Unity Catalog best practices
This document provides recommendations for using Unity Catalog and Delta Sharing to meet your data governance needs.
Unity Catalog is a fine-grained governance solution for data and AI on the Databricks platform. It helps simplify security and governance of your data by providing a central place to administer and audit data access. Delta Sharing is a secure data sharing platform that lets you share data in Databricks with users outside your organization. It uses Unity Catalog to manage and audit sharing behavior.
Data governance and data isolation building blocks
To develop a data governance model and a data isolation plan that works for your organization, it helps to understand the primary building blocks that are available to you when you create your data governance solution in Databricks.
The following diagram illustrates the primary data hierarchy in Unity Catalog (some securable objects are grayed out to emphasize the hierarchy of objects managed under catalogs).
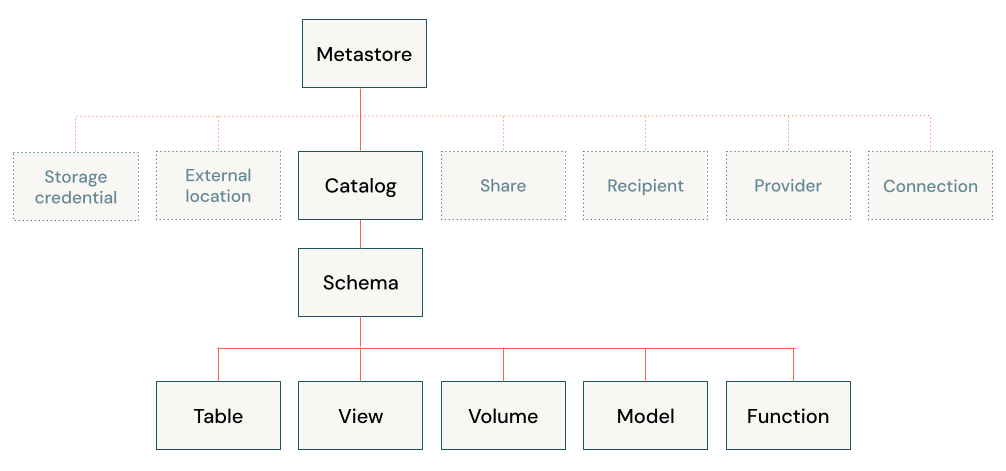
The objects in that hierarchy include the following:
Metastore: A metastore is the top-level container of objects in Unity Catalog. Metastores live at the account level and function as the top of the pyramid in the Databricks data governance model.
Metastores manage data assets (tables, views, and volumes) and the permissions that govern access to them. Databricks account admins can create one metastore for each region in which they operate, and assign them to multiple Databricks workspaces in the same region. Metastore admins can manage all objects in the metastore. They don’t have direct access to read and write to tables registered in the metastore, but they do have indirect access through their ability to transfer data object ownership.
Physical storage for any given metastore is, by default, isolated from storage for any other metastore in your account.
Metastores provide regional isolation but are not intended as units of data isolation. Data isolation should begin at the catalog level.
Catalog: Catalogs are the highest level in the data hierarchy (catalog > schema > table/view/volume) managed by the Unity Catalog metastore. They are intended as the primary unit of data isolation in a typical Databricks data governance model.
Catalogs represent a logical grouping of schemas, usually bounded by data access requirements. Catalogs often mirror organizational units or software development lifecycle scopes. You may choose, for example, to have a catalog for production data and a catalog for development data, or a catalog for non-customer data and one for sensitive customer data.
Catalogs can be stored at the metastore level, or you can configure a catalog to be stored separately from the rest of the parent metastore. If your workspace was enabled for Unity Catalog automatically, there is no metastore-level storage, and you must specify a storage location when you create a catalog.
If the catalog is the primary unit of data isolation in the Databricks data governance model, the workspace is the primary environment for working with data assets. Metastore admins and catalog owners can manage access to catalogs independently of workspaces, or they can bind catalogs to specific workspaces to ensure that certain kinds of data are processed only in those workspaces. You might want separate production and development workspaces, for example, or a separate workspace for processing personal data.
By default, access permissions for a securable object are inherited by the children of that object, with catalogs at the top of the hierarchy. This makes it easier to set up default access rules for your data and to specify different rules at each level of the hierarchy only where you need them.
