Unity Catalog を使用してデータリネージをキャプチャして表示する
この記事では、カタログ エクスプローラー、データリネージ システムテーブル、およびREST APIを使用してデータリネージをキャプチャおよび視覚化する方法について説明します。
Unity Catalogを使用すると、 Databricksでのクエリ実行全体でランタイム データ リネージをキャプチャできます。 リネージはすべての言語でサポートされており、列レベルまでキャプチャされます。 リネージ データには、クエリに関連するノートブック、ジョブ、ダッシュボードが含まれます。 リネージはカタログ エクスプローラーですぐに視覚化でき、リネージ システムテーブルとDatabricks REST APIを使用してプログラムで取得できます。
リネージは、 Unity Catalog メタストアにアタッチされているすべてのワークスペース全体で集計されます。 つまり、1つのワークスペースでキャプチャされたリネージは、そのメタストアを共有する他のワークスペースで見ることができます。 具体的には、メタストアに登録されているテーブルやその他のデータ オブジェクトは、メタストアに接続されているすべてのワークスペースで、それらのオブジェクトに対して少なくとも BROWSE のアクセス許可を持つユーザーに表示されます。 ただし、ノートブックや他のワークスペースのダッシュボードなど、ワークスペースレベルのオブジェクトに関する詳細な情報はマスクされます ( 「制限事項 」と 「リネージのアクセス許可」を参照)。
リネージュデータは 1 年間保持されます。
以下の画像はリネージグラフのサンプルです。 具体的な Datalinage 機能と例については、この記事の後半で説明します。
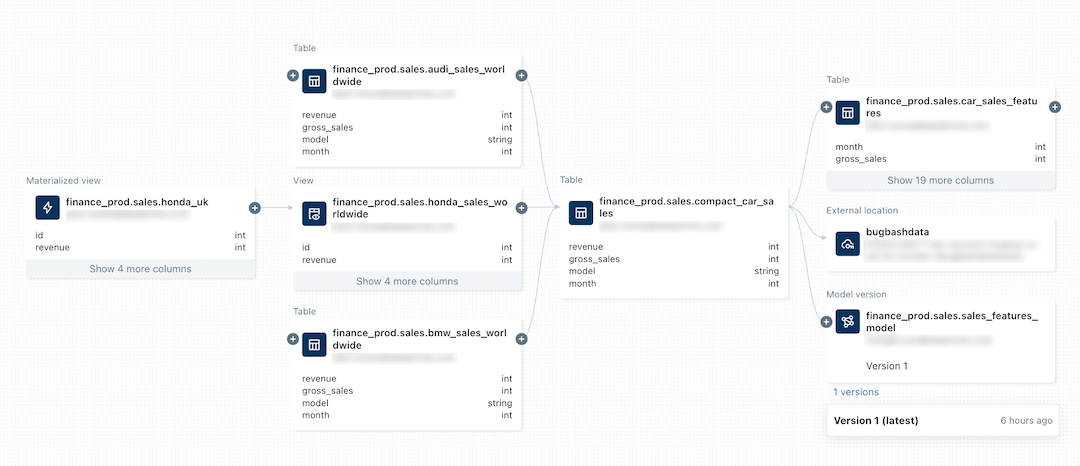
機械学習モデルのリネージを追跡する方法については、 「 Unity Catalogでモデルのデータリネージを追跡する」を参照してください。
要件
Unity Catalog を使用してデータリネージをキャプチャするには、次のものが必要です。
ワークスペースで Unity Catalog が有効になっている必要があります。
テーブルは、Unity Catalog メタストアに登録する必要があります。
クエリー では、Spark DataFrame (たとえば、DataFrame を返す Spark SQL 関数) または Databricks SQL インターフェイスを使用する必要があります。 Databricks SQL と PySpark クエリーの例については、「 例」を参照してください。
テーブルまたはビューのリネージを表示するには、ユーザーは少なくともテーブルまたはビューの親カタログに対する
BROWSE権限を持っている必要があります。 親カタログは、ワークスペースからもアクセスできる必要があります。 「 カタログへのアクセスを特定のワークスペースに制限する」を参照してください。ノートブック、ジョブ、またはダッシュボードのリネージ情報を表示するには、ユーザーはワークスペースのアクセス制御設定で定義されているこれらのオブジェクトに対する権限を持っている必要があります。 リネージの権限を参照してください。
Unity Catalog対応パイプラインの系列を表示するには、パイプラインに対する
CAN_VIEWアクセス許可が必要です。Deltaテーブル間のストリーミングのリネージ追跡には、 Databricks Runtime 11.3 LTS以上が必要です。
Delta Live Tablesワークロードの列リネージ追跡には、 Databricks Runtime 13.3 LTS以上が必要です。
例
注
次の例では、カタログ名
lineage_dataとスキーマ名lineagedemoを使用します。 別のカタログとスキーマを使用するには、例で使用されている名前を変更します。この例を完了するには、スキーマに対する
CREATE権限とUSE SCHEMA権限が必要です。 メタストア管理者、カタログ所有者、スキーマ所有者、またはスキーマに対するMANAGE権限を持つユーザーは、これらの権限を付与できます。 たとえば、グループ 'data_engineers' 内のすべてのユーザーに、lineage_dataカタログのlineagedemoスキーマにテーブルを作成する権限を付与するには、上記のいずれかの権限またはロールを持つユーザーが次のクエリを実行できます。CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
系列のキャプチャと探索
リネージデータをキャプチャするには:
Databricks ランディングページに移動し、サイドバーの
