Capture e visualize a linhagem de dados usando o Unity Catalog
Este artigo descreve como capturar e visualizar a linhagem de dados usando o Catalog Explorer, as tabelas do sistema de linhagem de dados e o site REST API.
O senhor pode usar o Unity Catalog para capturar a linhagem de dados em tempo de execução nas consultas executadas no Databricks. A linhagem é compatível com todos os idiomas e é capturada até o nível da coluna. Os dados de linhagem incluem Notebook, Job e dashboards relacionados à consulta. A linhagem pode ser visualizada no Catalog Explorer quase em tempo real e recuperada de forma programática usando as tabelas do sistema de linhagem e a API REST da Databricks.
A linhagem é agregada em todos os espaços de trabalho anexados a um metastore Unity Catalog. Isso significa que a linhagem capturada em um workspace é visível em qualquer outro workspace que compartilhe esse metastore. Especificamente, as tabelas e outros objetos de dados registrados no metastore são visíveis para os usuários que têm pelo menos BROWSE permissões sobre esses objetos, em todos os espaços de trabalho anexados ao metastore. No entanto, as informações detalhadas sobre objetos de nível workspace, como Notebook e painéis em outro espaço de trabalho, são ocultadas (consulte Limitações e permissões de linhagem).
Os dados de linhagem são retidos por um ano.
A imagem a seguir é um exemplo de gráfico de linhagem. A funcionalidade e os exemplos específicos da linhagem de dados são abordados mais adiante neste artigo.
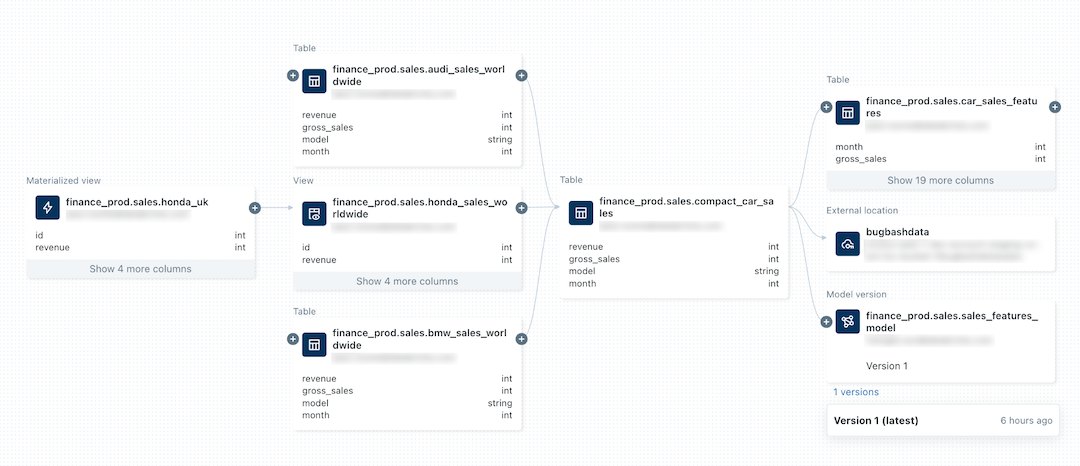
Para obter informações sobre o acompanhamento da linhagem de um modelo do aprendizado de máquina, consulte Acompanhar a linhagem de dados de um modelo em Unity Catalog.
Requisitos
Os itens a seguir são necessários para capturar a linhagem de dados usando o Unity Catalog:
O workspace deve ter o Unity Catalog ativado.
As tabelas devem ser registradas em um metastore Unity Catalog .
query deve usar o Spark DataFrame (por exemplo, funções Spark SQL que retornam um DataFrame) ou interfaces Databricks SQL. Para obter exemplos de query Databricks SQL e PySpark, consulte Exemplos.
Para view a linhagem de uma tabela ou view, os usuários devem ter pelo menos o privilégio
BROWSEno catálogo pai da tabela ou view. O catálogo principal também deve estar acessível no site workspace. Consulte Limitar o acesso do catálogo a um espaço de trabalho específico.Para view informações de linhagem para Notebook, Job ou dashboards, os usuários devem ter permissões nesses objetos, conforme definido pelas configurações de controle de acesso em workspace. Consulte Permissões de linhagem.
Para view a linhagem de um pipeline habilitado para Unity Catalog, você deve ter permissões
CAN_VIEWno pipeline.O acompanhamento da transmissão da linhagem entre as tabelas Delta requer Databricks Runtime 11.3 LTS ou acima.
O acompanhamento da linhagem de colunas para cargas de trabalho Delta Live Tables requer Databricks Runtime 13.3 LTS ou acima.
