コンピュートのメトリクスを表示する
この記事では、 Databricks UI のネイティブ コンピュート メトリック ツールを使用して主要なハードウェアとSparkメトリックを収集する方法について説明します。 メトリクスUIは汎用・ジョブコンピュートで使用可能です。
メトリクスはほぼリアルタイムで利用可能で、通常の遅延は 1 分未満です。 メトリクスは、顧客のストレージではなく、Databricks が管理するストレージに保存されます。
これらの新しいメトリクスは Ganglia と何が異なるか
新しいコンピュートメトリック UI では、 Spark消費量や内部Databricksプロセスなど、クラスターのリソース使用状況をより包括的に確認できます。 対照的に、Ganglia UI は Spark コンテナの消費量のみを測定します。 この違いにより、2 つのインターフェース間のメトリック値に不一致が生じる可能性があります。
コンピュート メトリクス UI にアクセスする
コンピュート メトリクス UI を表示するには:
サイドバーの 「コンピュート 」をクリックします。
メトリクスを表示するコンピュート リソースをクリックします。
[メトリクス] タブをクリックします。
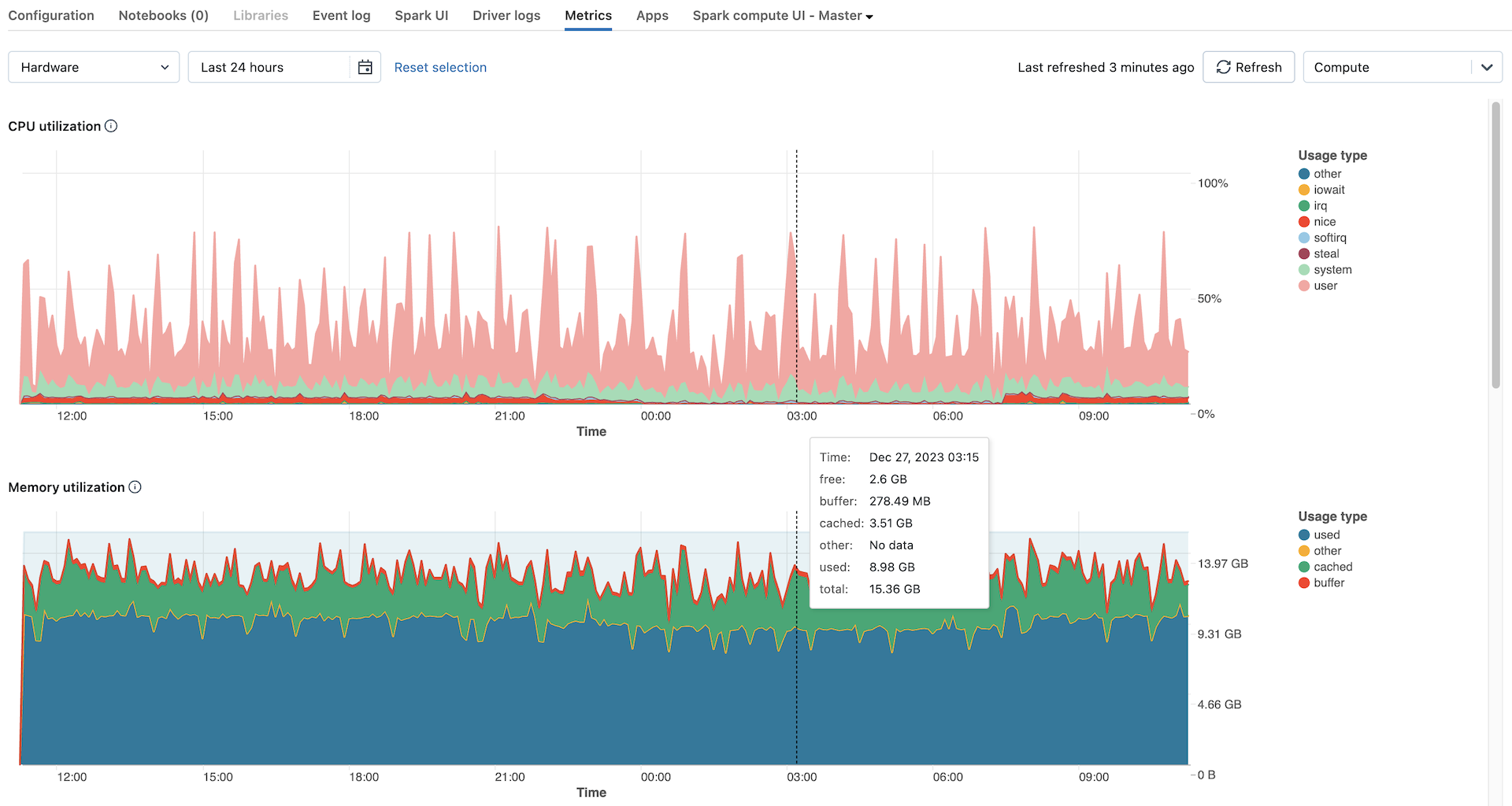
ハードウェアメトリックは デフォルト で示されます。 Sparkメトリクスを表示するには、 「ハードウェア」というドロップダウン メニューをクリックし、 Sparkを選択します。 インスタンスが GPU 対応の場合は、[ GPU] を選択することもできます。
期間によるメトリクスのフィルタリング
過去のメトリクスを表示するには、日付ピッカーフィルターを使用して時間範囲を選択します。 メトリクスは毎分収集されるため、過去 30 日間の任意の範囲の日、時間、分でフィルター処理できます。 カレンダー アイコンをクリックして定義済みのデータ範囲から選択するか、テキスト ボックス内をクリックしてカスタム値を定義します。
注
グラフに表示される時間間隔は、表示している時間の長さに基づいて調整されます。 ほとんどのメトリクスは、現在表示している時間間隔に基づく平均です。
[リフレッシュ]ボタンをクリックして最新のメトリックを取得することもできます。
ノードレベルでのメトリクスの表示
コンピュートドロップダウンメニューをクリックし、メトリクスを表示するノードを選択すると、個々のノードのメトリクスを表示できます。 GPU メトリックは個々のノード レベルでのみ利用可能です。 Sparkは個々のノードでは使用できません。
注
特定のノードを選択しない場合、結果はクラスター内のすべてのノード(ドライバーを含む)にわたって平均化されます。
ハードウェアメトリクスチャート
コンピュート メトリクス UI では、次のハードウェア メトリクス チャートを表示できます。
サーバーの負荷分布: このグラフには、各ノードの過去 1 分間の CPU 使用率が表示されます。
CPU 使用率: 合計 CPU 秒コストに基づく、各モードで CPU が費やした時間の割合。メトリクスは、グラフに表示されている時間間隔に基づいて平均化されます。 追跡モードは次のとおりです。
guest: VM を実行している場合、それらの VM が使用する CPU
iowait: I/O の待機にかかった時間
idle: CPU が何もしなかった時間
irq: 割り込み要求にかかった時間
nice: 正の nice ネスを持つプロセス (他のタスクよりも優先度が低い) によって使用された時間
softirq: ソフトウェア割り込み要求にかかった時間
steal: VM の場合は、他の VM が CPU から "盗む" 時間を計ります
system: カーネルで費やされた時間
user: ユーザーランドで費やした時間
メモリ使用率: 各モードごとの合計メモリ使用量で、バイト単位で測定され、グラフに表示される時間間隔に基づいて平均化されます。 次の使用タイプが追跡されます。
