サーバレス コンピュート for ワークフローを使用してDatabricksジョブを実行する
重要
ワークフロー用サーバレス コンピュートは送信トラフィックの制御をサポートしていないため、ジョブはインターネットに完全にアクセスできます。
サーバーレス コンピュート for ワークフローを使用すると、インフラストラクチャの構成やデプロイを行わずにDatabricksジョブを実行できます。 サーバーレス コンピュートを使用すると、データ処理と分析パイプラインの実装に集中でき、 Databricksワークロードに合わせたコンピュートの最適化やスケーリングなど、コンピュート リソースを効率的に管理します。 オートスケールとPhoton 、ジョブを実行するコンピュート リソースに対して自動的に有効になります。
サーバレス コンピュート for ワークフロー は、インスタンスタイプ、メモリ、処理エンジンなどのインフラストラクチャを自動的かつ継続的に最適化し、ワークロードの特定の処理要件に基づいて最高のパフォーマンスを確保します。
Databricks は、Databricks ジョブの安定性を確保しながら、プラットフォームの機能強化とアップグレードをサポートするために、Databricks Runtime バージョンを自動的にアップグレードします。 ワークフローで使用されている現在のDatabricks Runtimeバージョンを確認するには、サーバレス コンピュート リリースノート参を照してください。
クラスター作成権限が不要なため、すべてのワークスペースユーザーがサーバレスコンピュートを利用してワークフローを実行できます。
この記事では、 Databricks Jobs UI を使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法について説明します。 Jobs API 、 Databricks Asset Bundles、 Databricks SDK for Pythonを使用して、サーバレス コンピュートを使用するジョブの作成と実行を自動化することもできます。
APIジョブ を使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法については、 リファレンスの 「ジョブ」 RESTAPIを参照してください。
Databricks Asset Bundles を使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法については、「Databricks Asset Bundles を使用して Databricks でジョブを開発する」を参照してください。
Databricks SDK for Pythonを使用して、サーバーレス コンピュートを使用するジョブを作成および実行する方法については、 Databricks SDK for Pythonを参照してください。
要件
Databricks ワークスペースで Unity Catalog が有効になっている必要があります。
サーバレス コンピュート for ワークフローは共有アクセス モードを使用するため、ワークロードがこのアクセス モードをサポートしている必要があります。
Databricks ワークスペースは、サポートされているリージョンに存在する必要があります。 「地域限定での提供が可能な機能」を参照してください。
Databricks アカウントでサーバレス コンピュートが有効になっている必要があります。Enable サーバレス コンピュートを参照してください。
サーバレスコンピュートを使用してジョブを作成する
注:
ワークフローのサーバーレス コンピュートでは、ワークロードを実行するための十分なリソースがプロビジョニングされることが保証されるため、大量のメモリを必要とするか、多くのタスクを含むDatabricksジョブを実行する場合、起動時間の増加が発生する可能性があります。
サーバレス コンピュートは、ノートブック、 Python スクリプト、 dbt、 Python wheel タスク タイプでサポートされています。 デフォルトでは、新しいジョブを作成し、これらのサポートされているタスクタイプのいずれかを追加するときに、サーバレス コンピュートがコンピュートタイプとして選択されます。
Databricks 、すべてのジョブ タスクにサーバーレス コンピュートを使用することをお勧めします。 ジョブ内のタスクにさまざまなコンピュート タイプを指定することもできます。これは、タスク タイプがワークフローのサーバレス コンピュートでサポートされていない場合に必要になる場合があります。
サーバレスコンピュートを使用するように既存のジョブを構成する
既存のジョブを切り替えて、サポートされているタスクタイプにサーバレス コンピュートを使用するように切り替えることができます。 サーバレス コンピュートに切り替えるには、次のいずれかを実行します。
[ジョブの詳細]サイド パネルで、 [コンピュート]の下の[スワップ]をクリックし、 [新規]をクリックし、設定を入力または更新して、 [更新]をクリックします。
クリック
 コンピュートドロップダウン メニューで[サーバレス]を選択します。
コンピュートドロップダウン メニューで[サーバレス]を選択します。

