ジョブコンピュートの設定
この記事には、 Databricks ジョブのコンピュートを構成するための推奨事項とリソースが含まれています。
重要
ジョブ用サーバレスコンピュートには、次のような制限があります。
継続的なスケジューリングはサポートされていません。
構造化ストリーミングでは、デフォルトまたは時間ベースのインターバルトリガーはサポートされていません。
その他の制限事項については、 サーバレス コンピュートの制限事項を参照してください。
各ジョブには、1 つ以上のタスクを含めることができます。 コンピュート リソースは、タスクごとに定義します。 同じジョブに対して定義された複数のタスクは、同じコンピュート リソースを使用できます。
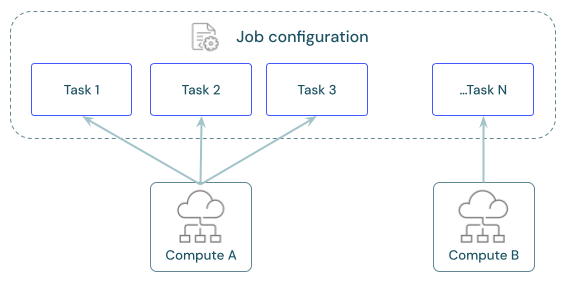
各タスクの推奨コンピュートは?
次の表は、各タスクの種類で推奨およびサポートされているコンピュートの種類を示しています。
タスク |
おすすめコンピュート |
対応コンピュート |
|---|---|---|
ノートブック |
クラシックジョブ |
クラシックジョブ、クラシック万能 |
Pythonスクリプト |
クラシックジョブ |
クラシックジョブ、クラシック万能 |
Python Wheel |
クラシックジョブ |
クラシックジョブ、クラシック万能 |
dbt |
サーバレス SQLウェアハウス |
サーバレス SQLウェアハウス, pro SQLウェアハウス |
dbt CLI コマンド |
クラシックジョブ、クラシック万能 |
|
JAR |
クラシックジョブ |
クラシックジョブ、クラシック万能 |
Spark Submit |
クラシックジョブ |
クラシックジョブ |
ジョブの価格は、タスクの実行に使用されるコンピュートに関連付けられています。 詳細については、「 Databricks の価格」を参照してください。
ジョブコンピュートの設定方法
ジョブ コンピュートは、 Databricks ジョブ UI から直接構成します。 これらの構成は、ジョブ定義の一部です。 他のすべての使用可能なコンピュート タイプは、次の表に示すように、他のワークスペース アセットと共に構成を格納します。
クラスタータイプ |
詳細 |
|---|---|
Jobs コンピュート |
ジョブのコンピュートは、汎用コンピュートと同じUIと設定を使用して設定します。 コンピュート設定リファレンスを参照してください。 |
SQLウェアハウス |
サーバレスと Pro SQLウェアハウスは、ワークスペース管理者または無制限のクラスター作成権限を持つユーザーによって構成されます。 既存の SQLウェアハウスに対してタスクを実行するように構成します。 「SQLウェアハウスへの接続」を参照してください。 |
Delta Live Tables パイプライン コンピュート |
Delta Live Tables パイプラインのコンピュート設定は、パイプラインの設定時に構成します。Delta Live Tables パイプラインのコンピュートの設定を参照してください。 |
汎用コンピューティング |
オプションで、従来の汎用コンピュートに対してタスクを構成できます。 Databricks では、この構成を本番運用ジョブにはお勧めしません。 「コンピュート設定リファレンス」および「汎用コンピュートをジョブに使用すべきか」を参照してください。 |
ジョブコンピュートのレビュー、設定、切り替え
ジョブ詳細パネルのコンピュートセクションには、現在のジョブのタスクに設定されたすべてのコンピュートが一覧表示されます。
コンピュート リソースを使用するように構成されたタスクは、コンピュート仕様にカーソルを合わせると、タスク グラフで強調表示されます。
スワップ ボタンを使用して、コンピュート リソースに関連付けられているすべてのタスクのコンピュートを変更します。
クラシック ジョブ コンピュート リソースには [構成] オプションがあります。 その他のコンピュート リソースには、コンピュート構成の詳細を表示および変更するオプションがあります。
