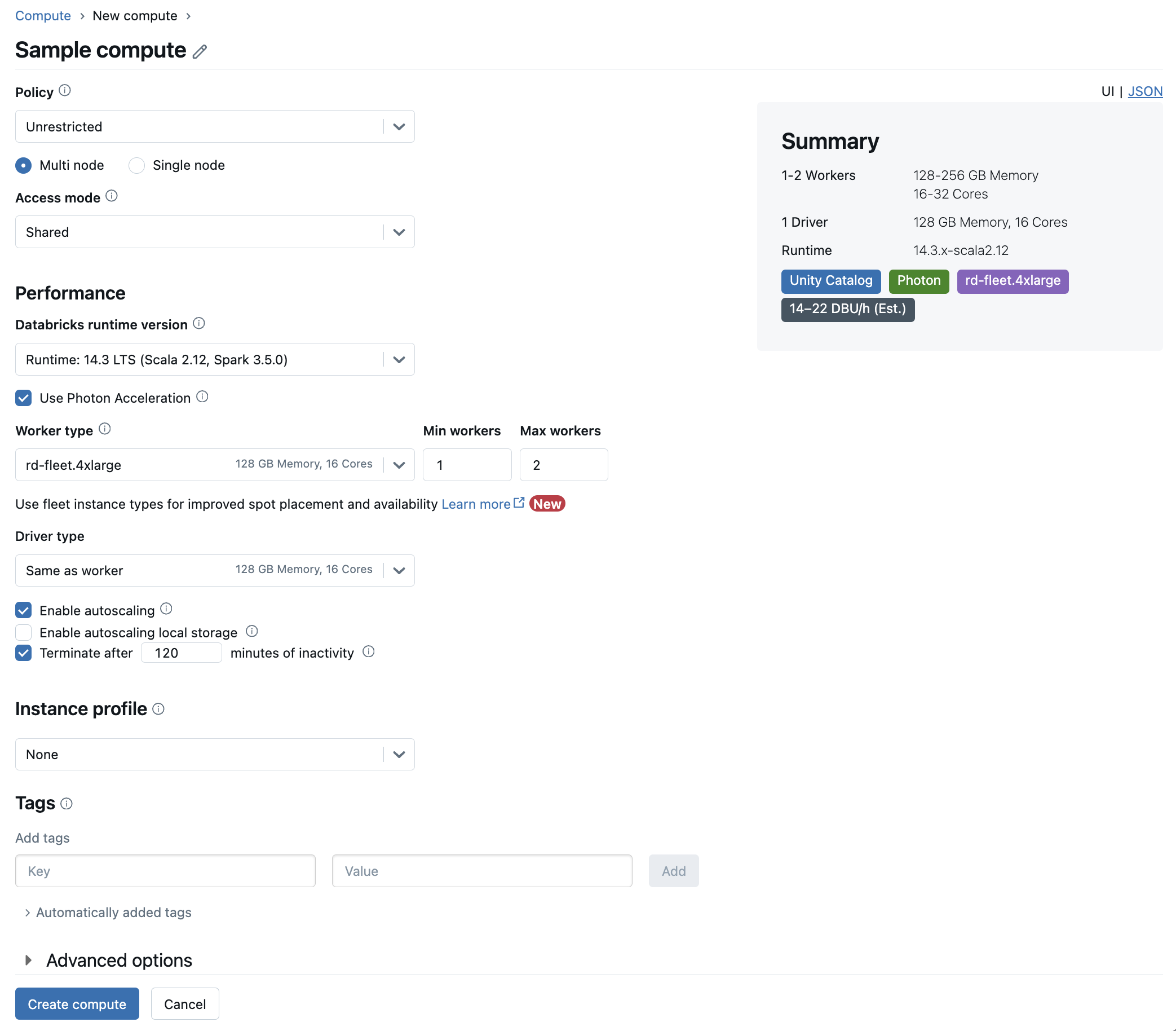
コンピュート構成リファレンス
この記事では、「コンピュート UI を作成」で利用できる構成の設定について説明します。ほとんどのユーザーは割り当てられたポリシーを使用してコンピュートリソースを作成するため、構成可能な設定が制限されます。UI に特定の設定が表示されない場合、それは選択したポリシーでその設定を行うことができないことが理由です。
この記事で説明する構成と管理ツールは、all-purpose とジョブ コンピュートの両方に適用されます。 ジョブ コンピュートの構成に関する考慮事項の詳細については、「 ジョブのコンピュートを構成する」を参照してください。
新しい汎用コンピュートリソースを作成する
新しい汎用コンピュートリソースを作成するには、次の手順を実行します。
ワークスペースのサイドバーで、[コンピュート] をクリックします。
[コンピュートを作成] ボタンをクリックします。
コンピュートリソースを構成します。
[コンピュートを作成] をクリックします。
新しいコンピュートリソースは自動的にスピンアップを開始し、すぐに使用できるようになります。
ポリシー
ポリシーは、ユーザーがコンピュートリソースを作成するときに利用できる設定オプションを制限するために使用される一連のルールです。ユーザーが無制限でクラスター作成を許可する権限を持っていない場合、そのユーザーは付与されたポリシーを使用してコンピュートリソースを作成することしかできません。
ポリシーに従ってコンピュートリソースを作成するには、[ポリシー] ドロップダウンメニューから目的のポリシーを選択します。
デフォルトでは、すべてのユーザーがパーソナルコンピュートポリシーにアクセスでき、単一マシンのコンピュートリソースを作成できます。パーソナルコンピュートまたはその他のポリシーへのアクセスが必要な場合は、ワークスペース管理者にお問い合わせください。
シングルノードまたはマルチノードのコンピュート
ポリシーに応じて、シングルノードのコンピュートリソースを作成するかマルチノードのコンピュートリソースを作成するかを選択できます。
シングルノードコンピュートは、少量のデータまたはシングルノードの機械学習ライブラリなどの非分散ワークロードを使用するジョブを対象としています。マルチノードコンピュートは、作業負荷が分散された大規模なジョブに使用する必要があります。
シングルノードのプロパティ
シングルノードのコンピュートリソースには次のプロパティが含まれます。
Sparkをローカルで実行します。
ドライバーはマスターとワーカーの両方の役割を果たし、ワーカーノードはありません。
コンピュートリソースの論理コアごとに 1 つのエグゼキュータースレッドを生成し、ドライバー用に 1 コアを引いたものです。
すべての
stderr、stdout、およびlog4jログ出力をドライバーログに保存します。マルチノードのコンピュートリソースに変換することはできません。
単一ノードまたは複数ノードの選択
シングルノードとマルチノードのコンピュートのどちらを使用するかは、ユースケースに応じて決定してください。
大規模なデータ処理では、シングルノードのコンピュートリソースのリソースが枯渇してしまいます。このようなワークロードの場合、Databricks ではマルチノードのコンピュートの使用を推奨しています。
シングルノードのコンピュートは共有できるように設計されていません。リソースの競合を回避するために、コンピュートを共有する必要がある場合は、Databricks ではマルチノードのコンピュートリソースを使用することを推奨しています。
マルチノードのコンピュートリソースを 0 ワーカーにスケーリングすることはできません。代わりにシングルノードのコンピュートを使用してください。