used: 使用済みメモリ (コンピュート上で実行されているバックグラウンド プロセスによって使用されるメモリを含む)
free: 未使用のメモリ
buffer: カーネルバッファが使用するメモリ
cached: OSレベルでファイルシステムキャッシュによって使用されるメモリ
メモリ スワップ使用率: 各モードごとのメモリ スワップ使用量の合計で、バイト単位で測定され、グラフに表示される時間間隔に基づいて平均化されます。
ファイル・システム・スペースの空き領域: 各マウント・ポイントによるファイル・システムの合計使用量で、バイト単位で測定され、グラフに表示される時間間隔に基づいて平均化されます。
ネットワーク経由で受信: 各デバイスがネットワーク経由で受信したバイト数で、グラフに表示される時間間隔に基づいて平均化されます。
ネットワーク経由で送信: 各デバイスによってネットワーク経由で送信されたバイト数で、グラフに表示される時間間隔に基づいて平均化されます。
アクティブなノードの数: 指定されたコンピュートのタイムスタンプごとのアクティブなノードの数を示します。
Spark メトリクスチャート
次の Spark メトリクス チャートは、コンピュート メトリクス UI で表示できます。
サーバーの負荷分布: このグラフには、各ノードの過去 1 分間の CPU 使用率が表示されます。
アクティブなタスク: 任意の時点で実行されているタスクの合計数で、グラフに表示される時間間隔に基づいて平均化されます。
失敗したタスクの合計: エグゼキューターで失敗したタスクの合計数で、グラフに表示される時間間隔に基づいて平均化されます。
完了したタスクの合計: エグゼキューターで完了したタスクの合計数で、グラフに表示される時間間隔に基づいて平均化されます。
タスクの総数: エグゼキューター内のすべてのタスク (実行中、失敗、完了) の合計数で、グラフに表示されている時間間隔に基づいて平均化されます。
合計シャッフル読み取り: シャッフル読み取りデータの合計サイズで、バイト単位で測定され、グラフに表示される時間間隔に基づいて平均化されます。
Shuffle readは、ステージの開始時にすべてのエグゼキューターで直列化された読み取りデータの合計を意味します。合計シャッフル書き込み: シャッフル書き込みデータの合計サイズ (バイト単位で測定され、グラフに表示される時間間隔に基づいて平均化されます)。
Shuffle Writeは、送信前 (通常はステージの終了時) にすべてのエグゼキューターに書き込まれたすべてのシリアル化されたデータの合計です。Total task duration: JVMがエグゼキューターでタスクの実行に費やした合計経過時間(秒単位で測定され、グラフに表示される時間間隔に基づいて平均化されます)。
GPU メトリクスチャート
注
GPU メトリクスは、 Databricks Runtime ML 13.3 以降でのみ使用できます。
次の GPU メトリクス チャートは、コンピュート メトリクス UI で表示できます。
サーバーの負荷分布: このグラフには、各ノードの過去 1 分間の CPU 使用率が表示されます。
GPU デコーダーごとの使用率: グラフに表示される時間間隔に基づいて平均化された GPU デコーダー使用率の割合。
GPU ごとのエンコーダー使用率: グラフに表示される時間間隔に基づいて平均化された GPU エンコーダー使用率の割合。
GPU ごとのフレーム バッファー メモリ使用率バイト: バイト単位で測定され、グラフに表示される時間間隔に基づいて平均化されたフレーム バッファー メモリ使用率。
GPU ごとのメモリ使用率: グラフに表示される時間間隔に基づいて平均化された GPU メモリ使用率の割合。
GPU あたりの使用率: グラフに表示される時間間隔に基づいて平均化された GPU 使用率の割合。