Conecte-se ao Google Cloud Storage
Observação
Este artigo descreve os padrões herdados para configurar o acesso a GCS. A Databricks recomenda o uso do Unity Catalog para configurar o acesso ao GCS e aos volumes para interação direta com os arquivos. Consulte Conectar-se ao serviço e ao armazenamento de objetos na nuvem usando Unity Catalog.
Este artigo descreve como configurar uma conexão do Databricks para ler e gravar tabelas e dados armazenados no Google Cloud Storage (GCS).
Acesse buckets do GCS usando de clouds serviço de do Google account em clusters
Você pode acessar os buckets do GCS usando de clouds serviço do Google account em clusters. Você precisa conceder à account de serviço permissões de leitura e gravação no bucket do GCS. A Databricks recomenda atribuir a esta account de serviço os privilégios mínimos necessários para executar a sua tarefa. Você pode então associar essa account de serviço a clusters do Databricks.
Você pode se conectar ao bucket diretamente usando o endereço de serviço account email (abordagem recomendada) ou uma key gerada para a de serviço account.
Importante
A account de serviço deve estar no projeto clouds do Google usado para configurar o workspace do Databricks.
O usuário do GCP que cria a função da account de serviço precisa:
Ser um usuário account do GCP com permissões para criar account de serviço e conceder funções de permissão para leitura e gravação em um bucket do GCS.