Schema (Database): Schemas, also known as databases, are logical groupings of tabular data (tables and views), non-tabular data (volumes), functions, and machine learning models. They give you a way to organize and control access to data that is more granular than catalogs. Typically they represent a single use case, project, or team sandbox.
Schemas can be stored in the same physical storage as the parent catalog, or you can configure a schema to be stored separately from the rest of the parent catalog.
Metastore admins, parent catalog owners, and schema owners can manage access to schemas.
Tables: Tables reside in the third layer of Unity Catalog’s three-level namespace. They contains rows of data.
Unity Catalog lets you create managed tables and external tables.
For managed tables, Unity Catalog fully manages the lifecycle and file layout. By default, managed tables are stored in the root storage location that you configure when you create a metastore. You can choose instead to isolate storage for managed tables at the catalog or schema levels.
External tables are tables whose data lifecycle and file layout are managed using your cloud provider and other data platforms, not Unity Catalog. Typically you use external tables to register large amounts of your existing data, or if you also require write access to the data using tools outside of Databricks clusters and Databricks SQL warehouses. Once an external table is registered in a Unity Catalog metastore, you can manage and audit Databricks access to it just like you can with managed tables.
Parent catalog owners and schema owners can manage access to tables, as can metastore admins (indirectly).
Views: A view is a read-only object derived from one or more tables and views in a metastore.
Rows and columns: Row and column-level access, along with data masking, is granted using either dynamic views or row filters and column masks. Dynamic views are read-only.
Volumes: Volumes reside in the third layer of Unity Catalog’s three-level namespace. They manage non-tabular data. You can use volumes to store, organize, and access files in any format, including structured, semi-structured, and unstructured data. Files in volumes cannot be registered as tables.
Models and functions: Although they are not, strictly speaking, data assets, registered models and user-defined functions can also be managed in Unity Catalog and reside at the lowest level in the object hierarchy. See Manage model lifecycle in Unity Catalog and User-defined functions (UDFs) in Unity Catalog.
Plan your data isolation model
When an organization uses a data platform like Databricks, there is often a need to have data isolation boundaries between environments (such as development and production) or between organizational operating units.
Isolation standards might vary for your organization, but typically they include the following expectations:
Users can only gain access to data based on specified access rules.
Data can be managed only by designated people or teams.
Data is physically separated in storage.
Data can be accessed only in designated environments.
The need for data isolation can lead to siloed environments that can make both data governance and collaboration unnecessarily difficult. Databricks solves this problem using Unity Catalog, which provides a number of data isolation options while maintaining a unified data governance platform. This section discusses the data isolation options available in Databricks and how to use them, whether you prefer a centralized data governance model or a distributed one.
Users can only gain access to data based on specified access rules
Most organizations have strict requirements around data access based on internal or regulatory requirements. Typical examples of data that must be kept secure include employee salary information or credit card payment information. Access to this type of information is typically tightly controlled and audited periodically. Unity Catalog provides you with granular control over data assets within the catalog to meet these industry standards. With the controls that Unity Catalog provides, users can see and query only the data that they are entitled to see and query.
Data can be managed only by designated people or teams
Unity Catalog gives you the ability to choose between centralized and distributed governance models.
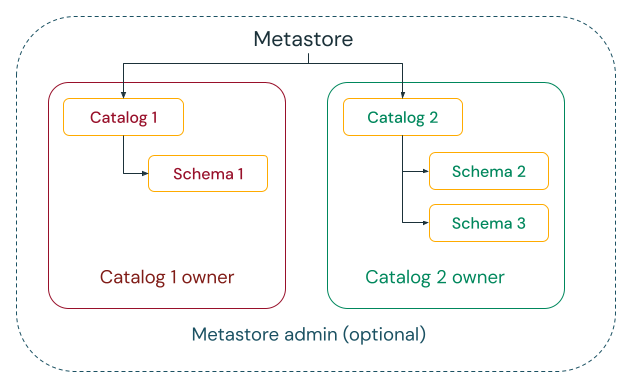
In the centralized governance model, your governance administrators are owners of the metastore and can take ownership of any object and grant and revoke permissions.
In a distributed governance model, the catalog or a set of catalogs is the data domain. The owner of that catalog can create and own all assets and manage governance within that domain. The owners of any given domain can operate independently of the owners of other domains.
Regardless of whether you choose the metastore or catalogs as your data domain, Databricks strongly recommends that you set a group as the metastore admin or catalog owner.
