BigQuery
Este artigo descreve como ler e gravar em tabelas do Google BigQuery no Databricks.
Experimental
As configurações descritas neste artigo são Experimentais. Os recursos experimentais são fornecidos como estão e não são suportados pelo Databricks por meio do suporte técnico ao cliente. Para obter suporte completo à federação query , você deve usar lakehouse Federation, que permite que os usuários do Databricks aproveitem a sintaxe do Unity Catalog e as ferramentas de governança de dados.
A Databricks recomenda usar a autenticação de email account de serviço para autenticar no BigQuery. a autenticação baseada em keytambém é abordada como uma opção neste artigo, mas é menos segura com o risco de vazamento da key.
Permissões
Seus projetos precisam ter permissões específicas do Google para leitura e gravação usando o BigQuery.
Observação
Este artigo discute view materializada do BigQuery. Para obter detalhes, consulte os artigos do Google Introdução à viewmaterializada. Para aprender outra terminologia do BigQuery e o modelo de segurança do BigQuery, consulte a documentação do Google BigQuery.
A leitura e gravação de dados com o BigQuery depende de dois projetos clouds do Google:
Projeto (
project): o ID do projeto clouds do Google do qual o Databricks lê ou grava a tabela do BigQuery.Projeto pai (
parentProject): o ID do projeto pai, cujo default é o projeto clouds do Google associado à account de serviço do Google na qual seu workspace do Databricks está implantado.
Se você não fornecer esses valores explicitamente, ambos os valores default para o projeto associado à account de serviço usada para autenticação. Isso se aplica a ambos os métodos de autenticação: um endereço de serviço account email (a abordagem recomendada) ou um key arquivo JSON .
Para definir explicitamente project e parentProject , use com um código semelhante ao seguinte. Substitua <project-id> pelo ID do seu projeto. Substitua <parent-project-id> pelo ID do projeto pai.
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
As permissões necessárias para os projetos clouds do Google dependem de project e parentProject serem iguais. As seções a seguir listam as permissões necessárias para cada cenário.
Permissões necessárias se project e parentProject corresponderem
Se os IDs de project e parentProject forem iguais, use a tabela a seguir para determinar as permissões mínimas:
Tarefa Databricks |
Permissões do Google necessárias no projeto |
|---|---|
Ler uma tabela do BigQuery sem viewmaterializada |
No projeto
|
Ler uma tabela do BigQuery com viewmaterializada |
No projeto
No projeto de materialização:
|
Escreva uma tabela do BigQuery |
No projeto
|
Permissões necessárias se project e parentProject forem diferentes
Se os IDs de project e parentProject forem diferentes, use a tabela a seguir para determinar as permissões mínimas:
Tarefa Databricks |
Permissões do Google necessárias |
|---|---|
Ler uma tabela do BigQuery sem viewmaterializada |
No projeto
No projeto
|
Ler uma tabela do BigQuery com viewmaterializada |
No projeto
No projeto
No projeto de materialização:
|
Escreva uma tabela do BigQuery |
No projeto
No projeto
|
passo 1: configurar o Google Cloud
Ativar a API BigQuery Storage
A API BigQuery Storage é ativada por default em novos projetos cloud do Google nos quais o BigQuery está ativado. No entanto, se você tiver um projeto existente e a API BigQuery Storage não estiver ativada, siga as passos nesta seção para ativá-la.
Você pode ativar a API BigQuery Storage usando a Google clouds CLI ou o Google clouds Console.