O usuário do Databricks que adiciona a account de serviço a clusters deve ter a permissão Pode gerenciar em clusters.
passo 1: configurar a conta de serviço do Google Cloud usando o Console do Google Cloud
Clique em IAM e Admin no painel de navegação esquerdo.
Clique em accountde serviço.
Clique em + CRIAR accountde serviço.
Insira o nome e a descrição account de serviço.
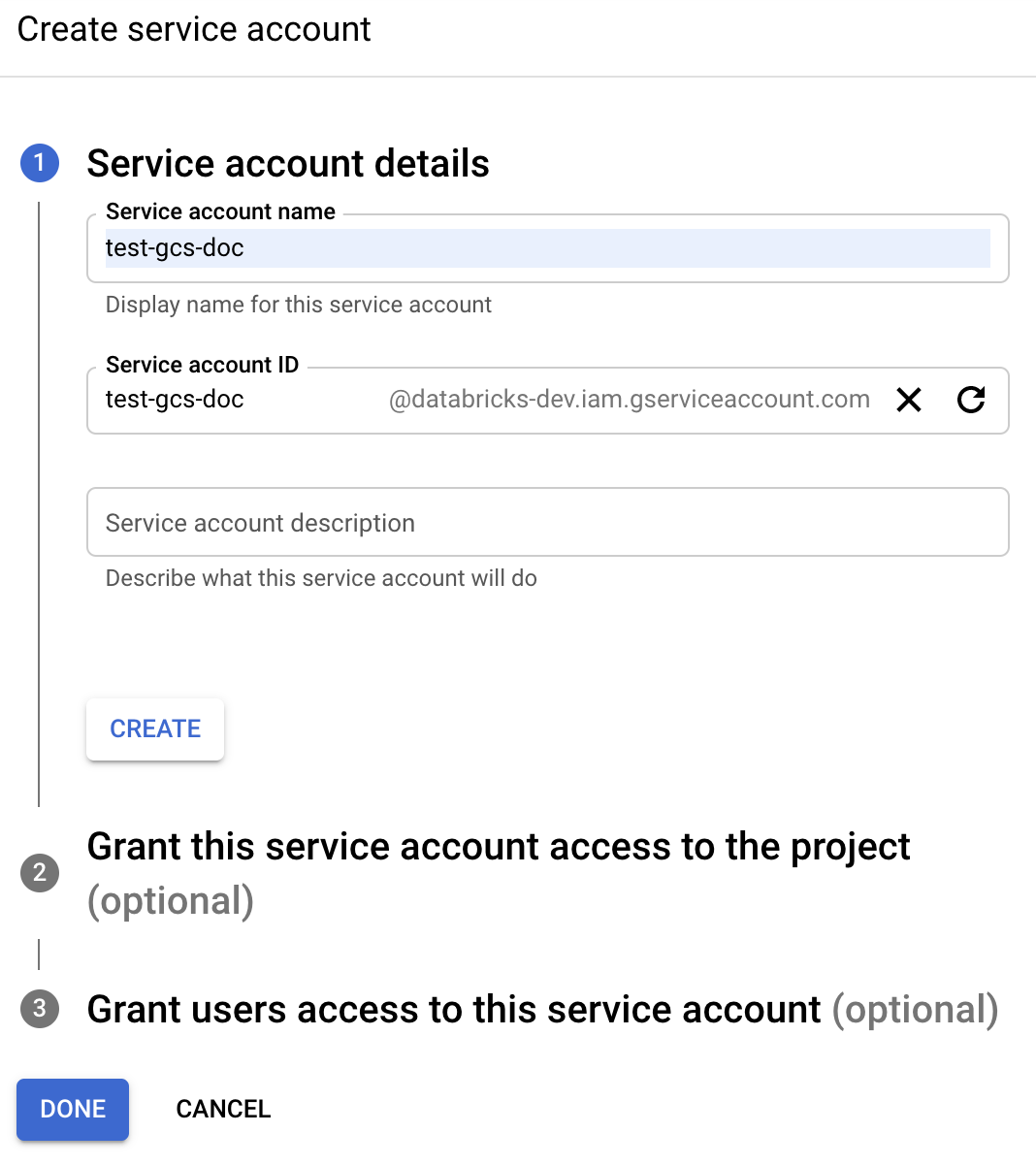
Clique em Criar.
Clique em "Continuar".
Clique em Concluído.
Navegue até a clouds lista de de serviço do Google account Console e selecione uma de account serviço.
Copie o endereço email associado. Você precisará dele ao configurar clusters do Databricks.
o passo 2: Configure seu bucket do GCS
Crie um balde
Se você ainda não possui um bucket, crie um:
Clique em Armazenamento no painel de navegação esquerdo.
Clique em Criar bucket.
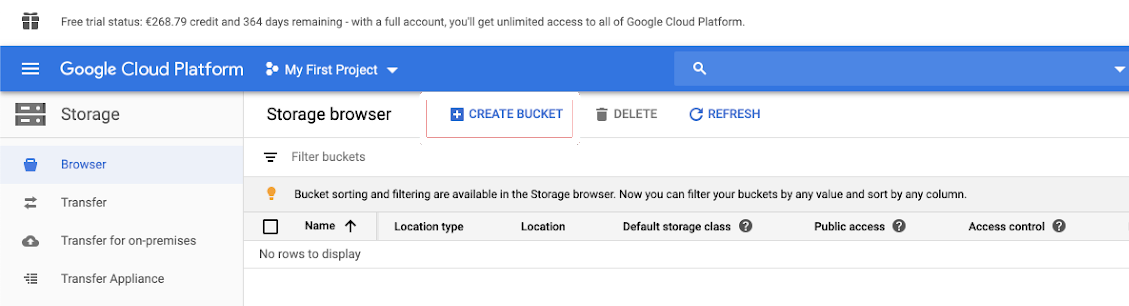
Dê um nome ao seu balde. Escolha um nome globalmente exclusivo e permanente que esteja em conformidade com os requisitos de nomenclatura do Google para intervalos do GCS.
Importante
Para trabalhar com montagens DBFS, o nome do seu bucket não deve conter sublinhado.
Clique em Criar.
Configurar o intervalo
Configure o intervalo:
Configure os detalhes do intervalo.
Clique na guia Permissões .
Ao lado do rótulo Permissões , clique em ADICIONAR.