Exemplos
Observação
Os exemplos a seguir usam o nome do catálogo
lineage_datae o nome do esquemalineagedemo. Para usar um catálogo e esquema diferente, altere os nomes usados nos exemplos.Para concluir esse exemplo, você deve ter os privilégios
CREATEeUSE SCHEMAem um esquema. Um administrador da metastore, proprietário do catálogo, proprietário do esquema ou usuário com o privilégioMANAGEno esquema pode conceder esses privilégios. Por exemplo, para dar a todos os usuários do grupo 'data_engineers' permissão para criar tabelas no esquemalineagedemono catálogolineage_data, um usuário com um dos privilégios ou funções acima pode executar as seguintes consultas:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Capture e explore a linhagem
Para capturar dados de linhagem:
Vá para suas páginas Databricks de aterrissagem, clique
 Novo na barra lateral e selecione Notebook no menu.
Novo na barra lateral e selecione Notebook no menu.Digite um nome para o Notebook e selecione SQL no idiomadefault .
Em clusters, selecione um clusters com acesso ao Unity Catalog.
Clique em Criar.
Na primeira célula Notebook , insira a seguinte query:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menu
Para executar a query, clique na célula e pressione shift+enter ou clique
 e selecione a célula de execução.
e selecione a célula de execução.
Para usar o Catalog Explorer para view a linhagem gerada por essas consultas:
Na caixa Search (Pesquisar ) na barra superior do site Databricks workspace, procure a tabela
lineage_data.lineagedemo.dinnere selecione-a.Selecione a tab Linhagem . O painel de linhagem aparece e exibe tabelas relacionadas (neste exemplo, é a tabela
menu).Para view um gráfico interativo da linhagem de dados, clique em See Lineage gráfico. Em default, um nível é exibido no gráfico. Clique no ícone
 em um nó para revelar mais conexões, se estiverem disponíveis.
em um nó para revelar mais conexões, se estiverem disponíveis.Clique em uma seta que conecta os nós no gráfico de linhagem para abrir o painel de conexão de linhagem. O painel de conexão do Lineage mostra detalhes sobre a conexão, incluindo tabelas de origem e destino, Notebook e Job.
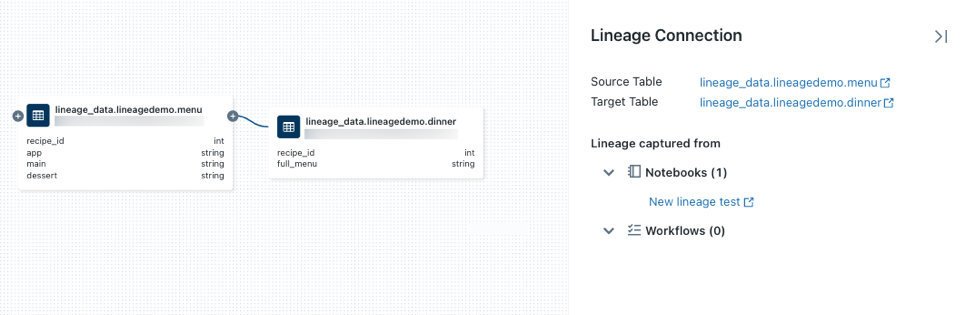
Para mostrar o Notebook associado à tabela
dinner, selecione o Notebook no painel de conexão Lineage ou feche o gráfico de lineage e clique em Notebook. Para abrir o Notebook em um novo tab, clique no nome Notebook.Para view a linhagem em nível de coluna, clique em uma coluna no gráfico para mostrar links para colunas relacionadas. Por exemplo, clicar na coluna "full_menu" mostra as colunas upstream das quais a coluna foi derivada:
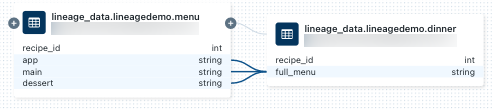
Para view lineage usando um idioma diferente, por exemplo, Python:
Abra o Notebook que você criou anteriormente, crie uma nova célula e digite o seguinte código Python:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")
executar a célula clicando na célula e pressionando shift+enter ou clicando
e selecionando Cell de execução.Na caixa Search (Pesquisar ) na barra superior do site Databricks workspace, procure a tabela
lineage_data.lineagedemo.pricee selecione-a.Acesse Lineage tab e clique em See Lineage gráfico. Clique nos ícones
para explorar a linhagem de dados gerada pelas consultas.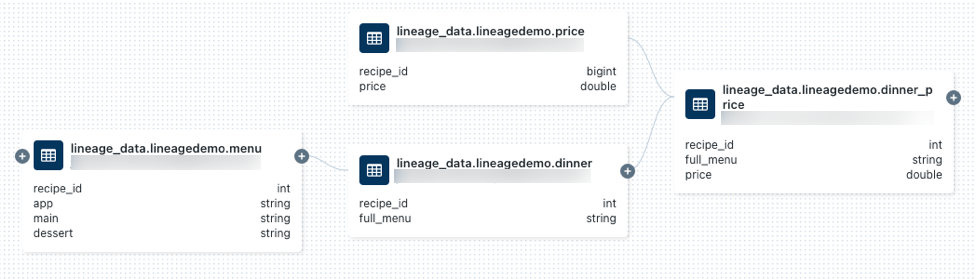
Clique em uma seta que conecta os nós no gráfico de linhagem para abrir o painel de conexão de linhagem. O painel de conexão do Lineage mostra detalhes sobre a conexão, incluindo tabelas de origem e destino, Notebook e Job.