単一ノードコンピュートはプロセス分離と互換性がありません。
GPUスケジューリングは単一ノードコンピュートでは有効になっていません。
単一ノードコンピュートの場合、SparkはUDT列を含むParquetファイルを読み取ることができません。次のエラーメッセージが表示されます。
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.この問題を回避するには、ネイティブのParquetリーダーを無効にします。
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
アクセスモード
アクセスモードは、コンピュートリソースを使用できるユーザーと、コンピュートリソースを使用してアクセスできるデータを決定するセキュリティ機能です。Databricksの各コンピュートリソースにはアクセスモードがあります。
Databricks では、すべてのワークロードに共有アクセス モードを使用することをお勧めします。 シングル ユーザー アクセス モードは、必要な機能が共有アクセス モードでサポートされていない場合にのみ使用してください。
アクセスモード |
ユーザーに表示 |
UCサポート |
対応言語 |
注 |
|---|---|---|---|---|
シングルユーザー |
いつも |
あり |
Python、SQL、Scala、R |
1人のユーザーに割り当てて使用できます。一部のワークスペースでは、割り当てアクセスモードと呼ばれています。 |
共有 |
常時(プレミアムプランが必要) |
あり |
Python (Databricks Runtime 11.3 LTS 以降)、SQL、Scala (Databricks Runtime 13.3 LTS 以降を使用した Unity Catalog対応コンピュート上) |
ユーザー間でデータを分離することにより、複数のユーザーが使用できます。 |
分離なし共有 |
管理者は、管理者設定ページでユーザーの分離を適用することで、このアクセスモードを非表示にできます。 |
いいえ |
Python、SQL、Scala、R |
|
カスタム |
非表示(すべての新しいコンピュート) |
いいえ |
Python、SQL、Scala、R |
このオプションは、アクセスモードが指定されていない既存のコンピュートリソースがある場合にのみ表示されます。 |
既存のコンピュートリソースをアップグレードしてUnity Catalogの要件を満たすには、アクセスモードを[シングルユーザー]または[共有]に設定します。Unity Catalog対応のワークスペースで、各アクセスモードでサポートされる機能の詳細については、「Unity Catalogのコンピュートアクセスモードの制限事項」を参照してください。
注:
Databricks Runtime 13.3 LTS以降では、initスクリプトとライブラリがすべてのアクセスモードでサポートされます。要件とサポートのレベルは異なります。「initスクリプトはどこにインストールすればいいですか?」および「クラスタースコープのライブラリ」を参照してください。
Databricks Runtimeのバージョン
Databricks Runtimeは、コンピュートで実行されるコアコンポーネントのセットです。Databricks Runtime Versionドロップダウンメニューを使用してランタイムを選択します。特定のDatabricks Runtimeバージョンの詳細については、Databricks Runtimeリリースノートのバージョンと互換性を参照してください。すべてのバージョンにApache Sparkが含まれています。Databricksでは、次のことを推奨しています。