 [ 新規 ] をクリックして、メニューから [ ノートブック ] を選択します。
[ 新規 ] をクリックして、メニューから [ ノートブック ] を選択します。ノートブックの名前を入力し、 [デフォルト 言語] で [SQL] を選択します。
[クラスター] で、 Unity Catalogにアクセスできるクラスターを選択します。
[作成]をクリックします。
最初のノートブックのセルに、次のクエリーを入力します。
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menu
クエリーを実行するには、セル内をクリックして Shift+Enter キーを押すか、クリックして
 [ セルの実行] を選択します。
[ セルの実行] を選択します。
Catalog Explorer を使用して、これらのクエリによって生成されたリネージを表示するには:
Databricks ワークスペースの上部バーにある検索ボックスで、
lineage_data.lineagedemo.dinnerテーブルを検索して選択します。[ 系列 ] タブを選択します。 系列パネルが表示され、関連するテーブルが表示されます (この例では
menuテーブルです)。データリネージの対話型グラフを表示するには、 「リネージグラフを参照」をクリックします。 デフォルトでは、グラフには 1 つのレベルが表示されます。 ノード上の
 アイコンをクリックすると、使用可能な接続がある場合は、さらに多くの接続が表示されます。
アイコンをクリックすると、使用可能な接続がある場合は、さらに多くの接続が表示されます。リネージ グラフ内のノードを接続する矢印をクリックすると、リネージ接続パネルが開きます。 リネージ接続パネルには、ソーステーブルとターゲットテーブル、ノートブック、ジョブなどの接続に関する詳細が表示されます。
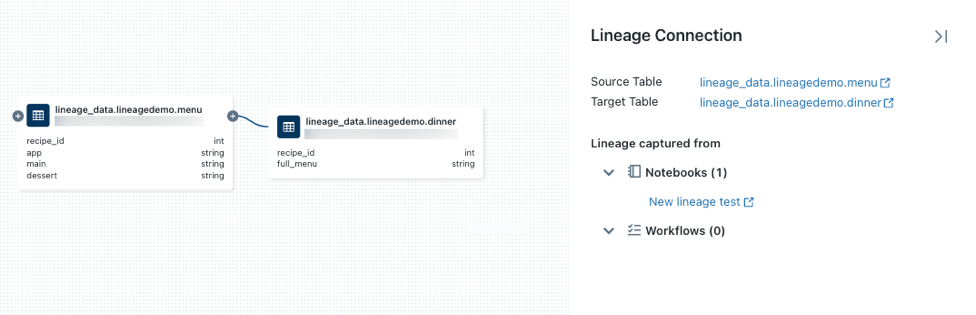
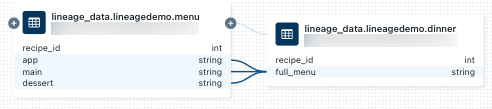
dinnerテーブルに関連付けられたノートブックを表示するには、リネージ接続パネルでノートブックを選択するか、リネージ グラフを閉じてノートブックをクリックします。 ノートブックを新しいタブで開くには、ノートブック名をクリックします。列レベルのリネージを表示するには、グラフ内の列をクリックして関連する列へのリンクを表示します。 たとえば、[full_menu] 列をクリックすると、列の派生元であるアップストリーム列が表示されます。
別の言語Pythonなど)を使用してリネージを表示するには、次のようにします。
前に作成したノートブックを開き、新しいセルを作成して、次の Python コードを入力します。
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")
セル内をクリックして Shift+Enter キーを押すか、
をクリックして [セルの実行] を選択して、セルを実行します。Databricks ワークスペースの上部バーにある検索ボックスで、
lineage_data.lineagedemo.priceテーブルを検索して選択します。「リネージ」タブに移動し、 「リネージグラフを参照」をクリックします。 クリック
アイコンを使用して、クエリによって生成されたデータ リネージを探索します。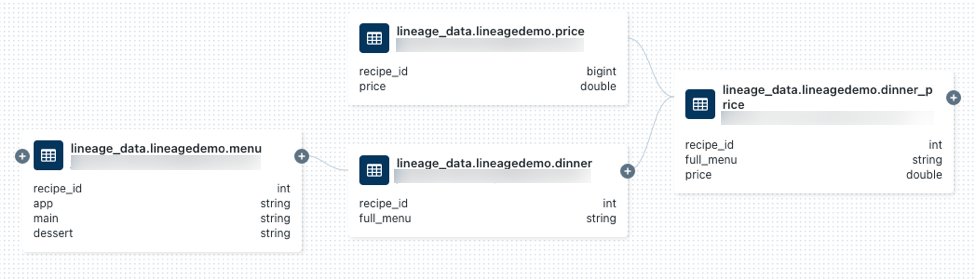
リネージ グラフ内のノードを接続する矢印をクリックすると、リネージ接続パネルが開きます。 リネージ接続パネルには、ソーステーブルとターゲットテーブル、ノートブック、ジョブなどの接続に関する詳細が表示されます。
ワークフロー系列のキャプチャと表示
リネージは、 Unity Catalogの読み取りまたは書き込みを行うワークフローに対してもキャプチャされます。 Databricksのリネージを表示するには:
サイドバーで [
新規 ] をクリックし、メニューから [ ノートブック ] を選択します。ノートブックの名前を入力し、 [デフォルト 言語] で [SQL] を選択します。
[作成]をクリックします。
最初のノートブックのセルに、次のクエリーを入力します。
SELECT * FROM lineage_data.lineagedemo.menu
上部のバーの [スケジュール ] をクリックします。 スケジュールダイアログで、[ 手動] を選択し、 Unity Catalogにアクセスできるクラスターを選択して、[ 作成] をクリックします。
[ 今すぐ実行] をクリックします。
Databricks ワークスペースの上部バーにある検索ボックスで、
lineage_data.lineagedemo.menuテーブルを検索して選択します。「リネージ」タブで「ワークフロー」をクリックし、 「ダウンストリーム」タブを選択します。 ジョブ名は、
