Delta Live Tablesとは?
Delta Live Tables は、信頼性と保守性に優れた抽出、変換、読み込み (ETL) パイプラインの作成を簡略化するために設計された宣言型フレームワークです。 取り込むデータとその変換方法を指定すると、オーケストレーション、コンピュート管理、モニタリング、データ品質の適用、エラー処理など、データパイプラインの管理の主要な側面が Delta Live Tables 自動化されます。
Delta Live Tables は Apache Spark上に構築されていますが、一連の個別の Apache Spark タスクを使用してデータパイプラインを定義する代わりに、システムが作成するストリーミングテーブルとマテリアライズドビュー、およびそれらのストリーミングテーブルとマテリアライズドビューの設定と更新に必要なクエリを定義します。
Delta Live TablesでETLパイプラインを構築し、実行する利点の詳細については、Delta Live Tables製品ページをご覧ください。
Delta Live Tables と Apache Sparkの比較
は、Apache Spark を含む汎用性の高いオープンソースunified analytics エンジンです。ETLDelta Live Tables は Spark 上に構築されており、特定の一般的な ETL 処理タスクに対応します。 Delta Live Tables 、次のような処理タスクが要件に含まれている場合、本番運用への道を大幅に短縮できます。
一般的なソースからデータを取り込む。
データを段階的に変換する。
チェンジデータキャプチャ (CDC.
ただし、Delta Live Tables は、一部の種類の手続き型ロジックの実装には適していません。 たとえば、外部テーブルへの書き込みや、外部ファイル ストレージまたはデータベース テーブルを操作する条件を含めるなどの処理要件は、Delta Live Tables データセットを定義するコード内では実行できません。 Delta Live Tablesでサポートされていない処理を実装するにはDatabricks、Apache Sparkを使用するか、別のジョブ タスクで処理を実行するDatabricks ジョブにパイプラインを含めることをお勧めします。ジョブの Delta Live Tables パイプライン タスクを参照してください。
次の表では、Delta Live Tables と Apache Spark を比較しています。
機能 |
Delta Live Tables |
Apache Spark |
|---|---|---|
データ変換 |
SQL または Python を使用してデータを変換できます。 |
SQL、Python、Scala、または R を使用してデータを変換できます。 |
増分データ処理 |
多くのデータ変換は、自動的にインクリメンタルに処理されます。 |
新しいデータを特定し、増分処理できるようにする必要があります。 |
オーケストレーション |
変換は、正しい順序で自動的に調整されます。 |
異なる変換が正しい順序で実行されるようにする必要があります。 |
平行 |
すべての変換は、正しいレベルの並列処理で実行されます。 |
スレッドまたは外部オーケストレーターを使用して、無関係な変換を並列で実行する必要があります。 |
エラー処理 |
失敗は自動的に再試行されます。 |
エラーと再試行の処理方法を決定する必要があります。 |
モニタリング |
メトリクスとイベントは自動的にログに記録されます。 |
実行またはデータ品質に関するメトリクスを収集するためのコードを記述する必要があります。 |
Delta Live Tablesの主要な概念
次の図は、Delta Live Tables パイプラインの重要なコンポーネントと、それぞれの説明を示しています。
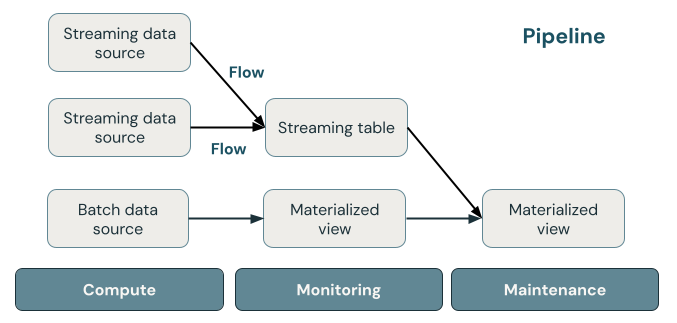
ストリーミングテーブル
ストリーミングテーブルは、1 つ以上のストリームが書き込んでいる Delta テーブルです。 ストリーミング テーブルは、入力データを 1 回だけ処理し、大量の追加専用データを処理できるため、インジェストによく使用されます。 ストリーミングテーブルは、大量のデータストリームの低レイテンシ変換にも役立ちます。
マテリアライズドビュー
マテリアライズドビューは、マテリアライズドビューを定義するクエリに基づいて事前計算されたレコードを含むビューです。 マテリアライズドビューのレコードは、パイプラインの更新スケジュールまたはトリガーに基づいて、Delta Live Tables によって自動的に最新の状態に保たれます。 マテリアライズドビューが更新されるたびに、使用可能な最新のデータに対して定義クエリを実行したときと同じ結果が得られることが保証されます。 ただし、これは多くの場合、 増分更新を使用して完全な結果を最初から再計算せずに行われます。 マテリアライズド・ビューは、変換によく使用されます。
Delta Live Tables データセットはデータをどのように処理しますか?
次の表では、マテリアライズドビュー、ストリーミングテーブル、およびビューがデータを処理する方法について説明します。
データセットのタイプ |
定義されたクエリーによってレコードが処理される方法とは? |
|---|---|
ストリーミングテーブル |
各レコードは一度だけ処理されます。これは、追加専用のソースを前提としています。 |
マテリアライズドビュー |
レコードは、現在のデータ状態の正確な結果を返すために、必要に応じて処理されます。 マテリアライズド ビューは、変換、集計、低速クエリや頻繁に使用される計算の事前計算などのデータ処理タスクに使用する必要があります。 |
VIEW |
レコードは、ビューがクエリーされるたびに処理されます。パブリックデータセットに公開すべきではない中間変換やデータ品質チェックにはビューを使用します。 |
Delta Live Tablesで最初のデータセットを宣言する
Delta Live Tables では、Python と SQL の新しい構文が導入されています。 パイプライン構文の基本については、「 Python を使用したパイプライン コードの開発 」および 「SQL を使用したパイプライン コードの開発」を参照してください。
注
Delta Live Tables はデータセット定義を更新処理から分離し、Delta Live Tables ノートブックは対話型実行を目的としていません。
Delta Live Tables パイプラインはどのように構成しますか?