汎用コンピュートの場合は、コードとプリロードされたパッケージ間の最新の互換性を確保するために、最新の最適化と、最新バージョンを使用してください。
運用ワークロードを実行しているジョブコンピュートの場合は、Databricks Runtimeの長期サポート(LTS)バージョンの使用を検討してください。LTSバージョンを使用すれば、互換性の問題が発生せず、アップグレードする前にワークロードを徹底的にテストできます。
データサイエンスと機械学習のユースケースでは、Databricks Runtime MLバージョンを検討してください。
Photonアクセラレーションを使用する
Photonは、Databricks Runtime 9.1 LTS以降を実行しているコンピューティングで使用できます。
Photonアクセラレーションを有効または無効にするには、[Photonアクセラレータを使用] チェックボックスを選択します。Photonの詳細については、「 Photonとは」を参照してください。
ワーカーノードとドライバーノードの種類
コンピュートリソースは、1 つのドライバーノードと 0 個以上のワーカーノードで構成されます。ドライバーノードとワーカーノードに別々のクラウドプロバイダーインスタンスタイプを選択できますが、デフォルトでは、ドライバーノードはワーカーノードと同じインスタンスタイプを使用します。インスタンスタイプのファミリーが異なれば、メモリ集約型またはコンピュート集約型のワークロードなど、さまざまなユースケースに適合します。
ワーカーノードまたはドライバーノードとして使用するプールを選択することもできます。 ワーカーの種類として、プリエンプティブル VM インスタンスを持つプールのみを使用してください。 ドライバーが再利用されないように、別のオンデマンド ドライバーの種類を選択します。 「プールへの接続」を参照してください。
ワーカーの種類
マルチノードのコンピュートでは、コンピュートリソースが正しく機能するために必要な Spark エグゼキューターやその他のサービスをワーカーノードは実行します。Spark を使用してワークロードを分散すると、すべての分散処理がワーカーノードで行われます。Databricks では、ワーカーノードごとに 1 つのエグゼキューターを実行します。そのため、エグゼキューターとワーカーという用語は、Databricks アーキテクチャのコンテキストでは同じ意味で使用されます。
ヒント
Spark ジョブを実行するには、少なくとも 1 つのワーカーノードが必要です。コンピュートリソースのワーカーがゼロの場合、ドライバーノードで Spark 以外のコマンドは実行できますが、Spark コマンドは失敗します。
Driverのタイプ
ドライバーノードは、コンピュートリソースに接続されているすべてのノートブックの状態情報を保持します。また、ドライバーノードは SparkContext を維持し、コンピュートリソース上のノートブックまたはライブラリから実行するすべてのコマンドを解釈し、Spark エグゼキューターと連携する Apache Spark マスターを実行します。
ドライバーノードタイプのデフォルト値は、ワーカーノードタイプと同じです。Sparkワーカーから大量のデータをcollect()により収集してノートブックで分析する場合は、より多くのメモリを備えたより大きなドライバーノードの種類を選択できます。
ヒント
ドライバーノードは、アタッチされているノートブックのすべての状態情報を保持するため、未使用のノートブックは必ずドライバーノードからデタッチしてください。
GPUインスタンスタイプ
ディープラーニングに関連するタスクなど、高いパフォーマンスを必要とする計算量が多いタスクの場合、Databricks はグラフィックス処理装置(GPU)で高速化されたコンピュートリソースをサポートします。詳細については、「GPU対応コンピュート」を参照してください。