menuテーブルのコンシューマーとして[ジョブ名]の下に表示されます。
ダッシュボードの系列をキャプチャして表示する
ダッシュボードを作成してそのデータ変更を表示するには:
Databricks ランディングページに移動し、サイドバーの[カタログ]をクリックしてカタログ エクスプローラーを開きます。
カタログ名をクリックし、[ lineagedemo] をクリックして、
menuテーブルを選択します。 トップバーの [検索 ] ボックスを使用して、menuテーブルを検索することもできます。[ダッシュボードで開く] をクリックします。
ダッシュボードに追加する列を選択し、[ 作成] をクリックします。
ダッシュボードを公開します。
データリネージでは公開されたダッシュボードのみが追跡されます。
上部のバーの [検索 ] ボックスで、
lineage_data.lineagedemo.menuテーブルを検索して選択します。[リネージ]タブで、 [ダッシュボード]をクリックします。 ダッシュボードは、メニューテーブルのコンシューマーとして [ダッシュボード名 ] の下に表示されます。
リネージのアクセス許可
リネージグラフは、 と同じ 権限モデル Unity Catalogを共有しています。Unity Catalog メタストアに登録されているテーブルやその他のデータ オブジェクトは、それらのオブジェクトに対して少なくとも BROWSE のアクセス許可を持つユーザーにのみ表示されます。 ユーザーがテーブルに対する BROWSE 権限または SELECT 権限を持っていない場合、そのリネージを探索できません。 リネージ グラフには、ユーザーが適切なオブジェクト アクセス許可を持っている限り、メタストアに接続されているすべてのワークスペースの Unity Catalog オブジェクトが表示されます。
たとえば、次のコマンドを実行します userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
userAがlineage_data.lineagedemo.menuテーブルのリネージ グラフを表示すると、 menuテーブルが表示されます。 ダウンストリームのlineage_data.lineagedemo.dinnerテーブルなど、関連するテーブルに関する情報を表示することはできません。 dinnerテーブルは、userA表示にmaskedノードとして表示され、userAグラフを展開して、アクセス権限のないテーブルからダウンストリームテーブルを表示することはできません。
次のコマンドを実行して、 BROWSE にパーミッションを userBに付与すると、そのユーザーは lineage_data スキーマ内の任意のテーブルのリネージグラフを表示できます。
GRANT BROWSE on lineage_data to `userB@company.com`;
同様に、リネージユーザーは、ノートブック、ジョブ、ダッシュボードなどのワークスペースオブジェクトを表示するための特定の権限を持っている必要があります。 また、ワークスペースオブジェクトに関する詳細情報を表示できるのは、そのオブジェクトが作成されたワークスペースにログインしている場合のみです。 他のワークスペース内のワークスペースレベルのオブジェクトに関する詳細な情報は、リネージグラフではマスクされます。
Unity Catalog内のセキュリティ保護可能なオブジェクトへのアクセスの管理の詳細については、 Unity Catalogでの権限の管理」を参照してください。 ノートブック、ジョブ、ダッシュボードなどのワークスペース オブジェクトへのアクセス管理の詳細については、 「アクセス制御リスト」を参照してください。
系列データの削除
警告
次の手順では、 Unity Catalogに格納されているすべてのオブジェクトを削除します。 これらの手順は、必要な場合にのみ使用してください。 たとえば、コンプライアンス要件を満たすためなどです。
リネージデータを削除するには、 Unity Catalog オブジェクトを管理しているメタストアを削除する必要があります。 メタストアの削除の詳細については、「 メタストアの削除」を参照してください。 データは 90 日以内に削除されます。
システムテーブルを使用してリネージデータをクエリする
リネージ システムテーブルを使用して、プログラムでリネージ データをクエリできます。 詳細な手順については、 システムテーブルを使用したアカウントアクティビティの監視 および リネージ システムテーブルリファレンスを参照してください。