Delta Live Tables パイプラインの設定は、大きく分けて 2 つのカテゴリに分類されます。
Delta Live Tables 構文を使用してデータセットを宣言するノートブックまたはファイルのコレクション ( ソース コードと呼ばれます) を定義する構成。
パイプライン インフラストラクチャ、依存関係の管理、更新の処理方法、ワークスペースでのテーブルの保存方法を制御する構成。
ほとんどの構成はオプションですが、特に運用パイプラインを構成する場合は、注意が必要です。これらには以下が含まれます:
パイプラインの外部でデータを利用できるようにするには、Hive metastoreに公開するターゲットスキーマ、またはUnity Catalogに公開するターゲットカタログとターゲットスキーマを宣言する必要があります。
データアクセス権限は、実行に使用されるクラスタリングを通じて構成されます。 クラスタリングに、データソースとターゲット ストレージの場所 (指定されている場合) に適切な権限が設定されていることを確認します。
PythonとSQLを使用してパイプラインのソースコードを記述する詳細については、Delta Live Tables SQL言語リファレンスとDelta Live Tables Python言語リファレンスを参照してください。
パイプラインの設定と構成の詳細については、「 Delta Live Tables パイプラインの構成」を参照してください。
最初のパイプラインをデプロイして更新をトリガーする
Delta Live Tables でデータを処理する前に、パイプラインを構成する必要があります。 パイプラインを設定したら、更新をトリガーして、パイプライン内の各データセットの結果を計算することができます。 Delta Live Tables パイプラインの使用を開始するには、「チュートリアル: 初めての Delta Live Tables パイプラインの実行」を参照してください。
パイプライン更新とは?
パイプラインはインフラストラクチャをデプロイし、更新の開始時にデータの状態を再計算します。更新プログラムは、次の処理を行います:
正しい構成でクラスターを開始します。
定義されているすべてのテーブルとビューを検出し、無効な列名、依存関係の欠落、構文エラーなどの分析エラーをチェックします。
使用可能な最新のデータでテーブルとビューを作成または更新します。
パイプラインは、ユースケースのコストとレイテンシの要件に応じて、継続的に実行することも、スケジュールに従って実行することもできます。Delta Live Tablesパイプラインで更新を実行するを参照してください。
Delta Live Tablesによるデータの取り込み
Delta Live Tablesは、Databricksで利用可能な全てのデータソースをサポートしています。
Databricksでは、ほとんどの取り込みユースケースでストリーミングテーブルを使用することをお勧めします。クラウドオブジェクトストレージに到着するファイルの場合、DatabricksはAuto Loaderを推奨します。Delta Live Tablesを使用して、ほとんどのメッセージバスからデータを直接取り込むことができます。
クラウド ストレージへのアクセスの構成の詳細については、「 クラウド ストレージの構成」を参照してください。
Auto Loaderでサポートされていない形式については、PythonまたはSQLを使用して、Apache Sparkでサポートされている形式をクエリーできます。Delta Live Tablesを使用したデータのロードを参照してください。
データ品質の監視と実施
エクスペクテーションを使用して、データセットの内容に対するデータ品質管理を指定できます。制約を満たさないレコードを追加できない従来のデータベースの CHECK 制約とは異なり、エクスペクテーションは、データ品質要件を満たさないデータを処理するときに柔軟性を提供します。 この柔軟性により、乱雑になると予想されるデータや、厳しい品質要件を満たす必要があるデータを処理および保存できます。 「パイプラインのエクスペクテーションを使用してデータ品質を管理する」を参照してください。
Delta Live Tablesによるテーブルの作成および管理方法
Databricksは、Delta Live Tablesで作成されたテーブルを自動的に管理し、テーブルの現在の状態を正しく計算するために必要な更新の処理方法を決定し、多数のメンテナンスおよび最適化タスクを実行します。
ほとんどの操作では、ターゲットテーブルに対するすべての更新、挿入、および削除を Delta Live Tables 処理できるようにする必要があります。 詳細と制限事項については、 手動による削除または更新を保持するを参照してください。
Delta Live Tablesによって実行されるメンテナンスタスク
Delta Live Tables は、テーブルが更新されてから 24 時間以内にメンテナンスタスクを実行します。 メンテナンスにより、古いバージョンのテーブルを削除することで、クエリーのパフォーマンスを向上させ、コストを削減できます。 デフォルトでは、システムは完全な OPTIMIZE 操作を実行してから VACUUM を実行します。 テーブルの OPTIMIZE を無効にするには、テーブルの テーブル プロパティ で pipelines.autoOptimize.managed = false を設定します。メンテナンス タスクは、メンテナンス タスクがスケジュールされる前の 24 時間以内にパイプラインの更新が実行された場合にのみ実行されます。
制限事項
制限事項の一覧については、「 Delta Live Tables の制限事項」を参照してください。
Unity Catalog で Delta Live Tables を使用する場合に固有の要件と制限事項の一覧については、「Delta Live Tables パイプラインで Unity Catalog を使用する」を参照してください
追加のリソース
Delta Live Tables は、Databricks REST API で完全にサポートされています。 DLT APIを参照してください。
パイプラインとテーブルの設定については、Delta Live Tablesプロパティのリファレンスを参照してください。