優先インスタンス
優先VMインスタンスは、通常のインスタンスよりもはるかに低価格で作成して実行できるインスタンスです。ただし、他のタスクのためにこれらのリソースへのアクセスが必要な場合、Google Cloudはこのようなインスタンスを停止(プリエンプト)することがあります。優先インスタンスはGoogleコンピュートエンジンの余剰容量を使用するため、その可用性は使用状況によって変動します。
新しいコンピュートリソースを作成する場合、以下の2つの異なる方法でプリエンプティブルVMインスタンスを有効にすることができます。
UIを使用してコンピュートを作成する場合は、[ワーカータイプ] の詳細の横にあるプリエンプティブルインスタンスをクリックします。
UIを使用してインスタンスプールを作成する場合は、[オンデマンド/プリエンプティブル] を [すべてのプリエンプティブル]、[プリエンプティブル(フォールバックGCP)]、または [オンデマンドGCP] に設定します。プリエンプティブルVMインスタンスが利用できない場合、コンピュートはデフォルトのフォールバックとしてオンデマンドVMインスタンスを使用するようになっています。フォールバック動作を構成するには、
gcp_attributes.gcp_availabilityをPREEMPTIBLE_GCPまたはPREEMPTIBLE_WITH_FALLBACK_GCPに設定します。デフォルトはON_DEMAND_GCPです。
{
"instance_pool_name": "Preemptible w/o fallback API test",
"node_type_id": "n1-highmem-4",
"gcp_attributes": {
"availability": "PREEMPTIBLE_GCP"
}
}
次に、新しいコンピュートリソースを作成し、プールをプリエンプティブルインスタンスプールに設定します。
ローカルSSDを備えたインスタンスタイプ
インスタンスタイプの最新リスト、それぞれの価格、ローカルSSDのサイズについては、GCPの料金見積もりを参照してください。
ローカルSSDを持つインスタンスタイプは、デフォルトのGoogle Cloudサーバー側暗号化で暗号化され、パフォーマンス向上のために自動的にディスクキャッシングが使用されます。すべてのインスタンスタイプのキャッシュサイズは自動的に設定されるため、ディスク使用量を明示的に設定する必要はありません。
コンピュート用にローカルSSDを構成する
クラスターAPIを使用してコンピュートリソースを作成するときに、コンピュートリソースにアタッチするローカルSSDの数を設定することができます。
ローカルSSDの数を設定するには、gcp_attributesオブジェクトにlocal_ssd_countの値を設定します。各インスタンスタイプは、一定数のアタッチされたローカルSSDのみをサポートできます。local_ssd_countで指定された値は、ドライバーとワーカーのインスタンスタイプの両方に対して有効である必要があります。詳細については、ローカルSSDとマシンタイプに関するGCPドキュメントを参照してください。
オートスケールを有効化する
「オートスケールを有効にする」をチェックすると、コンピュートリソースのワーカーの最小値と最大値を指定できます。その後で、ジョブの実行に必要な適切な数のワーカーを Databricks は選択します。
コンピュートリソースがオートスケールを行うワーカーの最小値と最大値を設定するには、[ワーカータイプ] ドロップダウンの横にある[ワーカーの最小数] フィールドと [ワーカーの最大数] フィールドを使用します。