Owners can grant users, service principals, and groups the MANAGE permission to allow them to grant and revoke permissions on objects.
Data is physically separated in storage
An organization can require that data of certain types be stored within specific accounts or buckets in their cloud tenant.
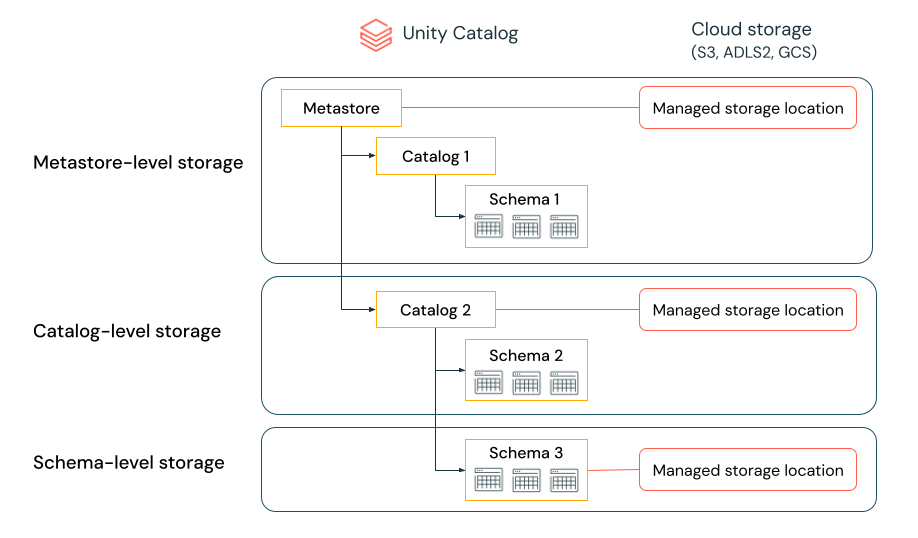
Unity Catalog gives the ability to configure storage locations at the metastore, catalog, or schema level to satisfy such requirements.
For example, let’s say your organization has a company compliance policy that requires production data relating to human resources to reside in the bucket gs://mycompany-hr-prod. In Unity Catalog, you can achieve this requirement by setting a location on a catalog level, creating a catalog called, for example hr_prod, and assigning the location gs://mycompany-hr-prod/unity-catalog to it. This means that managed tables or volumes created in the hr_prod catalog (for example, using CREATE TABLE hr_prod.default.table …) store their data in gs://mycompany-hr-prod/unity-catalog. Optionally, you can choose to provide schema-level locations to organize data within the hr_prod catalog at a more granular level.
If such a storage isolation is not required, you can set a storage location at the metastore level. The result is that this location serves as a default location for storing managed tables and volumes across catalogs and schemas in the metastore.
The system evaluates the hierarchy of storage locations from schema to catalog to metastore.
For example, if a table myCatalog.mySchema.myTable is created in my-region-metastore, the table storage location is determined according to the following rule:
If a location has been provided for
mySchema, it will be stored there.If not, and a location has been provided on
myCatalog, it will be stored there.Finally, if no location has been provided on
myCatalog, it will be stored in the location associated with themy-region-metastore.
Data can be accessed only in designated environments
Organizational and compliance requirements often specify that you keep certain data, like personal data, accessible only in certain environments. You may also want to keep production data isolated from development environments or ensure that certain data sets and domains are never joined together.
In Databricks, the workspace is the primary data processing environment, and catalogs are the primary data domain. Unity Catalog lets metastore admins, catalog owners, and users with the MANAGE permission assign, or “bind,” catalogs to specific workspaces. These environment-aware bindings give you the ability to ensure that only certain catalogs are available within a workspace, regardless of the specific privileges on data objects granted to a user.
Now let’s take a deeper look at the process of setting up Unity Catalog to meet your needs.
Configure a Unity Catalog metastore
A metastore is the top-level container of objects in Unity Catalog. Metastores manage data assets (tables, views, and volumes) as well as other securable objects managed by Unity Catalog. For the complete list of securable objects, see Securable objects in Unity Catalog.
This section provides tips for creating and configuring metastores. If your workspace was automatically enabled for Unity Catalog, you do not need to create a metastore, but the information presented in this section might still be useful. See Automatic enablement of Unity Catalog.
