なぜインクリメンタル・ストリーム処理なのか?
今日のデータドリブンなビジネスでは、データを継続的に生成しているため、このデータを継続的に取り込み、変換するエンジニアリングデータパイプラインが必要です。 これらのパイプラインは、データを一度だけ処理して配信し、200ミリ秒未満のレイテンシで結果を生成でき、常にコストを最小限に抑えるように努める必要があります。
この記事では、エンジニアリング データパイプラインのバッチ処理とインクリメンタル ストリーム処理のアプローチ、インクリメンタル ストリーム処理が優れたオプションである理由、およびインクリメンタル ストリーム処理オファリング、 Databricksにおけるストリーミング 、および Delta Live Tables を使い始めるための次のステップについて説明します。これらの機能を使用すると、配信のセマンティクス、レイテンシ、コストなどを保証するパイプラインをすばやく記述して実行できます。
繰り返されるバッチジョブの落とし穴
データパイプラインを設定するときは、最初にデータをインジェストするために繰り返しバッチジョブを記述できます。 たとえば、1 時間ごとに Spark ジョブを実行して、ソースから読み取り、Delta Lake などのシンクにデータを書き込むことができます。 このアプローチの課題は、1 時間ごとに実行される Spark ジョブは、最後のジョブが終了したところから開始する必要があるため、ソースを段階的に処理することです。 処理したデータの最新のタイムスタンプを記録し、そのタイムスタンプよりも新しいタイムスタンプを持つすべての行を選択できますが、落とし穴があります。
連続データパイプラインを実行するには、ソースから増分的に読み取り、変換を行い、結果をシンク ( Delta Lakeなど) に書き込む 1 時間ごとのバッチジョブをスケジュールしてみます。 このアプローチには落とし穴があります。
タイムスタンプより後のすべての新しいデータに対してクエリを実行する Spark ジョブは、遅延データを見逃します。
Spark ジョブが失敗すると、慎重に処理しないと、exactly-once 保証が壊れる可能性があります。
新しいファイルを見つけるためにクラウド ストレージの場所の内容を一覧表示する Spark ジョブは、コストが高くなります。
その後も、このデータを繰り返し変換する必要があります。 データを集約したり、他の操作を適用したりするバッチジョブを繰り返し作成すると、パイプラインの効率がさらに複雑になり、低下する可能性があります。
バッチの例
パイプラインのバッチ取得と変換の落とし穴を完全に理解するには、次の例を検討してください。
欠落したデータ
顧客に請求する金額を決定する使用状況データを含む Kafka トピックがあり、パイプラインがバッチで取り込まれている場合、イベントのシーケンスは次のようになります。
最初のバッチには、午前 8 時と午前 8 時 30 分の 2 つのレコードがあります。
最新のタイムスタンプを午前 8 時 30 分に更新します。
午前8時15分に別の記録が出ます。
2 番目のバッチは午前 8 時 30 分以降にすべてをクエリするため、 午前 8 時 15 分にレコードを見逃します。
さらに、ユーザーに過大請求や過小請求をしたくないため、すべてのレコードを一度だけ取り込むようにする必要があります。
冗長な処理
次に、データにユーザー購入の行が含まれており、ストアで最も人気のある時間を知るために時間あたりの売上を集計するとします。 同じ時間の購入が異なるバッチで到着した場合、同じ時間に出力を生成する複数のバッチがあります。