Ative a API BigQuery Storage usando Google clouds CLI
gcloud services enable bigquerystorage.googleapis.com
Ative a API BigQuery Storage usando o console do Google clouds
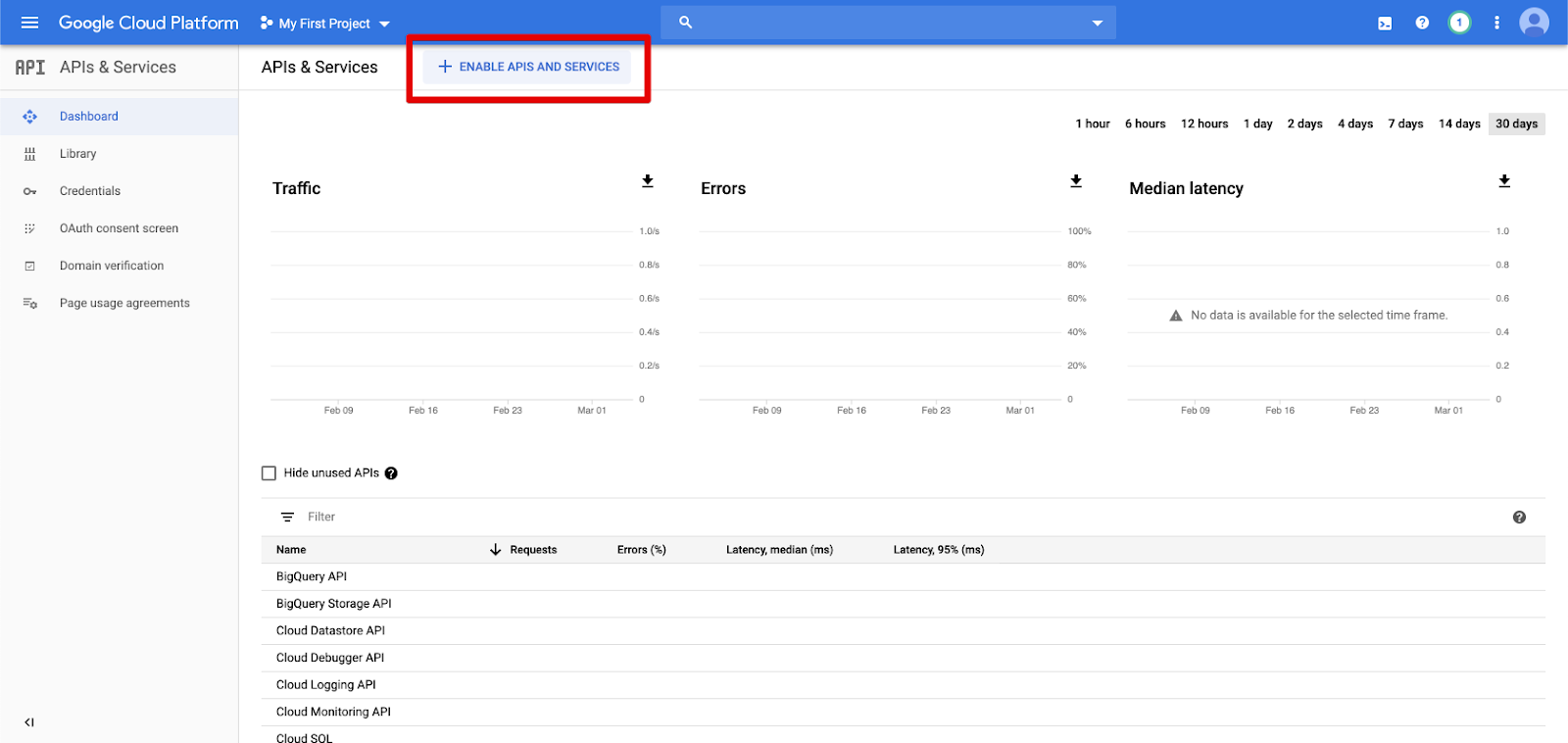
Clique em APIs e serviços no painel de navegação esquerdo.
Clique no botão ATIVAR APIS E SERVIÇO .