Capture e visualize a linhagem do fluxo de trabalho
A linhagem também é capturada para qualquer fluxo de trabalho que leia ou grave no Unity Catalog. Para view lineage para um Databricks fluxo de trabalho:
Clique
Novo na barra lateral e selecione Notebook no menu.Digite um nome para o Notebook e selecione SQL no idiomadefault .
Clique em Criar.
Na primeira célula Notebook , insira a seguinte query:
SELECT * FROM lineage_data.lineagedemo.menu
Clique em programar na barra superior. Na caixa de diálogo do programar, selecione Manual, selecione um clusters com acesso ao Unity Catalog e clique em Create.
Clique em execução agora.
Na caixa Search (Pesquisar ) na barra superior do site Databricks workspace, procure a tabela
lineage_data.lineagedemo.menue selecione-a.Em Lineage tab, clique em fluxo de trabalho e selecione Downstream tab. O nome Job aparece em Job Name como um consumidor da tabela
menu.
Capture e visualize a linhagem do painel
Para criar um dashboard e view sua linhagem de dados:
Vá para as páginas de aterrissagem da Databricks e abra o Catalog Explorer clicando em Catalog na barra lateral.
Clique no nome do catálogo, clique em lineagedemo e selecione a tabela
menu. O senhor também pode usar a caixa Search (Pesquisar ) na barra superior para pesquisar a tabelamenu.Clique em Open in a dashboard (Abrir em um painel).
Selecione as colunas que o senhor deseja adicionar ao painel e clique em Create (Criar).
Publicar o painel.
Somente os painéis publicados são rastreados na linhagem de dados.
Na caixa Search (Pesquisar ) na barra superior, procure a tabela
lineage_data.lineagedemo.menue selecione-a.No site da Lineage tab, clique em Dashboards. O painel aparece em Dashboard Name como um consumidor da tabela de menus.
Permissões de linhagem
O Lineage gráfico compartilha o mesmo modelo de permissão que o Unity Catalog. As tabelas e outros objetos de dados registrados no metastore do Unity Catalog são visíveis apenas para usuários que tenham pelo menos BROWSE permissões sobre esses objetos. Se um usuário não tiver o privilégio BROWSE ou SELECT em uma tabela, ele não poderá explorar sua linhagem. O Lineage gráfico exibe Unity Catalog objetos em todos os espaços de trabalho anexados ao metastore, desde que o usuário tenha as permissões de objeto adequadas.
Por exemplo, execute o seguinte comando para userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Quando userA visualizar o gráfico de linhagem da tabela lineage_data.lineagedemo.menu, ele verá a tabela menu. Eles não poderão ver informações sobre tabelas associadas, como a tabela lineage_data.lineagedemo.dinner downstream. A tabela dinner é exibida como um nó masked na exibição para userA, e userA não pode expandir o gráfico para revelar tabelas downstream de tabelas para as quais não tem permissão de acesso.
Se o senhor executar o comando a seguir para conceder a permissão BROWSE a userB, esse usuário poderá view o gráfico de linhagem de qualquer tabela no esquema lineage_data:
GRANT BROWSE on lineage_data to `userB@company.com`;
Da mesma forma, os usuários de linhagem devem ter permissões específicas para view workspace objetos como Notebook, Job e dashboards. Além disso, eles só podem ver informações detalhadas sobre os objetos do workspace quando estiverem conectados ao workspace no qual esses objetos foram criados. Informações detalhadas sobre objetos de nível workspaceem outro espaço de trabalho são mascaradas no gráfico de linhagem.