オートスケールを有効にしない場合は、[ワーカータイプ] ドロップダウンの横にある [ワーカー] フィールドに固定数のワーカーを入力する必要があります。
注:
コンピュートリソースが実行中の場合、コンピュートの詳細ページに割り当てられたワーカーの数が表示されます。割り当てられたワーカーの数をワーカーの設定と比較し、必要に応じて調整を行うことができます。
オートスケールのメリット
オートスケールを使用すると、Databricksはジョブの特性を考慮してワーカーを動的にアカウントに再割り当てします。パイプラインの特定の部分は他の部分よりも計算負荷が高い場合があり、Databricksはジョブのこれらのフェーズ中にワーカーを自動的に追加(さらに、ワーカーが不要になったときにワーカーを削除)します。
オートスケーリングを使用すると、ワークロードに合わせてコンピュートをプロビジョニングする必要がないため、使用率を簡単に上げられます。これは、要件が時間の経過と共に変化するワークロード(1日の間にデータセットを探索するなど)の場合に特に当てはまりますが、プロビジョニング要件が不明な1回限りの短いワークロードの場合に当てはまります。オートスケーリングには次の2つの利点があります。
ワークロードは、固定サイズのプロビジョニング不足のコンピュートリソースと比較して高速に実行できます。
オートスケールを使うことで、静的にサイズ調整されたコンピュートリソースと比較して全体的なコストを削減できます。
コンピュートリソースの固定サイズとワークロードに応じて、オートスケールでは、これらの利点の一方または両方が同時に実現されます。コンピュートのサイズは、クラウドプロバイダーがインスタンスを終了するときに選択されたワーカーの最小数を下回る可能性があります。この場合、Databricks は、ワーカーの最小数を維持するために、インスタンスの再プロビジョニングを継続的に再試行します。
注:
オートスケールはspark-submitジョブでは使用できません。
注:
コンピュートのオートスケーリングは、構造化ストリーミングワークロードのクラスターサイズのスケールダウンに対して制限があります。Databricksでは、ストリーミングワークロードの強化オートスケーリングでDelta Live Tablesを使用することを推奨しています。「強化オートスケールを使用してDelta Live Tablesパイプラインのクラスター使用率を最適化する」を参照してください。
オートスケールの動作
オートスケールには、次の特性があります。
まず8ノードを追加します。その後、指数関数的にスケールアップし、最大値に達するまでに必要なステップ数を踏みます。
ノードの90%が10分間ビジー状態でなく、コンピュートも30秒以上アイドル状態である場合にスケールダウンします。
1 ノードから指数関数的にスケールダウンします。
プールのついたオートスケール
コンピュートリソースをプールに接続する場合は、次の点を考慮してください。
リクエストされたコンピュートサイズが、プール内のアイドル状態のインスタンスの最小数以下であることを確認してください。大きい場合、コンピュートの起動時間は、プールを使用しないコンピュートと同じになります。
ローカルストレージのオートスケールを有効化
Google Cloudのコンピュートインスタンスは、ゾーンのソリッドステート永続ディスクを使用して、ワーカーレベルの追加ストレージで補完することができます。
Databricksではローカルストレージをオートスケールするため、使用コンピュートのSparkワーカーで利用可能なディスクの空き容量が監視されます。ワーカーのディスク容量が不足し始めると、Databricksはディスク容量が不足する前に、ゾーンSSD PDのサイズを自動的に変更します。Zonal-SSD PDのボリュームは、インスタンスごとに合計5 TBのディスク容量(インスタンスのローカルストレージを含む)を上限としてアタッチされます。