Digite
bigquery storage apina barra de pesquisa e selecione o primeiro resultado.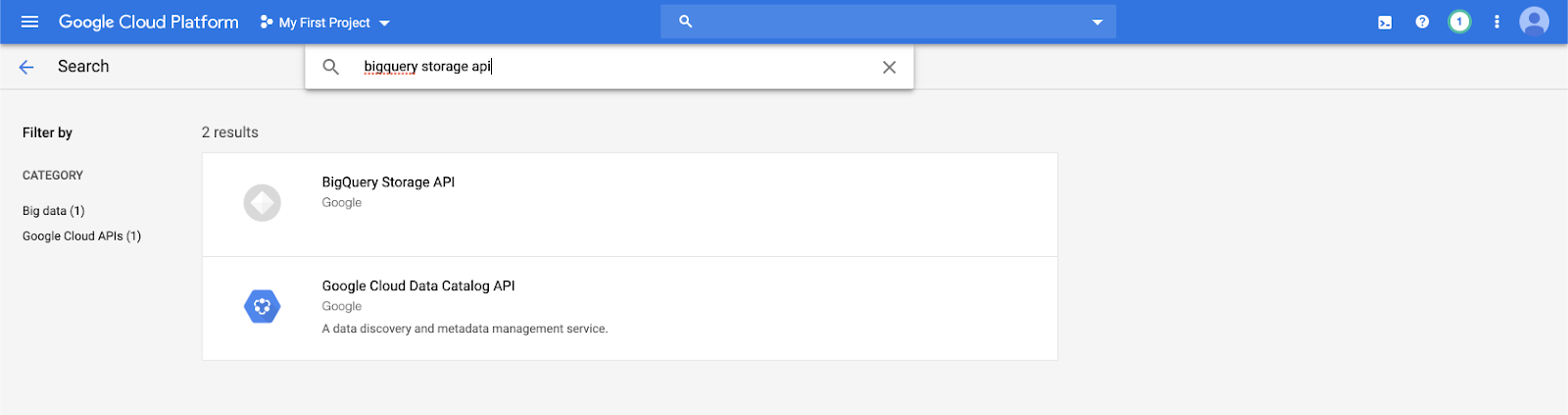
Certifique-se de que a API BigQuery Storage esteja ativada.
Crie uma conta de serviço do Google para Databricks
Crie uma account de serviço para os clusters do Databricks. A Databricks recomenda atribuir a esta account de serviço os privilégios mínimos necessários para executar a sua tarefa. Consulte Funções e permissões do BigQuery.
Você pode criar uma account de serviço usando a CLI do Google clouds ou o Console do Google clouds .
Crie uma conta de serviço do Google usando Google clouds CLI
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
A Databricks recomenda usar a autenticação de email account de serviço, mas se você optar por usar a autenticação baseada em key , crie a key para sua account de serviço fazendo o seguinte:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Crie uma conta de serviço do Google usando o console do Google clouds
Para criar a account:
Clique em IAM e Admin no painel de navegação esquerdo.
Clique em accountde serviço.
Clique em + CRIAR accountde serviço.
Insira o nome e a descrição account de serviço.
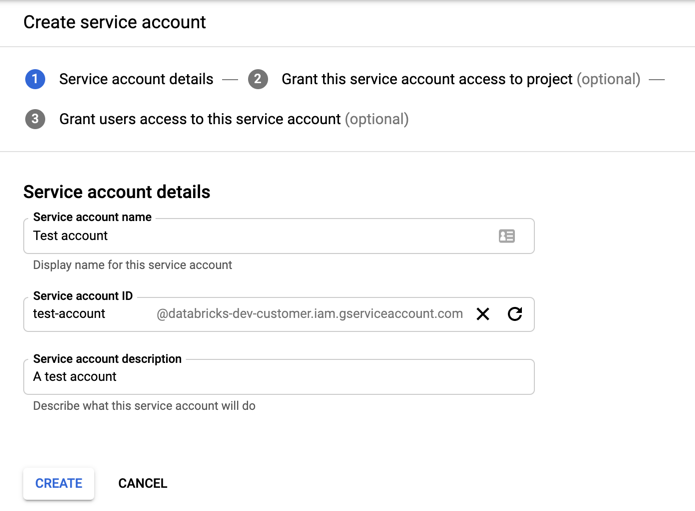
Clique em Criar.