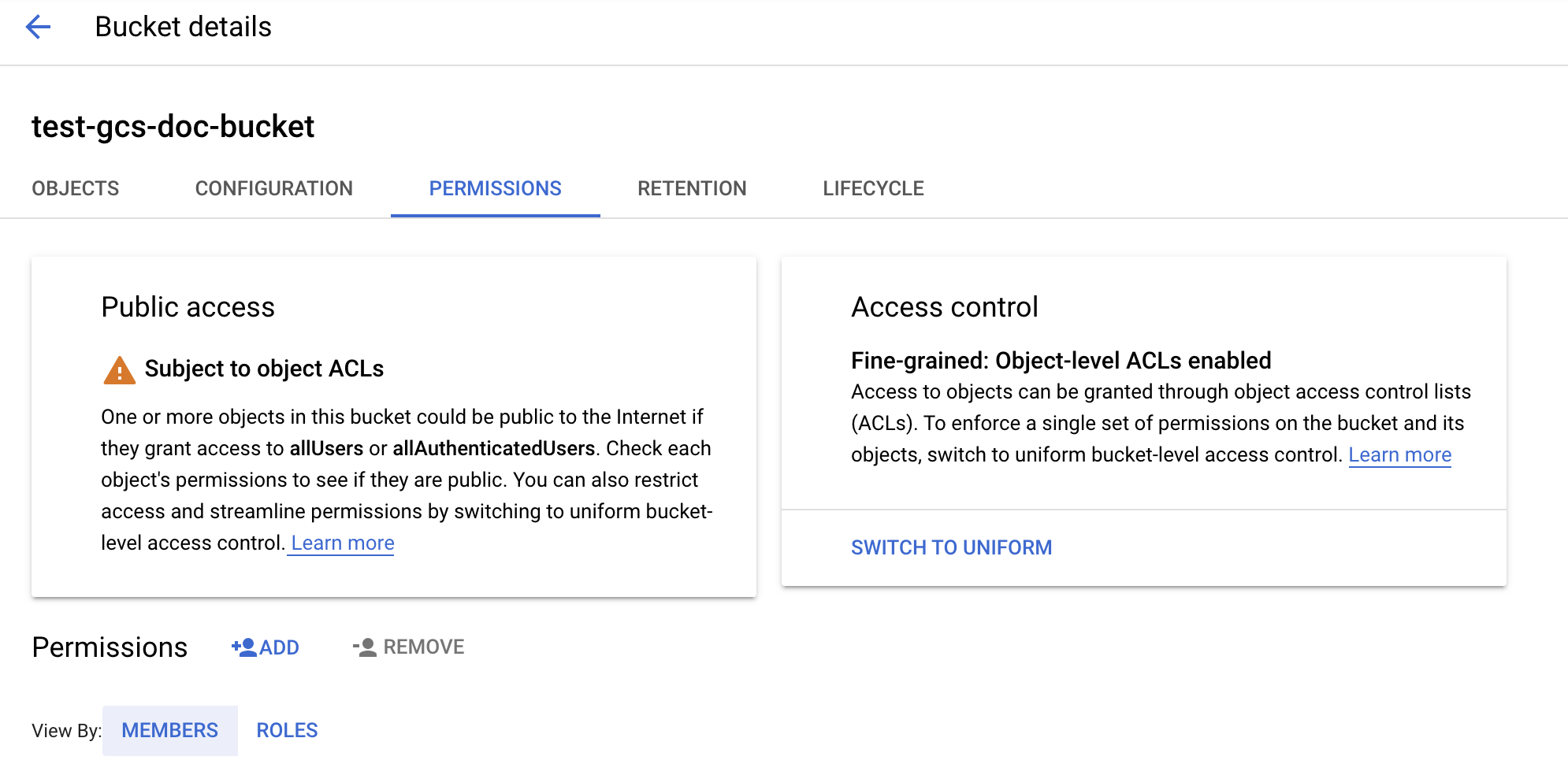
Forneça a permissão desejada para a account de serviço no bucket das funções de armazenamento clouds :
Administrador de armazenamento: concede privilégios totais neste bucket.
Visualizador de objetos de armazenamento: concede permissões de leitura e lista em objetos neste bucket.
