Google BigQuery
この記事では、Databricks で Google BigQuery テーブルの読み取りと書き込みを行う方法について説明します。
実験段階
この記事で説明する構成は 実験的です。 実験的な機能は現状のまま提供され、Databricks による顧客テクニカル サポートを通じてサポートされることはありません。 完全なクエリ フェデレーション サポートを取得するには、代わりにレイクハウス フェデレーションを使用する必要があります。これにより、 DatabricksユーザーはUnity Catalog構文とデータガバナンス ツールを活用できるようになります。
Databricks では、BigQuery に対する認証にサービス アカウントの Eメール認証を使用することを推奨しています。 この記事では、キーベースの認証もオプションとして取り上げていますが、キーが漏洩するリスクがあるため、安全性が低くなります。
権限
プロジェクトには、BigQuery を使用して読み書きするための特定の Google 権限が必要です。
注:
この記事では、BigQuery のマテリアライズドビューについて説明します。 詳細については、Google の記事「 マテリアライズドビューの概要」を参照してください。 BigQuery のその他の用語と BigQuery のセキュリティ モデルについては、 Google BigQuery のドキュメントをご覧ください。
BigQuery でのデータの読み取りと書き込みは、次の 2 つの Google Cloud プロジェクトに依存します。
プロジェクト (
project): Databricks が BigQuery テーブルを読み書きする Google Cloud プロジェクトの ID。親プロジェクト (
parentProject): 親プロジェクトの ID で、Databricks ワークスペースがデプロイされている Google サービス アカウントに関連付けられている Google クラウド プロジェクトに対してデフォルトです。
これらの値を明示的に指定しない場合、両方の値は、認証に使用するサービスアカウントに関連付けられたプロジェクトにデフォルト設定されます。 これは、サービスアカウントのEメールアドレス(推奨される方法)またはキーJSONファイルの両方の認証方法に適用されます。
必要に応じて project と parentProject を明示的に設定するには、次のようなコードで使用します。 <project-id> をプロジェクト ID に置き換えます。<parent-project-id> を親プロジェクト ID に置き換えます。
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Google Cloud プロジェクトに必要な権限は、 project と parentProject が同じかどうかによって異なります。 次のセクションでは、各シナリオに必要なアクセス許可を示します。
projectとparentProjectが一致する場合に必要なアクセス許可
project と parentProject の ID が同じ場合は、次の表を使用して最小限のアクセス許可を決定します。
Databricks タスク |
プロジェクトに必要な Google の権限 |
|---|---|
マテリアライズドビューなしで BigQuery テーブルを読み取る |
|
マテリアライズドビューを使用した BigQuery テーブルの読み取り |
具体化プロジェクトでは、次の操作を行います。
|
BigQuery テーブルを記述する |
|
projectとparentProjectが異なる場合に必要な権限
project と parentProject の ID が異なる場合は、次の表を使用して最小アクセス許可を決定します。
Databricks タスク |
必要な Google の権限 |
|---|---|
マテリアライズドビューなしで BigQuery テーブルを読み取る |
|
マテリアライズドビューを使用した BigQuery テーブルの読み取り |
具体化プロジェクトでは、次の操作を行います。
|
BigQuery テーブルを記述する |
|
ステップ1: Googleクラウドを設定する
BigQuery Storage APIを有効にする
BigQuery Storage API は、BigQuery が有効になっている新しい Google Cloud プロジェクトではデフォルトで有効になっています。 ただし、既存のプロジェクトがあり、BigQuery Storage API が有効になっていない場合は、このセクションのステップに沿って有効にしてください。
BigQuery Storage API は、Google Cloud CLI または Google Cloud Console を使用して有効にできます。