クラシック ジョブ コンピュートの構成に関する推奨事項
このセクションでは、一部のワークフローに役立つ機能と構成に関する一般的な推奨事項に焦点を当てます。 コンピュート リソースのサイズとタイプを設定するための具体的な推奨事項は、ワークロードによって異なります。
Databricks では、 Photon アクセラレーションを有効にし、最新の Databricks Runtime バージョンを使用し、 Unity Catalog用に構成されたコンピュートを使用することをお勧めします。
手記
構造化ストリーミングワークフローには、特定の推奨事項があります。 構造化ストリーミングについては、本番運用に関する考慮事項を参照してください。
クラスターポリシーを使用する
Databricks では、ワークスペース管理者がジョブのクラスターポリシーを定義し、ジョブを構成するすべてのユーザーにこれらのポリシーを適用することをお勧めします。
クラスターポリシー ワークスペース管理者がコスト管理を設定し、ユーザーの構成オプションを制限できるようにします。 クラスターポリシーの設定の詳細については、「 コンピュート ポリシーの作成と管理」を参照してください。
Databricks は、ジョブ用に構成されたデフォルト ポリシーを提供します。 管理者は、このポリシーを他のワークスペース ユーザーが使用できるようにすることができます。 ジョブ コンピュートを参照してください。
オートスケールを使う
オートスケールを構成して、実行時間の長いタスクがジョブの実行中にワーカーノードを動的に追加および削除できるようにします。 「オートスケールを有効にする」を参照してください。
プールを使用してクラスターの起動時間を短縮する
コンピュート プールを使用すると、クラウド プロバイダーからコンピュート リソースを予約できます。 プールは、新しいジョブ クラスターの開始時間を短縮し、コンピュート リソースの可用性を確保するのに役立ちます。 「プール構成リファレンス」を参照してください。
プリエンプティブル インスタンスを使用する
レイテンシー要件が緩いワークロードに対してプリエンプティブルインスタンスを構成して、コストを最適化します。 プリエンプティブル・インスタンスを参照してください。
アベイラビリティゾーンの構成
アベイラビリティゾーン (AZ) は、組織がリザーブドインスタンスを購入した場合は指定します。 「アベイラビリティゾーン」を参照してください。
汎用コンピュートはジョブに使うべきか
Databricksがジョブに汎用コンピュートを使用しないことを推奨する理由は、次のように数多くあります。
Databricks 汎用コンピュートの請求書は、ジョブコンピュートとは異なるレートでお支払いいただけます。
ジョブ コンピュートは、ジョブの実行が完了すると自動的に終了します。 汎用コンピュートは、ジョブ実行の終了ではなく、非アクティブに関連付けられた自動終了をサポートしています。
汎用コンピュートは、多くの場合、ユーザーのチーム間で共有されます。 汎用コンピュートに対してスケジュールされたジョブは、コンピュート リソースの競合により、多くの場合、待機時間が長くなります。
ジョブ コンピュートの構成を最適化するための多くの推奨事項は、汎用コンピュートで実行されるアドホック クエリや対話型ワークロードの種類には適していません。
次に、ジョブに汎用コンピュートを使用することを選択するユースケースを示します。
新しいジョブを繰り返し開発またはテストしています。 ジョブコンピュートの起動時間が長いと、反復開発が面倒になる可能性があります。 汎用コンピュートを使用すると、変更を適用してジョブをすばやく実行できます。
短期間のジョブがあり、頻繁に実行したり、特定のスケジュールで実行したりする必要があります。 現在実行中の汎用コンピュートに関連付けられた起動時間はありません。 このパターンを使用する場合は、アイドル時間に関連するコストを考慮してください。