードを使用したクラスターのポリシー定義を提供します:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9]*\\.x-scala.*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "USER_ISOLATION",
"hidden": true
}
}
以下のJSONは、シングルユーザーアクセスモードでの自動ジョブクラスターのポリシー定義を提供します。
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9].*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "SINGLE_USER",
"hidden": true
},
"single_user_name": {
"type": "regex",
"pattern": ".*",
"hidden": true
}
}
監査アクセス
完全なデータガバナンスソリューションには、データへのアクセスを監査し、警告機能と監視機能を提供する必要があります。Unity Catalogはメタストアに対して実行されたアクションの監査ログをキャプチャし、これらのログはDatabricksの監査ログの一部として配信されます。
アカウントの監査ログには、システムテーブルを使用してアクセスできます。監査ログシステムテーブルの詳細については、「監査ログシステムテーブルリファレンス」を参照してください。
Databricksデータインテリジェンスプラットフォームに関連する重要なイベントを完全に可視化する方法については、「監査ログによるDatabricksデータインテリジェンスプラットフォームの監視」を参照してください。