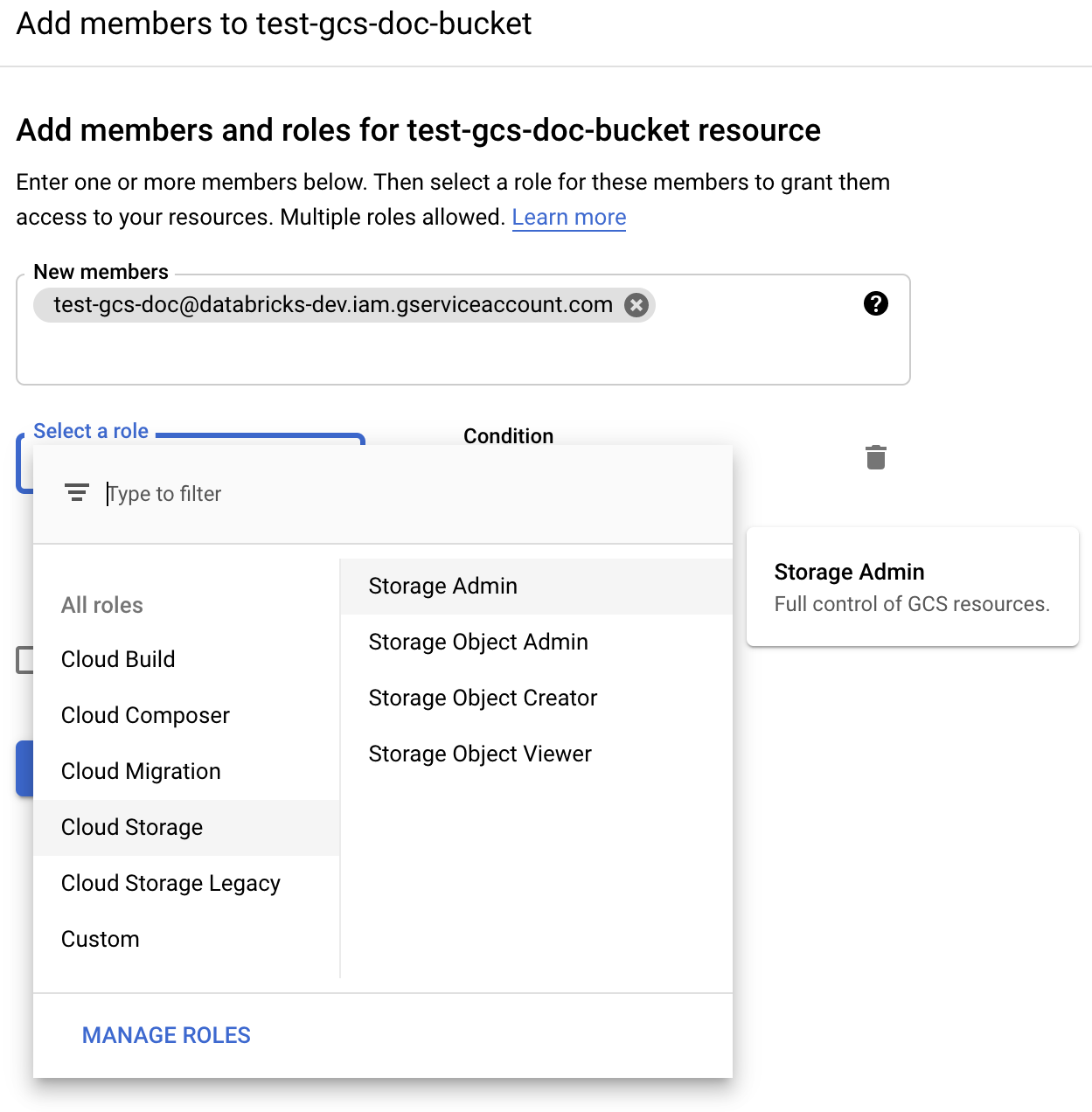
Clique em Salvar.
o passo 3: Configurar clustersdo Databricks
Ao configurar o clustering, expanda Advanced e defina o campo da conta de serviço do Google como seu endereço de serviço account email .