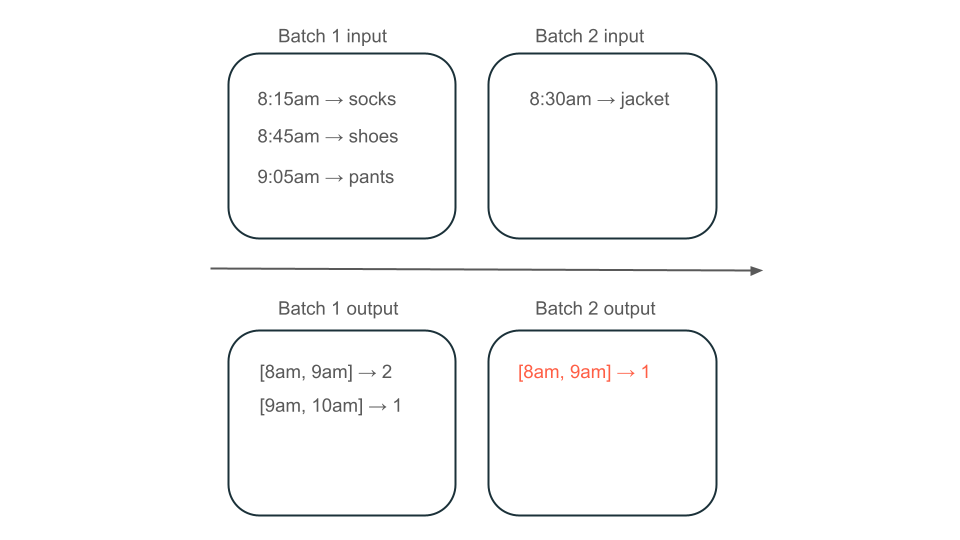
午前 8 時から午前 9 時のウィンドウには、2 つの要素 (バッチ 1 の出力)、1 つの要素 (バッチ 2 の出力)、または 3 つの要素 (どのバッチの出力もない) がありますか? 特定の時間枠を生成するために必要なデータは、変換の複数のバッチに表示されます。 これを解決するには、データを日単位でパーティション分割し、結果をコンピュートする必要があるときにパーティション全体を再処理します。 その後、シンクで結果を上書きできます。
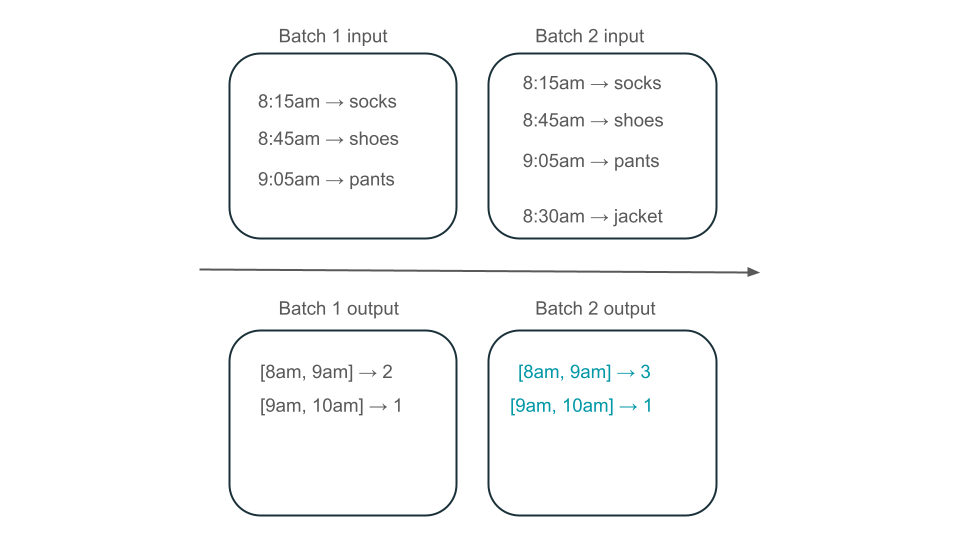
ただし、これには、2 番目のバッチが既に処理した可能性のあるデータを処理する不要な作業を行う必要があるため、待機時間とコストが犠牲になります。
インクリメンタル・ストリーム処理に落とし穴はありません
インクリメンタルストリーム処理により、データの取り込みと変換のために繰り返されるバッチジョブのすべての落とし穴を簡単に回避できます。 Databricksの構造化ストリーミング と Delta Live Tables は、ストリーミングの実装の複雑さを管理し、ビジネスロジックだけに集中できるようにします。接続先のソース、データに対して行う変換、および結果を書き込む場所を指定するだけで済みます。
増分インジェスト
Databricks での増分インジェストは、Apache Spark 構造化ストリーミングによって強化され、データのソースを段階的に消費し、シンクに書き込むことができます。構造化ストリーミング エンジンはデータを 1 回だけ消費でき、エンジンは順不同のデータを処理できます。 エンジンは、ノートブックで実行することも、Delta Live Tables のストリーミング テーブルを使用して実行することもできます。
Databricks の構造化ストリーミングエンジンは、 AutoLoader などの独自のストリーミングソースを提供し、費用対効果の高い方法でクラウドファイルを段階的に処理できます。 Databricks は、 Apache Kafka、 Amazon Kinesis、 Apache Pulsar、 Google Pub/Sub などの他の一般的なメッセージバス用のコネクタも提供しています。
構造化ストリーミング、あるいはDelta Live Tables?
構造化ストリーミングと Delta Live Tables の大きな違いは、ストリーミングクエリを運用する方法です。 構造化ストリーミングでは、多くの設定を手動で指定し、クエリを手動でつなぎ合わせる必要があります。 クエリを明示的に開始し、クエリが終了するのを待つ、失敗したときにクエリをキャンセルする、およびその他のアクションを行う必要があります。 Delta Live Tables では、Delta Live Tables にパイプラインの実行を宣言によって指定し、パイプラインの実行を維持します。
これらの機能の詳細については、「Databricksでのストリーミング」および「Delta Live Tablesとは」を参照してください。
次のステップ
Delta Live Tables を使用して最初のパイプラインを作成します。 「 チュートリアル: 初めての Delta Live Tables パイプラインを実行する」を参照してください。
初めての構造化ストリーミング クエリを Databricks で実行します。 「 初めての構造化ストリーミングワークロードを実行する」を参照してください。