サーバレスコンピュートを使用してノートブックをスケジュールする
ジョブ UI を使用して、サーバレス コンピュートを使用するジョブを作成およびスケジュールするだけでなく、 Databricksノートブックから直接サーバレス コンピュートを使用するジョブを作成して実行することもできます。 「スケジュールされたノートブック ジョブの作成と管理」を参照してください。
サーバレス利用に対する予算ポリシーの選択
プレビュー
この機能はパブリックプレビュー段階です。
予算ポリシー を使用すると、組織はサーバレスの使用状況にカスタムタグを適用して、詳細な請求の按分を実現できます。
ワークスペースで 予算ポリシー を使用してサーバレスの使用状況を属性付けしている場合は、ジョブの詳細 UI の 予算ポリシー 設定を使用して、ジョブの 予算ポリシー を選択できます。 1 つの予算ポリシーにのみ割り当てられている場合、そのポリシーは新しいジョブに対して自動的に選択されます。
注:
予算ポリシーが割り当てられた後、既存のジョブはポリシーで自動的にタグ付けされません。 既存のジョブにポリシーをアタッチする場合は、既存のジョブを手動で更新する必要があります。
予算ポリシーの詳細については、 予算ポリシーによるサーバレス使用料の按分を参照してください。
Spark構成を設定する
サーバレス コンピュートでの Spark の設定を自動化するために、 Databricks では特定の Spark 設定パラメータのみを設定できます。 許容されるパラメーターのリストについては、 サポートされる Spark 構成パラメーターを参照してください。
Spark構成はセッションレベルでのみ設定できます。 これを行うには、それらをノートブックに設定し、そのノートブックを、その 引数 を使用する同じ ジョブ に含まれるタスクに追加します。 「ノートブックで Apache Spark 構成プロパティを取得および設定する」を参照してください。
環境と依存関係を構成する
サーバレス コンピュートを使用してライブラリと依存関係をインストールする方法については、 ノートブック dependencies のインストールを参照してください。
再試行を禁止するようにサーバーレス コンピュートの自動最適化を構成する
サーバレス コンピュート for ワークフローの自動最適化処理 は、ジョブの実行に使用されたコンピュートを自動的に最適化し、失敗したタスクを再試行します。 自動最適化はデフォルトで有効になっており、Databricks では、重要なワークロードが少なくとも 1 回は正常に実行されるように、有効のままにしておくことをお勧めします。 ただし、べき等でないジョブなど、最大で一度に実行する必要があるワークロードがある場合は、タスクを追加または編集するときに自動最適化をオフにできます。
再試行の横にある追加(または
 (再試行ポリシーがすでに存在する場合)。
(再試行ポリシーがすでに存在する場合)。[再試行ポリシー]ダイアログで、 [サーバーレス自動最適化を有効にする (追加の再試行が含まれる場合があります)]のチェックを外します。
[確認]をクリックします。
タスクを追加する場合は、 「タスクの作成」をクリックします。 タスクを編集している場合は、 「タスクを保存」をクリックします。
ワークフロー用サーバレスコンピュートを使用したジョブのコストを監視する
ワークフローのサーバレスコンピュートを使用するジョブのコストは、課金利用システムテーブルをクエリすることで監視できます。 この表は、サーバーレス コストに関するユーザーおよびワークロード属性を含めるように更新されます。 料金利用システムテーブルリファレンス を参照してください。
現在の価格とプロモーションに関する情報については、 ワークフロー 価格 ページを参照してください。
ジョブ実行のクエリ詳細を表示する
Spark ステートメントの詳細なランタイム情報 (メトリクスやクエリプランなど) を表示できます。
ジョブ UI からクエリの詳細にアクセスするには、次の手順を使用します。
サイドバーの
 [ワークフロー]をクリックします。
[ワークフロー]をクリックします。表示するジョブの名前をクリックします。
表示する特定の実行をクリックします。
[タイムライン] をクリックすると、実行がタイムラインとして表示され、個々のタスクに分割されます。
タスク名の横にある矢印をクリックすると、クエリステートメントとそのランタイムが表示されます。
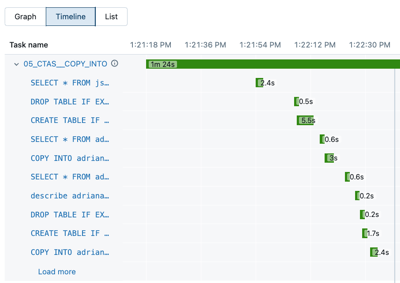
ステートメントをクリックして、 クエリの詳細 パネルを開きます。 このパネルで使用できる情報の詳細については、「 クエリの詳細の表示 」を参照してください。
タスクのクエリ履歴を表示するには:
[タスク実行]サイド パネルの[コンピュート]セクションで、 [クエリ履歴]をクリックします。
あなたが参加していたタスクのタスク実行 ID に基づいて事前にフィルタリングされた、書き込みー履歴にリダイレクトされます。
クエリ履歴の使用に関する情報については、「Delta Live Tables パイプラインのクエリ履歴へのアクセス」および「クエリ履歴」を参照してください。
制限事項
ワークフローの制限事項の一覧については、サーバレス コンピュート リリースノートの 「サーバレス コンピュート 制限事項」を参照してください。