Tips for configuring metastores:
You should set up one metastore for each region in which you have Databricks workspaces.
Every workspace attached to a single regional metastore has access to the data managed by the metastore. If you want to share data between metastores, use Delta Sharing.
Each metastore can be configured with a managed storage location (also called root storage) in your cloud tenant that can be used to store managed tables and managed volumes.
If you choose to create a metastore-level managed location, you must ensure that no users have direct access to it (that is, through the cloud account that contains it). Giving access to this storage location could allow a user to bypass access controls in a Unity Catalog metastore and disrupt auditability. For these reasons, your metastore managed storage should be a dedicated bucket. You should not reuse a bucket that is also your DBFS root file system or has previously been a DBFS root file system.
You also have the option of defining managed storage at the catalog and schema levels, overriding the metastore’s root storage location. In most scenarios, Databricks recommends storing managed data at the catalog level.
You should understand the privileges of workspace admins in workspaces that are enabled for Unity Catalog, and review your existing workspace admin assignments.
Workspace admins can manage operations for their workspace including adding users and service principals, creating clusters, and delegating other users to be workspace admins. If your workspace was enabled for Unity Catalog automatically, workspace admins have the ability to create catalogs and many other Unity Catalog objects by default. See Workspace admin privileges when workspaces are enabled for Unity Catalog automatically
Workspace admins also have the ability to perform workspace management tasks such as managing job ownership and viewing notebooks, which may give indirect access to data registered in Unity Catalog. Workspace admin is a privileged role that you should distribute carefully.
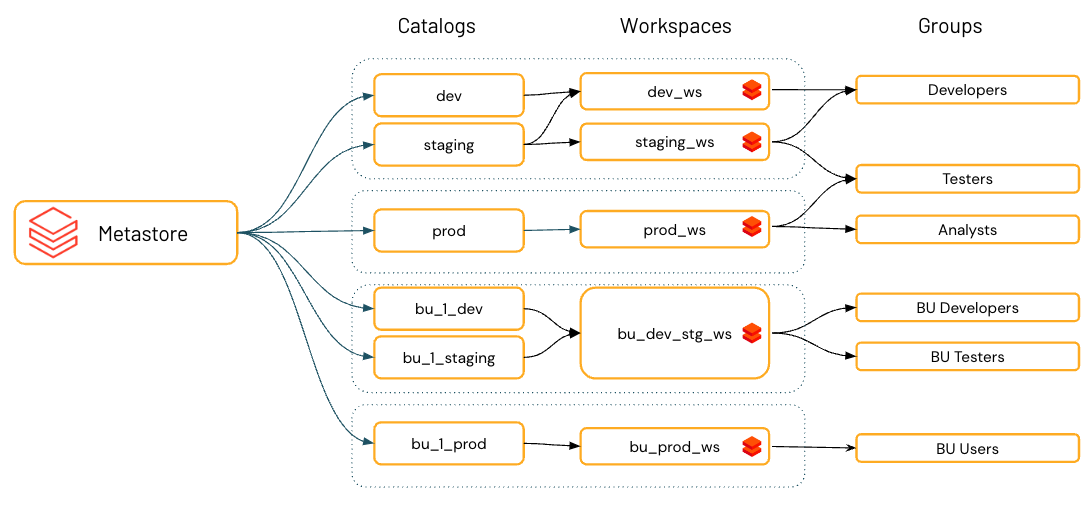
If you use workspaces to isolate user data access, you might want to use workspace-catalog bindings. Workspace-catalog bindings enable you to limit catalog access by workspace boundaries. For example, you can ensure that workspace admins and users can only access production data in
prod_catalogfrom a production workspace environment,prod_workspace. The default is to share the catalog with all workspaces attached to the current metastore. See Limit catalog access to specific workspaces.If your workspace was enabled for Unity Catalog automatically, the pre-provisioned workspace catalog is bound to your workspace by default.
Configure external locations and storage credentials
External locations allow Unity Catalog to read and write data on your cloud tenant on behalf of users. External locations are defined as a path to cloud storage, combined with a storage credential that can be used to access that location.
You can use external locations to register external tables and external volumes in Unity Catalog. The content of these entities is physically located on a sub-path in an external location that is referenced when a user creates the volume or the table.
A storage credential encapsulates a long-term cloud credential that provides access to cloud storage. For example, in GCP you can configure a service account and give it role-based access to a GCS bucket.
