Google Cloud Storageに接続する
注:
この記事では、GCS へのアクセスを設定するための従来のパターンについて説明します。 Databricks では、Unity Catalog を使用して、ファイルと直接対話するための GCS とボリュームへのアクセスを構成することをお勧めします。 「Unity Catalog を使用してクラウド オブジェクト ストレージとサービスに接続する」を参照してください。
この記事では、Google Cloud Storage (GCS) に格納されているテーブルとデータを読み書きするために Databricks からの接続を構成する方法について説明します。
クラスター上の Google Cloudサービスアカウントを使用して GCS バケットにアクセスする
GCS バケットには、クラスター上の Google クラウドサービスアカウントを使用してアクセスできます。 サービスアカウントには、GCS バケットからの読み取りと書き込みの権限を付与する必要があります。 Databricks では、このサービス アカウントに、タスクの実行に必要な最小限の特権を付与することをお勧めします。 その後、そのサービス アカウントを Databricks クラスターに関連付けることができます。
サービスアカウントのEメールアドレス(推奨される方法)またはサービスアカウント用に生成したキーを使用して、バケットに直接接続できます。
重要
サービス アカウントは、Databricks ワークスペースの設定に使用した Google クラウド プロジェクトに存在する必要があります。
サービス アカウント ロールを作成する GCP ユーザーは、次のことを行う必要があります。
サービスアカウントを作成し、GCS バケットの読み取りと書き込みを行う権限ロールを付与する権限を持つ GCP アカウント ユーザーであること。
サービス アカウントをクラスターに追加する Databricks ユーザーには、クラスターに対する [管理可能 ] アクセス許可が必要です。
ステップ1: Google Cloudコンソールを使用してGoogle Cloudサービスアカウントを設定する
左側のナビゲーションペインで [ IAM and Admin ] をクリックします。
「 サービス・アカウント」をクリックします。