ストレージのオートスケールを設定するには、[ローカルストレージのオートスケールを有効化] を選択します。
デフォルトでプロビジョニングされたストレージ
Databricksは、各ワーカーノードに対して次のストレージをプロビジョニングします。
ホストオペレーティングシステムとDatabricks内部サービスによって使用される、インスタンスごとに1つのブートディスク。ブートディスクは、非GPUインスタンスでは100 GB、GPUインスタンスでは200 GBです。
Sparkワーカーによって使用されるローカルSSD。これは、Sparkサービスとログをホストします。各ローカルSSDは375GBです。アタッチされたローカルSSDの数を設定するには、ローカルSSDがあるインスタンスタイプを参照してください。
ストレージのオートスケールが有効になっている場合のリモートSSD。これらは作成時に150GBから始まり、必要に応じてオートスケールされます。
ローカルディスク暗号化
ローカルSSDを持つインスタンスタイプは、デフォルトのGoogle Cloudサーバー側暗号化で暗号化されます。ローカルSSDがあるインスタンスタイプを参照してください。
自動終了
コンピュートの自動終了を設定できます。コンピュートの作成中に、コンピュートリソースを終了するまでの非アクティブ期間を分単位で指定します。
現在の時刻とコンピュートリソースで最後のコマンドが実行された時刻の差が指定された非アクティブ期間を超える場合、Databricks はそのコンピュートを自動的に終了します。コンピュートの終了の詳細についてのリソースは、「コンピュートの終了」を参照してください。
タグ
タグを使用すれば、組織内のさまざまなグループで使用されるクラウドリソースのコストを簡単に監視できます。コンピュート作成時にタグをキーと値のペアとして指定すると、DatabricksはこれらのタグをGKEクラスタ上のDatabricks Runtimeポッドと永続ボリューム、およびDBU使用レポートに適用します。
アカウントコンソールのDatabricks請求対象使用量グラフでは、個々のタグごとに使用量を集計できます。同じページからダウンロードされた請求対象使用量CSVレポートには、デフォルトタグとカスタムタグも含まれています。タグはGKEラベルとGCEラベルにも伝播します。
プールタグタイプとコンピュートタグタイプの連携方法の詳細については、「タグを使用して使用状況を監視する」を参照してください
コンピュートリソースにタグを追加する方法は次のとおりです。
[タグ] セクションで、各カスタムタグのキーと値のペアを追加します。
[追加] をクリックします。
Googleサービスアカウント
Google Identityを使用して、このコンピュートリソースをGoogleサービスアカウントに関連付けるには、[詳細オプション] をクリックし、GoogleサービスアカウントのメールアドレスをGoogleサービスアカウントフィールドに追加します。この値は、GCSデータソースとBigQueryデータソースでの認証に使用されます。
重要
GCSおよびBigQueryデータソースへのアクセスに使用するサービスアカウントは、Databricksアカウントの設定時に指定したサービスアカウントと同じプロジェクトである必要があります。
アベイラビリティゾーン
コンピュート構成ページの詳細オプションで、コンピュートリソースのアベイラビリティーゾーンを選択します。この設定により、コンピュートリソースを使用するアベイラビリティゾーンを指定することができます。デフォルトでは、アベイラビリティゾーンは自動に設定されています。自動に設定すると、1つのアベイラビリティーゾーンが自動的に選択されます。