For increased data isolation, you can bind storage credentials and external locations to specific workspaces. See (Optional) Assign an external location to specific workspaces and (Optional) Assign a storage credential to specific workspaces.
Tip
External locations, by combining storage credentials and storage paths, provide strong control and auditability of storage access. To prevent users from bypassing the access control provided by Unity Catalog, you should ensure that you limit the number of users with direct access to any bucket that is being used as an external location. For the same reason, you should not mount storage accounts to DBFS if they are also being used as external locations. Databricks recommends that you migrate mounts on cloud storage locations to external locations in Unity Catalog using Catalog Explorer.
For a list of best practices for managing external locations, see Manage external locations, external tables, and external volumes. See also Create an external location to connect cloud storage to Databricks.
Organize your data
Databricks recommends using catalogs to provide segregation across your organization’s information architecture. Often this means that catalogs correspond to a software development environment scope, team, or business unit. If you use workspaces as a data isolation tool—for example, using different workspaces for production and development environments, or a specific workspace for working with highly sensitive data, you can also bind a catalog to specific workspaces. This ensures that all processing of specified data is handled in the appropriate workspace. See Limit catalog access to specific workspaces.
A schema (also called a database) is the second layer of Unity Catalog’s three-level namespace and organizes tables, views, and volumes. You can use schemas to organize and define permissions for your assets.
Objects governed by Unity Catalog can be managed or external:
Managed objects are the default way to create data objects in Unity Catalog.
Unity Catalog manages the lifecycle and file layout for these securables. You should not use tools outside of Databricks to manipulate files in managed tables or volumes directly.
Managed tables and volumes are stored in managed storage, which can exist at the metastore, catalog, or schema level for any given table or volume. See Data is physically separated in storage.
Managed tables and volumes are a convenient solution when you want to provision a governed location for your content without the overhead of creating and managing external locations and storage credentials.
Managed tables always use the Delta table format.
External objects are securables whose data lifecycle and file layout are not managed by Unity Catalog.
External volumes and tables are registered on an external location to provide access to large numbers of files that already exist in cloud storage without requiring data copy activity. Use external objects when you have files that are produced by other systems and want them staged for access from within Databricks, or when tools outside of Databricks require direct access to these files.
External tables support Delta Lake and many other data formats, including Parquet, JSON, and CSV. Both managed and external volumes can be used to access and store files of arbitrary formats: data can be structured, semi-structured, or unstructured.
For more information about creating tables and volumes, see What are tables and views? and What are Unity Catalog volumes?.
Manage external locations, external tables, and external volumes
The diagram below represents the filesystem hierarchy of a single cloud storage bucket, with four external locations that share one storage credential.
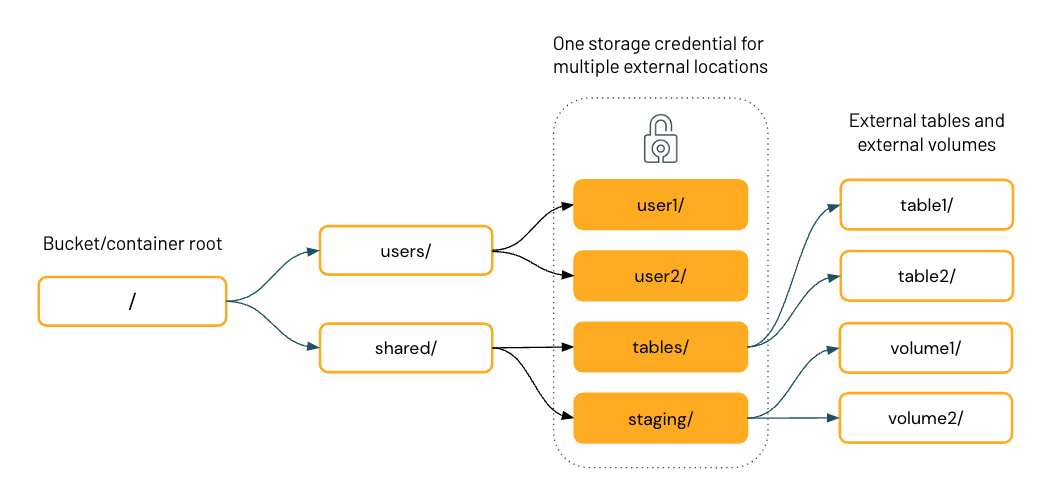
Once you have external locations configured in Unity Catalog, you can create external tables and volumes on directories inside the external locations. You can then use Unity Catalog to manage user and group access to these tables and volumes. This allows you to provide specific users or groups access to specific directories and files in the cloud storage bucket.