[+ CREATE サービス アカウント] をクリックします。
サービス アカウントの名前と説明を入力します。
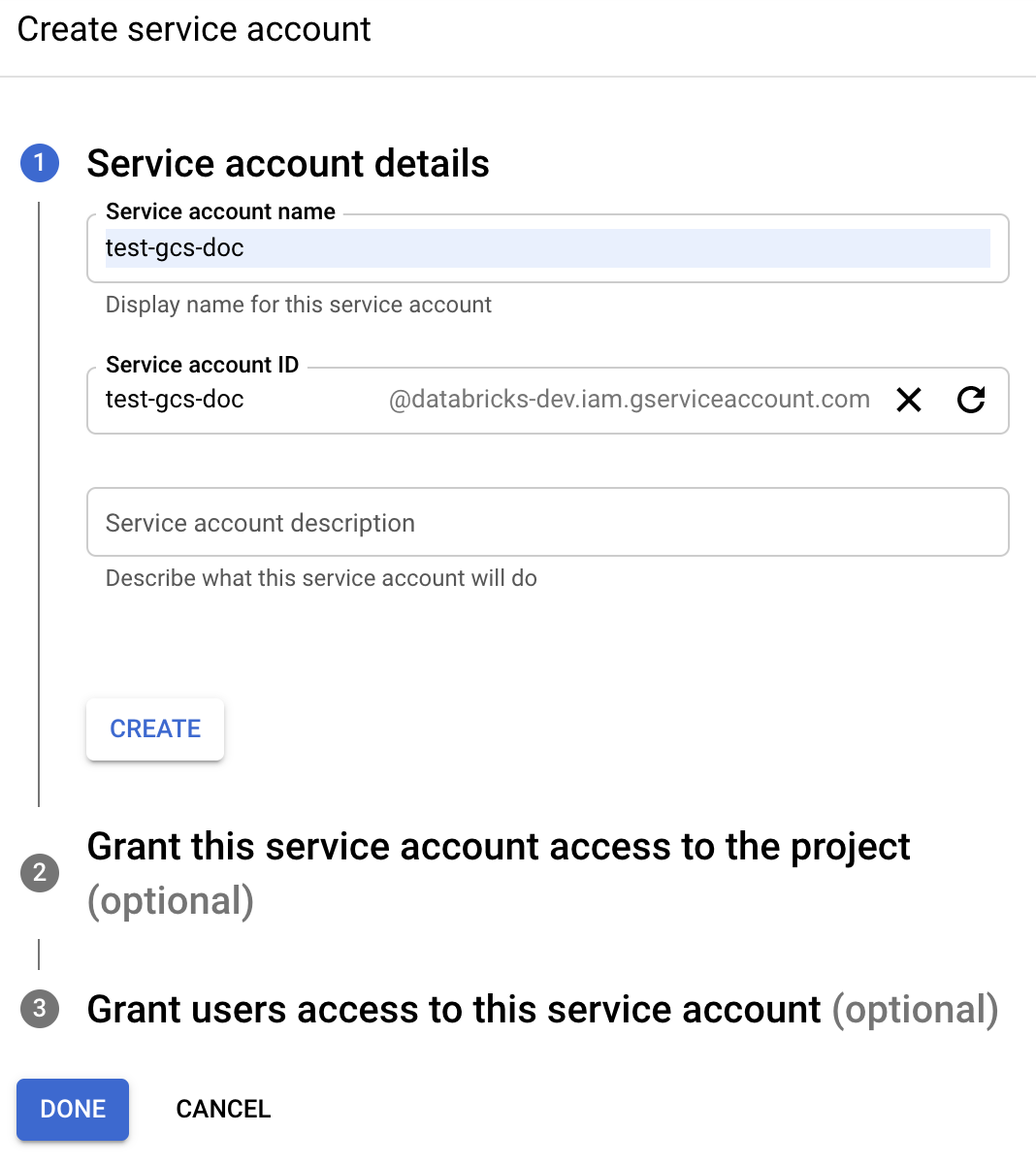
[作成]をクリックします。
「続行」をクリックします。
[完了] をクリックします。
Google クラウドコンソールのサービスアカウントリストに移動し、 サービスアカウント を選択します。
関連付けられたEメールアドレスをコピーします。 これは、Databricks クラスターを設定するときに必要になります。
ステップ 2: GCS バケットを設定する
バケットの作成
バケットがまだない場合は、作成します。
左側のナビゲーション ウィンドウで [ ストレージ ] をクリックします。
「バケットを作成」をクリックします。
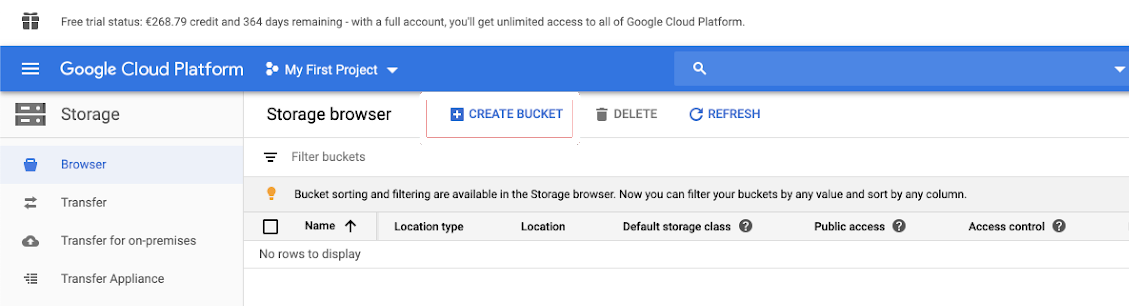
バケットに名前を付けます。 GCS バケットに関する Google の 命名要件 に準拠した、グローバルに一意で永続的な名前を選択します。
重要
DBFSマウントを使用するには、バケット名にアンダースコアを含めることはできません。
[作成]をクリックします。
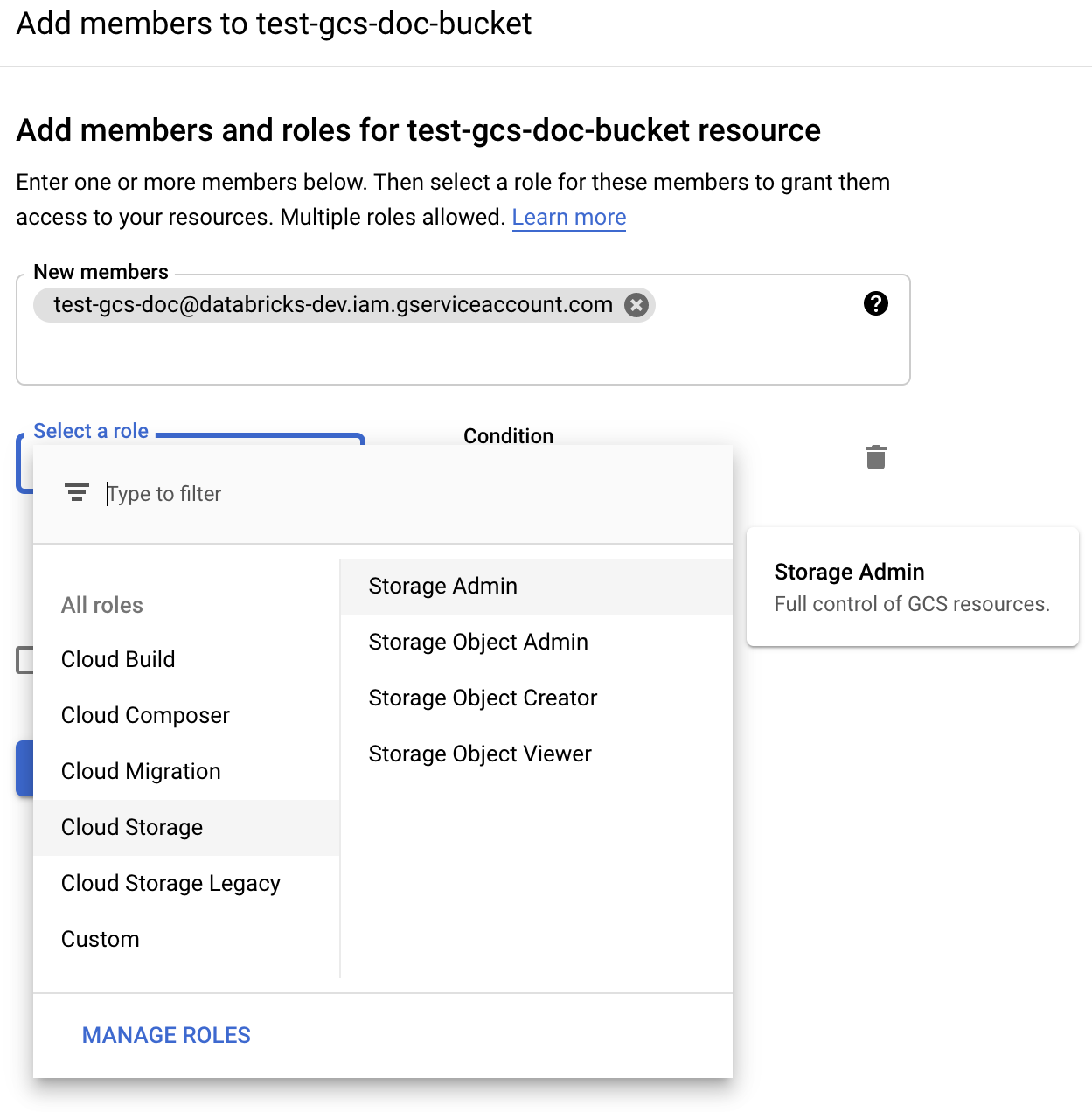
ステップ 3: Databricks クラスターを構成する
クラスタリングを設定する際に、[詳細設定] を展開し、[Google サービス アカウント] フィールドをサービス アカウントの Eメール アドレスに設定します。
クラスター アクセス制御とノートブック アクセス制御の両方を併用して、GCS バケット内のサービス アカウントとデータへのアクセスを保護します。 「コンピュート権限」と 「Databricks ノートブックを使用したコラボレーション」を参照してください。
Google Cloudのサービスアカウントキーを使用して GCS バケットに直接アクセスする
バケットを直接読み書きするには、サービスアカウントのEメールアドレスを設定するか、 Spark設定で定義されたキーを設定します。
注:
Databricksでは、キーが関与しないため、キーが漏洩するリスクがないため、サービスアカウントのEメールアドレスの使用を推奨しています。 キーを使用する理由の 1 つは、サービス アカウントがワークスペースの作成時に使用したプロジェクトとは異なる Google クラウド プロジェクトに存在する必要がある場合です。 サービスアカウントのメールアドレスを使用するには、 クラスターで Google クラウドのサービスアカウントを使用して GCS バケットにアクセスする を参照してください。
ステップ1: Google Cloudコンソールを使用してGoogle Cloudサービスアカウントを設定する
Databricks クラスターのサービス アカウントを作成する必要があります。 Databricks では、このサービス アカウントに、タスクの実行に必要な最小限の特権を付与することをお勧めします。
左側のナビゲーションペインで [ IAM and Admin ] をクリックします。
「 サービス・アカウント」をクリックします。
[+ CREATE サービス アカウント] をクリックします。
サービス アカウントの名前と説明を入力します。
[作成]をクリックします。
「続行」をクリックします。
[完了] をクリックします。
ステップ 2: GCS バケットに直接アクセスするためのキーを作成する
警告
サービス アカウント用に生成する JSON キーは、Google Cloud アカウントのデータセットとリソースへのアクセスを制御するため、許可されたユーザーとのみ共有する必要がある秘密鍵です。
Google Cloud コンソールのサービス アカウント リストで、新しく作成したアカウントをクリックします。
[キー] セクションで、[キーの追加] > [新しいキーの作成] をクリックします。
JSON キーの種類を受け入れます。
「作成」をクリックします。キーファイルがコンピュータにダウンロードされます。
ステップ 4: サービス アカウント キーを Databricks シークレットに配置する
Databricks では、すべての資格情報の保存にシークレットスコープを使用することをお勧めします。 キー JSON ファイルの秘密鍵と秘密鍵IDをシークレットスコープに入れることができます Databricks 。 ワークスペース内のユーザー、サービスプリンシパル、およびグループに、シークレットスコープを読み取るためのアクセス権を付与できます。 これにより、サービスアカウントキーが保護され、ユーザーはGCSにアクセスできます。 シークレットスコープを作成するには、「 シークレットの管理」を参照してください。