特定のゾーンを選択することもできます。特定のゾーンを選択することは、主に組織が特定のアベイラビリティーゾーンのリザーブドインスタンスを購入している場合に便利です。
Spark構成
Sparkジョブを微調整するために、カスタムSpark構成プロパティを指定できます。
コンピュート構成ページで、[詳細オプション] トグルをクリックします。
[Spark] タブをクリックします。
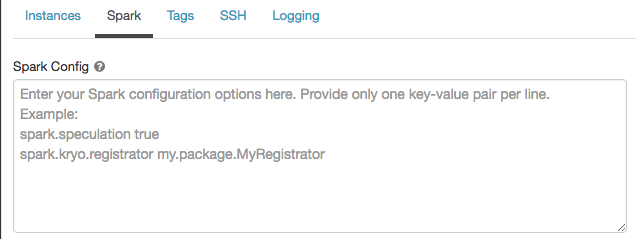
Spark構成では、1行に1つのキーと値のペアとして設定プロパティを入力します。
クラスターAPIを使用してコンピュートを構成する場合は、クラスターAPIの作成またはクラスターAPIの更新のspark_confフィールドでSparkプロパティを設定します。
ワークスペース管理者はコンピュートポリシーを使用してコンピュートにSpark構成を適用することができます。
シークレットからSpark構成プロパティを取得する
Databricksでは、パスワードなどの機密情報をプレーンテキストではなくシークレットに格納することをお勧めします。Spark構成でシークレットを参照するには、次の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
たとえば、passwordというSpark構成プロパティをsecrets/acme_app/passwordに保存されているシークレットの値に設定するには、次のようにします。
spark.password {{secrets/acme-app/password}}
詳細については、「 シークレットの管理」を参照してください。
環境変数
コンピュートリソース上で実行されるinitスクリプトからアクセスできるカスタム環境変数を設定します。Databricks には、initスクリプトで使用できる定義済みの環境変数 も用意されています。これらの定義済み環境変数を上書きすることはできません。
コンピュート構成ページで、[詳細オプション] トグルをクリックします。
[Spark] タブをクリックします。
[環境変数] フィールドで環境変数を設定します。
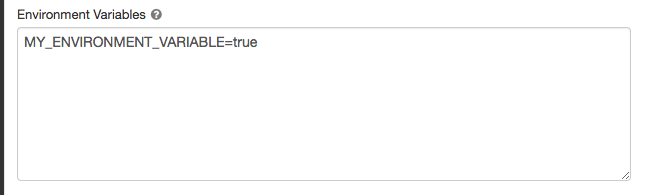
注:
ENVは予約語であり、環境変数の名前として使用することはできません。
クラスターAPIの作成またはクラスターAPIの更新のspark_env_varsフィールドを使用して環境変数を設定することもできます。
コンピュートログ配信
コンピュートを作成するときに、Spark ドライバーノード、ワーカーノード、イベントのログを配信する場所を指定できます。ログは 5 分ごとに配信され、選択した宛先に 1 時間ごとにアーカイブされます。コンピュートリソースが終了した時点で、コンピュートリソースが終了するまでの間に生成されたすべてのログを配信することを Databricks は保証します。
ログの保存先はコンピュートリソースのcluster_idによって異なります。指定された宛先がdbfs:/cluster-log-deliveryの場合、 0630-191345-leap375のコンピュートログはdbfs:/cluster-log-delivery/0630-191345-leap375に配信されます。
ログの配信場所を設定するには、以下の手順に従ってください。
コンピュートページで、[詳細オプション] トグルをクリックします。
[ロギング] タブをクリックします。
宛先タイプを選択します。
コンピュートログのパスを入力します。
ログパスは
dbfs:/で始まるDBFSパスでなければなりません。
注:
この機能は、REST APIでも使用できます。クラスターAPIを参照してください。