Para obter mais informações sobre como gerenciar o acesso a objetos protegidos em Unity Catalog, consulte gerenciar privilégios em Unity Catalog. Para obter mais informações sobre como gerenciar o acesso a objetos do site workspace, como Notebook, Job e dashboards, consulte Listas de controle de acesso.
Excluir dados de linhagem
Aviso
As instruções a seguir excluem todos os objetos armazenados no Unity Catalog. Use estas instruções somente se necessário. Por exemplo, para atender aos requisitos compliance .
Para excluir os dados de linhagem, o senhor deve excluir o metastore que gerencia os objetos do Unity Catalog. Para obter mais informações sobre a exclusão do metastore, consulte Excluir um metastore. Os dados serão excluídos dentro de 90 dias.
Consulta de linhagem uso de dados tabelas do sistema
Você pode usar as tabelas do sistema de linhagem para consultar dados de linhagem de forma programática. Para obter instruções detalhadas, consulte Monitorar a atividade do account com tabelas de sistema e Referência de tabelas de sistema do Lineage.
Se o seu site workspace estiver em uma região que não ofereça suporte a tabelas do sistema de linhagem, o senhor poderá usar a linhagem de dados REST API para recuperar dados de linhagem de forma programática.
Recuperar a linhagem usando a API REST da linhagem de dados
A API de linhagem de dados permite que o senhor recupere a linhagem de tabelas e colunas. No entanto, se o seu workspace estiver em uma região que ofereça suporte às tabelas do sistema de linhagem, o senhor deverá usar as consultas da tabela do sistema em vez do REST API. As tabelas do sistema são uma opção melhor para a recuperação programática de dados de linhagem. A maioria das regiões suporta as tabelas do sistema de linhagem.
Importante
Para acessar APIs REST do Databricks, você deve autenticar o.
Recuperar linhagem da tabela
Este exemplo recupera dados de linhagem para a tabela dinner .
Solicitar
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Substitua <workspace-instance>.
Este exemplo usa um .netrc arquivo.
Resposta
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Recuperar linhagem de coluna
Este exemplo recupera dados de coluna para a tabela dinner .
Solicitar
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Substitua <workspace-instance>.
Este exemplo usa um .netrc arquivo.
Resposta
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Limitações
Embora a linhagem seja agregada a todos os espaços de trabalho anexados ao mesmo metastore Unity Catalog, os detalhes dos objetos workspace, como o Notebook e os painéis, são visíveis apenas no workspace em que foram criados.
Como a linhagem é calculada em uma janela móvel de um ano, a linhagem coletada há mais de um ano não é exibida. Por exemplo, se um Job ou uma consulta ler dados da tabela A e gravar na tabela B, o link entre a tabela A e a tabela B será exibido somente por um ano. O senhor pode filtrar os dados de linhagem por período de tempo dentro da janela de um ano.
Os trabalhos que usam a solicitação Jobs API
runs submitnão estão disponíveis ao visualizar a linhagem. A linhagem em nível de tabela e coluna ainda é capturada ao usar a solicitaçãoruns submit, mas o link para a execução não é capturado.O Unity Catalog captura a linhagem no nível da coluna o máximo possível. No entanto, há alguns casos em que a linhagem no nível da coluna não pode ser capturada.
A linhagem de coluna é compatível somente quando a origem e o destino são referenciados pelo nome da tabela (Exemplo:
select * from <catalog>.<schema>.<table>). A linhagem da coluna não pode ser capturada se a origem ou o destino for endereçado pelo caminho (Exemplo:select * from delta."s3://<bucket>/<path>").Se uma tabela ou view for renomeado, a linhagem não será capturada para a tabela ou view renomeado.
Se um esquema ou catálogo for renomeado, a linhagem não será capturada para tabelas e visualizações no catálogo ou esquema renomeado.
Se o senhor usar Spark SQL dataset checkpointing, a linhagem não será capturada.
O Unity Catalog captura a linhagem do pipeline Delta Live Tables na maioria dos casos. No entanto, em alguns casos, a cobertura completa da linhagem não pode ser garantida, como quando pipeline usa a API APPLY CHANGES ou as tabelas TEMPORARY.
A linhagem não captura as funções de pilha.
A visualização temporária global não é capturada na linhagem.
Tabelas abaixo de
system.information_schemanão são capturadas na linhagem.A linhagem completa em nível de coluna não é capturada pelo site default para
MERGEoperações.O senhor pode ativar a captura de linhagem para as operações
MERGEdefinindo a propriedade Sparkspark.databricks.dataLineage.mergeIntoV2Enabledcomotrue. A ativação desse sinalizador pode reduzir o desempenho da consulta, principalmente em cargas de trabalho que envolvem tabelas muito amplas.