Note
When you define an external volume, cloud URI access to data under the volume path is governed by the privileges granted on the volume, not the privileges granted on the external location where the volume is stored.
Recommendations for using external locations
Recommendations for granting permissions on external locations:
Grant the ability to create external locations only to an administrator who is tasked with setting up connections between Unity Catalog and cloud storage, or to trusted data engineers.
External locations provide access from within Unity Catalog to a broadly encompassing location in cloud storage—for example, an entire bucket or container (gs://mybucket) or a broad subpath (gs://mybucket/alotofdata). The intention is that a cloud administrator can be involved in setting up a few external locations and then delegate the responsibility of managing those locations to a Databricks administrator in your organization. The Databricks administrator can then further organize the external location into areas with more granular permissions by registering external volumes or external tables at specific prefixes under the external location.
Because external locations are so encompassing, Databricks recommends giving the
CREATE EXTERNAL LOCATIONpermission only to an administrator who is tasked with setting up connections between Unity Catalog and cloud storage, or to trusted data engineers. To provide other users with more granular access, Databricks recommends registering external tables or volumes on top of external locations and granting users access to data using volumes or tables. Since tables and volumes are children of a catalog and schema, catalog or schema administrators have the ultimate control over access permissions.You can also control access to an external location by binding it to specific workspaces. See (Optional) Assign an external location to specific workspaces.
Don’t grant general
READ FILESorWRITE FILESpermissions on external locations to end users.With the availability of volumes, users shouldn’t use external locations for anything but creating tables, volumes, or managed locations. They should not use external locations for path-based access for data science or other non-tabular data use cases.
Volumes provide support for working with files using SQL commands, dbutils, Spark APIs, REST APIs, Terraform, and a user interface for browsing, uploading, and downloading files. Moreover, volumes offer a FUSE mount that is accessible on the local file system under
/Volumes/<catalog_name>/<schema_name>/<volume_name>/. The FUSE mount allows data scientists and ML engineers to access files as if they were in a local filesystem, as required by many machine learning or operating system libraries.If you must grant direct access to files in an external location (for exploring files in cloud storage before a user creates an external table or volume, for example), you can grant
READ FILES. Use cases for grantingWRITE FILESare rare.
You should use external locations to do the following:
Register external tables and volumes using the
CREATE EXTERNAL VOLUMEorCREATE TABLEcommands.Explore existing files in cloud storage before you create an external table or volume at a specific prefix. The
READ FILESprivilege is a precondition.Register a location as managed storage for catalogs and schemas instead of the metastore root bucket. The
CREATE MANAGED STORAGEprivilege is a precondition.
More recommendations for using external locations:
Avoid path overlap conflicts: never create external volumes or tables at the root of an external location.
If you do create external volumes or tables at the external location root, you can’t create any additional external volumes or tables on the external location. Instead, create external volumes or tables on a sub-directory inside the external location.
Recommendations for using external volumes
You should use external volumes to do the following:
Register landing areas for raw data produced by external systems to support its processing in the early stages of ETL pipelines and other data engineering activities.
Register staging locations for ingestion, for example, using Auto Loader,
COPY INTO, or CTAS (CREATE TABLE AS) statements.Provide file storage locations for data scientists, data analysts, and machine learning engineers to use as parts of their exploratory data analysis and other data science tasks, when managed volumes are not an option.
Give Databricks users access to arbitrary files produced and deposited in cloud storage by other systems, for example, large collections of unstructured data (such as image, audio, video, and PDF files) captured by surveillance systems or IoT devices, or library files (JARs and Python wheel files) exported from local dependency management systems or CI/CD pipelines.
Store operational data, such as logging or checkpointing files, when managed volumes are not an option.
More recommendations for using external volumes:
Databricks recommends that you create external volumes from one external location within one schema.
Tip
For ingestion use cases in which the data is copied to another location—for example using Auto Loader or COPY INTO—use external volumes. Use external tables when you want to query data in place as a table, with no copy involved.
Recommendations for using external tables
You should use external tables to support normal querying patterns on top of data stored in cloud storage, when creating managed tables is not an option.