DatabricksのGoogleサービスアカウントを作成する
Databricks クラスターのサービス アカウントを作成します。 Databricks では、このサービス アカウントに、タスクの実行に必要な最小限の特権を付与することをお勧めします。 詳しくは、BigQuery のロールと権限をご覧ください。
サービスアカウントは、Google Cloud CLI または Google Cloud コンソールを使用して作成できます。
Google Cloud CLIを使用して Google サービス アカウントを作成する
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Databricks では、サービス アカウントの Eメール認証の使用が推奨されていますが、キーベースの認証を使用する場合は、次の手順でサービス アカウントのキーを作成します。
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Google Cloudコンソールを使用して Google サービスアカウントを作成する
アカウントを作成するには:
左側のナビゲーションペインで [ IAM and Admin ] をクリックします。
「 サービス・アカウント」をクリックします。
[+ CREATE サービス アカウント] をクリックします。
サービス アカウントの名前と説明を入力します。
[作成]をクリックします。
サービスアカウントのロールを指定します。 [ ロールの選択 ] ドロップダウンに「
BigQuery」と入力し、次のロールを追加します。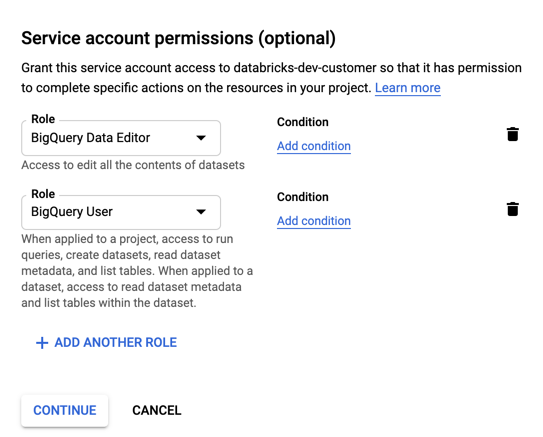
「続行」をクリックします。
[完了] をクリックします。
Databricks では、サービス アカウントの Eメール認証の使用が推奨されていますが、キーベースの認証を使用する場合は、次の手順でサービス アカウントのキーを作成します。
サービス アカウントの一覧で、新しく作成したアカウントをクリックします。
[キー] セクションで、 [キーの追加] > [新しいキーの作成 ] ボタンを選択します。
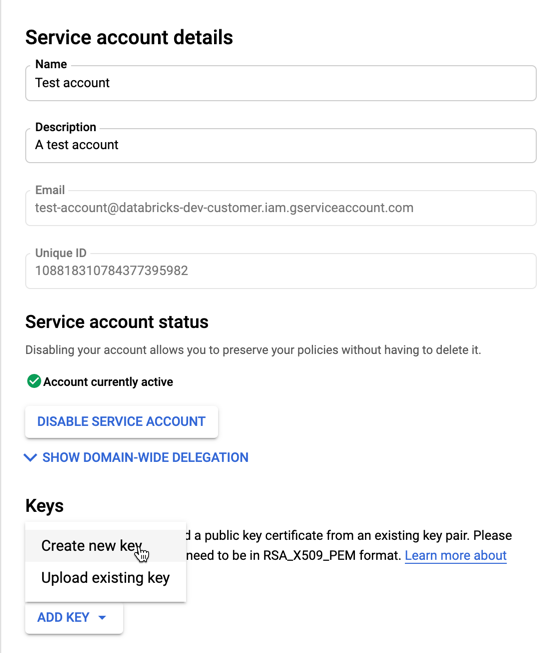
JSON キーの種類を受け入れます。
「作成」をクリックします。JSON キー ファイルがコンピューターにダウンロードされます。
重要
サービス アカウント用に生成する JSON キー ファイルは、Google Cloud アカウントのデータセットとリソースへのアクセスを制御するため、許可されたユーザーとのみ共有する必要がある秘密鍵です。
ステップ 2: Databricks を設定する
Databricks では、サービス アカウントの Eメール認証の使用が推奨されていますが、キーベースの認証の手順もここに含まれています。
サービスアカウントを使用したクラスターのセットアップ Eメールアドレス(推奨)
クラスタリング エディタを使用して クラスタリングを設定する 場合は、[ 詳細設定 ] をクリックして [Google サービス アカウント ] をサービス アカウント Eメール アドレスに設定します。
キーベースの認証を使用したクラスターのセットアップ
クラスタリングエディタを使用してクラスタリングを設定する場合は、[詳細設定]をクリックし、[Spark ]タブをクリックして、次のSpark設定を追加します。<base64-keys> を Base64 でエンコードされた JSON キーファイルに置き換えます。括弧内の他の項目 ( <client-email>など) を、JSON キーファイルのフィールドの値に置き換えます。
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
BigQuery テーブルの読み取りと書き込み
BigQuery テーブルを読み取るには、
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
BigQuery テーブルに書き込むには、
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
ここで、 <bucket-name>は、「一時ストレージ用の Google Cloud Storage (GCS) バケットを作成する」で作成したバケットの名前です。 <project-id>と<parent-id>値の要件については、「アクセス許可」を参照してください。
BigQueryから外部テーブルを作成する
重要
この機能は、Unity Catalog ではサポートされていません。
BigQuery から直接データを読み取るアンマネージド テーブルを Databricks で宣言できます。
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)