ステップ 5: Databricks クラスターを構成する
[ Spark Config ] タブで、グローバル設定またはバケットごとの設定を設定します。 次の例では、Databricks シークレットとして保存されている値を使用してキーを設定します。
注:
クラスターのアクセス制御とノートブックのアクセス制御を一緒に使用して、GCS バケット内のサービスアカウントとデータへのアクセスを保護します。 「コンピュートの権限」および「Databricks ノートブックを使用した共同作業」を参照してください。
グローバル構成
指定された認証情報を使用してすべてのバケットにアクセスする必要がある場合は、この設定を使用します。
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
<client-email>、<project-id> を、キー JSON ファイルの正確なフィールド名の値に置き換えます。
バケットごとの構成
特定のバケットの認証情報を設定する必要がある場合は、この設定を使用します。 バケットごとの設定の構文では、次の例のように、各設定の末尾にバケット名が追加されます。
重要
グローバル設定に加えて、バケットごとの設定も使用できます。 指定すると、バケットごとの設定がグローバル設定よりも優先されます。
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
<client-email>、<project-id> を、キー JSON ファイルの正確なフィールド名の値に置き換えます。
ステップ 6: GCS から読み取る
GCS バケットから読み取るには、サポートされている任意の形式で Spark 読み取りコマンドを使用します。
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
GCS バケットに書き込むには、サポートされている任意の形式で Spark write コマンドを使用します。
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
<bucket-name> は、「ステップ 3: GCS バケットを設定する」で作成したバケットの名前に置き換えます。