More recommendations for using external tables:
Databricks recommends that you create external tables using one external location per schema.
Databricks strongly recommends against registering a table as an external table in more than one metastore due to the risk of consistency issues. For example, a change to the schema in one metastore will not register in the second metastore. Use Delta Sharing for sharing data between metastores. See Share data securely using Delta Sharing.
Configure access control
Each securable object in Unity Catalog has an owner. The principal that creates an object becomes its initial owner. An object’s owner has all privileges on the object, such as SELECT and MODIFY on a table, as well as the permission to grant privileges on the securable object to other principals. Owners can grant privileges on that object to other principals, including the MANAGE privilege, which delegates the ability to grant privileges on an object. The owner, metastore admins, and users with the MANAGE privilege can transfer ownership of a securable object to a group. Additionally, if the object is contained within a catalog (like a table or view), the catalog and schema owner can change the ownership of the object.
Securable objects in Unity Catalog are hierarchical and privileges are inherited downward. This means that granting a privilege on a catalog or schema automatically grants the privilege to all current and future objects within the catalog or schema. For more information, see Inheritance model.
In order to read data from a table or view a user must have the following privileges:
SELECTon the table or viewUSE SCHEMAon the schema that owns the tableUSE CATALOGon the catalog that owns the schema
USE CATALOG enables the grantee to traverse the catalog in order to access its child objects and USE SCHEMA enables the grantee to traverse the schema in order to access its child objects. For example, to select data from a table, users need to have the SELECT privilege on that table and the USE CATALOG privilege on its parent catalog, along with the USE SCHEMA privilege on its parent schema. Therefore, you can use this privilege to restrict access to sections of your data namespace to specific groups. A common scenario is to set up a schema per team where only that team has USE SCHEMA and CREATE on the schema. This means that any tables produced by team members can only be shared within the team.
You can secure access to a table using the following SQL syntax:
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
You can secure access to columns using a dynamic view in a secondary schema as shown in the following SQL syntax:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
id,
CASE WHEN is_account_group_member(< group_name >) THEN email ELSE 'REDACTED' END AS email,
country,
product,
total
FROM
< catalog_name >.< schema_name >.< table_name >;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
You can secure access to rows using a dynamic view in a secondary schema as shown in the following SQL syntax:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
*
FROM
< catalog_name >.< schema_name >.< table_name >
WHERE
CASE WHEN is_account_group_member(managers) THEN TRUE ELSE total <= 1000000 END;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
You can also grant users secure access to tables using row filters and columns masks. For more information, see Filter sensitive table data using row filters and column masks.
For more information on all privileges in Unity Catalog, see Manage privileges in Unity Catalog.
Manage compute configurations
Databricks recommends using compute policies to limit the ability to configure clusters based on a set of rules. Compute policies let you restrict access to only create clusters which are Unity Catalog-enabled. Using compute policies reduces available choices, which will greatly simplify the cluster creation process for users and ensure that they are able to access data seamlessly. Compute policies also enable you to control cost by limiting per cluster maximum cost.
To ensure the integrity of access controls and enforce strong isolation guarantees, Unity Catalog imposes security requirements on compute resources. For this reason, Unity Catalog introduces the concept of a cluster’s access mode. Unity Catalog is secure by default; if a cluster is not configured with an appropriate access mode, the cluster can’t access data in Unity Catalog. See Compute requirements.
Databricks recommends shared access mode for all workloads. Use single user access mode only if your required functionality is not supported by shared access mode. See Access modes.
The JSON below provides a policy definition for a cluster with the shared access mode:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9]*\\.x-scala.*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "USER_ISOLATION",
"hidden": true
}
}
The JSON below provides a policy definition for an automated job cluster with the Single User access mode:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9].*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "SINGLE_USER",
"hidden": true
},
"single_user_name": {
"type": "regex",
"pattern": ".*",
"hidden": true
}
}
Audit access
A complete data governance solution requires auditing access to data and providing alerting and monitoring capabilities. Unity Catalog captures an audit log of actions performed against the metastore and these logs are delivered as part of Databricks audit logs.
You can access your account’s audit logs using system tables. For more information on the audit log system table, see Audit log system table reference.
See Monitoring Your Databricks Data Intelligence Platform with Audit Logs for details on how to get complete visibility into critical events relating to your Databricks Data Intelligence Platform.