Especifique funções para sua account de serviço. Na lista suspensa Selecionar uma função , digite
BigQuerye adicione as seguintes funções: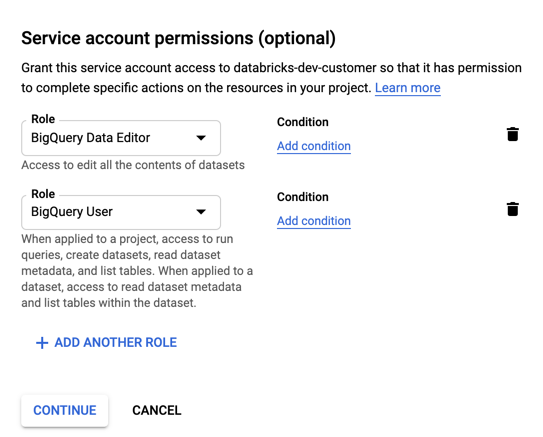
Clique em "Continuar".
Clique em Concluído.
A Databricks recomenda usar a autenticação de email account de serviço, mas se você optar por usar a autenticação baseada em key , crie a key para sua account de serviço fazendo o seguinte:
Na lista account de serviço, clique na sua account recém-criada.
Na seção key , selecione ADICIONAR key > botão Criar nova key .
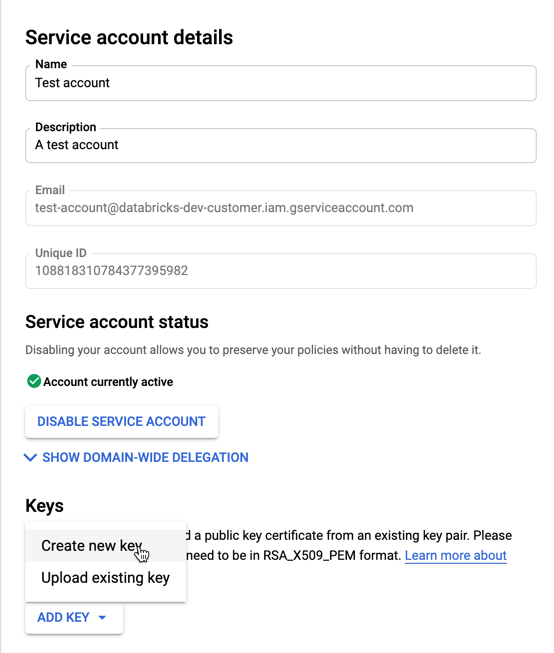
Aceite o key tipo JSON .
Clique em CRIAR. O arquivo key JSON é downloads para o seu computador.
Importante
O arquivo JSON key que você gera para a de serviço account é uma privada key que deve ser compartilhada apenas com usuários autorizados, pois controla o acesso ao dataset e recurso na sua do Google clouds account.
Crie um bucket do Google Cloud Storage (GCS) para armazenamento temporário
Para gravar dados no BigQuery, a fonte de dados precisa de acesso a um bucket do GCS.
Clique em Armazenamento no painel de navegação esquerdo.
Clique em Criar bucket.
Configure os detalhes do intervalo.
Clique em Criar.
Clique na Permissões tab e em Adicionar membros.
Forneça as seguintes permissões à account de serviço no bucket.