ワークスペースがリネージ システムテーブルをサポートしていないリージョンにある場合は、代わりにデータリネージREST APIを使用してプログラムでリネージ データを取得することもできます。
データリネージREST APIを使用してリネージを取得する
データリネージAPIと、テーブルと列のリネージを取得できます。 ただし、ワークスペースが REST システムテーブルをサポートするリージョンにある場合は、 REST APIではなく、システムテーブル クエリを使用する必要があります。 システムテーブルは、リネージ データをプログラムで取得するためのより適切なオプションです。 ほとんどの地域でリネージ システムテーブルがサポートされています。
重要
Databricks REST APIsにアクセスするには、 認証する必要があります。
テーブル系列の取得
この例では、 dinner テーブルの系列データを取得します。
依頼
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
<workspace-instance>を交換してください。
この例では 、.netrc を使用します。 ファイル。
応答
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
列系列の取得
この例では、 dinner テーブルの列データを取得します。
依頼
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
<workspace-instance>を交換してください。
この例では 、.netrc を使用します。 ファイル。
応答
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
制限
リネージは、同じ Unity Catalog メタストアにアタッチされているすべてのワークスペースに対して集約されますが、ノートブックやダッシュボードなどのワークスペース オブジェクトの詳細は、それらが作成されたワークスペースにのみ表示されます。
リネージは1年間のローリングウィンドウでコンピュートされるため、1年以上前に収集されたリネージは表示されません。 たとえば、ジョブまたはクエリがテーブル A からデータを読み取り、テーブル B に書き込む場合、テーブル A とテーブル B 間のリンクは 1 年間のみ表示されます。 リネージ データを 1 年間の期間内で期間別にフィルタリングできます。
リネージを表示する場合、ジョブAPI
runs submitリクエストを使用するジョブは利用できません。runs submitリクエストを使用する場合、テーブルおよび列レベルのリネージは引き続きキャプチャされますが、実行へのリンクはキャプチャされません。Unity Catalog は、可能な限り列レベルまでの系列をキャプチャします。 ただし、列レベルの系列をキャプチャできない場合があります。
列リネージは、ソースとターゲットの両方がテーブル名で参照されている場合にのみサポートされます (例:
select * from <catalog>.<schema>.<table>)。 ソース またはターゲットがパスによってアドレス指定されている場合、列 リネージ をキャプチャすることはできません (例:select * from delta."s3://<bucket>/<path>")。テーブルまたはビューの名前が変更された場合、名前が変更されたテーブルまたはビューに対してリネージはキャプチャされません。
スキーマまたはカタログの名前が変更された場合、名前が変更されたカタログまたはスキーマの下にあるテーブルおよびビューに対してリネージはキャプチャされません。
Spark SQLデータセットのチェックポイント設定を使用すると、リネージはキャプチャされません。
Unity Catalog は、ほとんどの場合、Delta Live Tables パイプラインからリネージをキャプチャします。 ただし、パイプラインが APPLY CHANGES API または TEMPORARY テーブルを使用する場合など、完全なリネージ カバレッジが保証されない場合があります。
リネージはスタック関数をキャプチャしません。
グローバル一時ビューはリネージにキャプチャされません。
system.information_schema未満のテーブルはリネージにキャプチャされません。完全な列レベルのリネージは、
MERGE操作のためにデフォルトによってキャプチャされません。MERGE操作のリネージキャプチャをオンにするには、 Spark プロパティのspark.databricks.dataLineage.mergeIntoV2Enabledをtrueに設定します。 このフラグを有効にすると、特に非常に幅の広いテーブルを含むワークロードで、クエリのパフォーマンスが低下する可能性があります。