Use o controle de acesso a clusters e o controle de acesso a Notebook juntos para proteger o acesso ao serviço account e aos dados no bucket do GCS. Consulte Permissões de computação e colaboração usando o Databricks Notebook.
Acesse um bucket do GCS diretamente com uma chave de conta do serviço clouds do Google
Para ler e gravar diretamente em um bucket, você pode definir o endereço de serviço account email ou configurar uma key definida na configuração do Spark.
Observação
A Databricks recomenda usar o endereço de serviço account email porque não há key envolvida, portanto não há risco de vazamento da key. Um motivo para usar uma key é se a account de serviço precisar estar em um projeto do Google clouds diferente do projeto usado ao criar o workspace. Para usar um endereço email de conta de serviço, consulte Acessar buckets do GCS usando contas de serviço clouds do Google em clusters.
passo 1: configurar a conta de serviço do Google Cloud usando o Console do Google Cloud
Você deve criar uma account de serviço para os clusters do Databricks. A Databricks recomenda atribuir a esta account de serviço os privilégios mínimos necessários para executar a sua tarefa.
Clique em IAM e Admin no painel de navegação esquerdo.
Clique em accountde serviço.
Clique em + CRIAR accountde serviço.
Insira o nome e a descrição account de serviço.
Clique em Criar.
Clique em "Continuar".
Clique em Concluído.
passo 2: criar uma chave para acessar o bucket GCS diretamente
Aviso
A JSON que key você gera para a de serviço account é uma privada key que só deve ser compartilhada com usuários autorizados, pois controla o acesso ao dataset e recursos em sua do Google clouds account.
No console do Google clouds , na lista account de serviço, clique na account recém-criada.
Na seção key , clique em ADICIONAR key > Criar nova key.
Aceite o key tipo JSON .
Clique em CRIAR. O arquivo key é downloads para o seu computador.
passo 3: configurar o bucket GCS
passo 4: coloque a chave da conta de serviço nos segredos do Databricks
Databricks recomenda o uso do Secret Scope para armazenar todas as credenciais. O senhor pode colocar o key privado e o key ID privado do seu arquivo key JSON em Databricks Secret Scope. O senhor pode conceder a usuários, entidades de serviço e grupos em seu workspace acesso para ler o Secret Scope. Isso protege o serviço account key e, ao mesmo tempo, permite que os usuários acessem GCS. Para criar um escopo secreto, consulte gerenciar segredos.
passo 5: configurar clustersdo Databricks
No endereço Spark Config tab, defina uma configuração global ou uma configuração por bucket. Os exemplos a seguir definem a chave usando valores armazenados como segredos de Databricks.
Observação
Use o controle de acesso cluster e o controle de acesso ao Notebook juntos para proteger o acesso ao serviço account e aos dados no bucket GCS. Consulte Permissões de computação e Colaborar usando o Databricks Notebook.
Configuração global
Use essa configuração se as credenciais fornecidas precisarem ser usadas para acessar todos os buckets.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Substitua <client-email>, <project-id> pelos valores desses nomes de campos exatos do seu arquivo JSON key .
Configuração por bucket
Use essa configuração se precisar configurar credenciais para buckets específicos. A sintaxe da configuração por bucket acrescenta o nome do bucket ao final de cada configuração, como no exemplo a seguir.
Importante
As configurações por bucket podem ser usadas além das configurações globais. Quando especificadas, as configurações por bucket substituem as configurações globais.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Substitua <client-email>, <project-id> pelos valores desses nomes de campos exatos do seu arquivo JSON key .
passo 6: leitura do GCS
Para ler o bucket do GCS, use um comando de leitura do Spark em qualquer formato compatível, por exemplo:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Para gravar no bucket do GCS, use um comando de gravação do Spark em qualquer formato compatível, por exemplo:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Substitua <bucket-name> pelo nome do bucket que você criou na passo 3: Configure the GCS bucket.