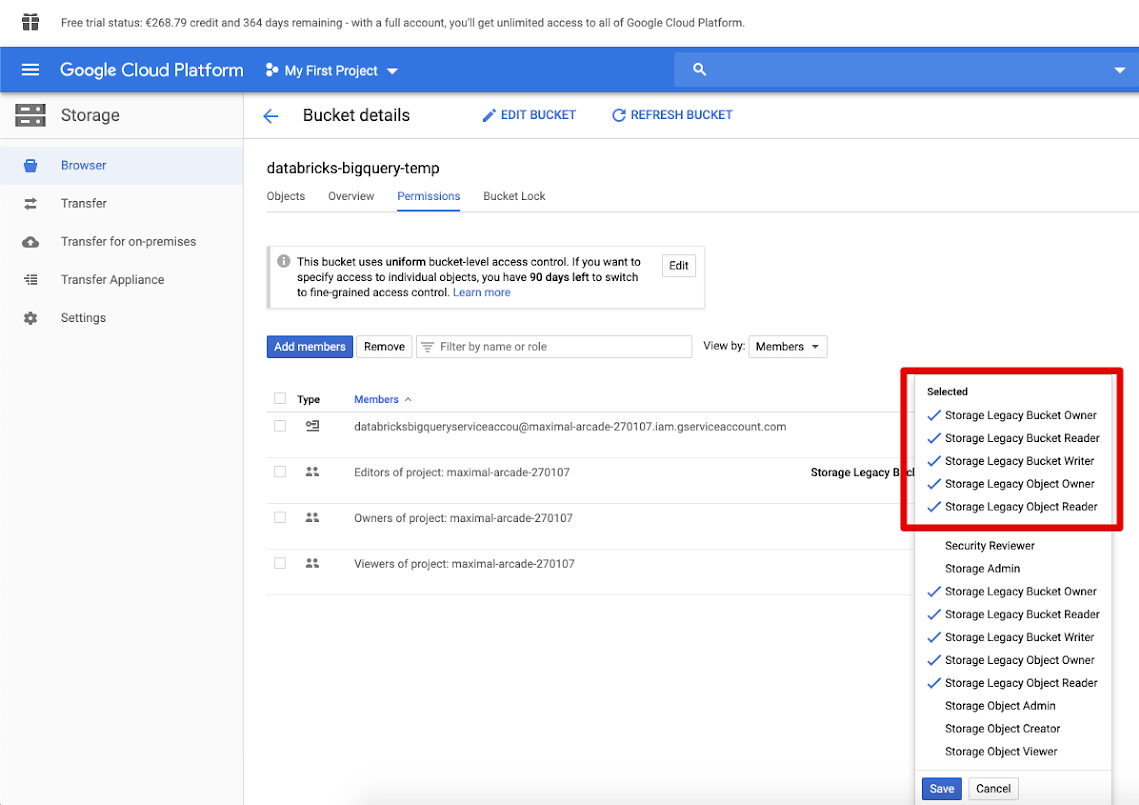
Clique em Salvar.
passo 2: Configurar Databricks
A Databricks recomenda o uso account email da autenticação de serviço, mas as instruções para keyautenticação baseada em também estão incluídas aqui.
Configurar clusters usando um endereço de e-mail de conta de serviço (recomendado)
Ao configurar seus clusters usando o clusters editor , clique em Opções avançadas e defina de serviço do Google account como o account email endereço de da sua de serviço.
Configurar clusters usando autenticação baseada em chave
Ao configurar seus clusters usando o clusters editor , clique em Opções avançadas, clique na Spark Config tab e adicione a seguinte configuração do Spark. Substitua <base64-keys> pelo arquivo key JSON codificado em Base64. Substitua os outros itens entre colchetes (como <client-email>) pelos valores desses campos do seu arquivo key JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Ler e gravar em uma tabela do BigQuery
Para ler uma tabela do BigQuery, especifique
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Para gravar em uma tabela do BigQuery, especifique
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
em que <bucket-name> é o nome do bucket que o senhor criou em Criar um bucket do Google Cloud Storage (GCS) para armazenamento temporário. Consulte Permissões para saber mais sobre os requisitos para os valores <project-id> e <parent-id>.
Crie uma tabela externa do BigQuery
Importante
Este recurso não é compatível com o Unity Catalog.
Você pode declarar uma tabela não gerenciada no Databricks que lerá dados diretamente do BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)