Databricks Runtime for Machine Learning
この記事では、Machine Learning の Databricks Runtime について説明し、それを使用するクラスタリングを作成する方法のガイダンスを提供します。
Databricks Runtime for Machine Learning とは
Databricks Runtime for Machine Learning (Databricks Runtime ML) は、最も一般的な ML および DL ライブラリを含む、事前に構築された機械学習とディープラーニング インフラストラクチャを使用してクラスターの作成を自動化します。
Databricks Runtime MLに含まれるライブラリ
Databricks Runtime ML には、さまざまな一般的な ML ライブラリが含まれています。 ライブラリはリリースごとに更新され、新機能と修正が含まれています。
Databricks では、サポートされているライブラリのサブセットを最上位ライブラリとして指定しています。 これらのライブラリの場合、Databricks は更新頻度を高速化し、ランタイム リリースごとに最新のパッケージ リリースに更新します (依存関係の競合を除く)。 Databricks は、最上位のライブラリに対する高度なサポート、テスト、および組み込み最適化も提供します。 最上位ライブラリは、メジャーリリースでのみ追加または削除されます。
最上位のライブラリとその他の提供されているライブラリの完全なリストについては、 の リリースノート Databricks RuntimeMLを参照してください。
追加のライブラリをインストールすることで、ノートブックやクラスター用のカスタム環境を構築できます。
クラスターで実行されているすべてのノートブックでライブラリを使用できるようにするには、 クラスター ライブラリを作成します。 また、initスクリプトを使用して、作成時にクラスターにライブラリをインストールすることもできます。
特定のノートブックセッションでのみ使用できるライブラリをインストールするには、ノートブックスコープのPythonライブラリを使用します。
コンピュート リソースの設定 for Databricks Runtime ML
Databricks Runtime MLに基づいてコンピュートを作成するプロセスは、ワークスペースが Dedicated グループ クラスタリング パブリック プレビューに対して有効になっているかどうかによって異なります。プレビューが有効になっているワークスペースには、新しい 簡略化されたコンピュート UI があります。
Databricks Runtime MLを使用したクラスターの作成
クラスターを作成するときは、 [Databricks ランタイム バージョン ] ドロップダウン メニューから Databricks Runtime ML バージョンを選択します。 CPU と GPU 対応の両方の ML ランタイムが利用可能です。
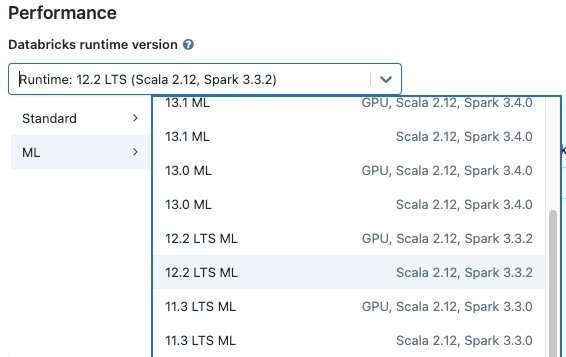
ノートブックの ドロップダウン メニューからクラスターを選択すると、クラスター名の右側に Databricks Runtime バージョンが表示されます。
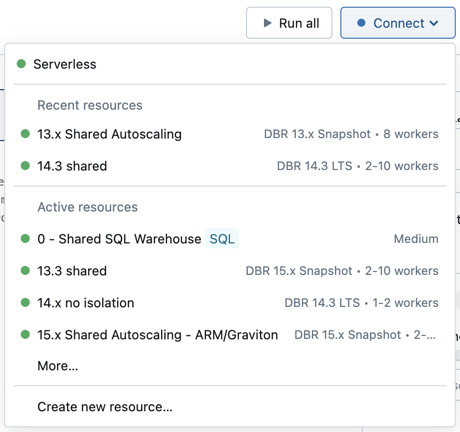
GPU 対応 ML ランタイムを選択した場合は、互換性のある [ドライバー タイプ ] と [ワーカー タイプ] を選択するように求められます。 互換性のないインスタンスタイプは、ドロップダウンメニューでグレー表示されます。 GPU 対応インスタンスタイプは、 GPU アクセラレーション ラベルの下に一覧表示されます。 GPU クラスターの作成に関する情報 Databricks 、「 GPU 対応コンピュート」を参照してください。 Databricks Runtime ML には、GPU ハードウェア ドライバーと CUDA などの NVIDIA ライブラリが含まれています。
新しいシンプルなコンピュートUIで新しいクラスタリングを作成
このセクションの手順は、ワークスペースが Dedicated グループ クラスタリング プレビューに対して有効になっている 場合にのみ 使用してください。
Databricks Runtime の機械学習バージョンを使用するには、 [ 機械学習 ] チェック ボックスをオンにします。
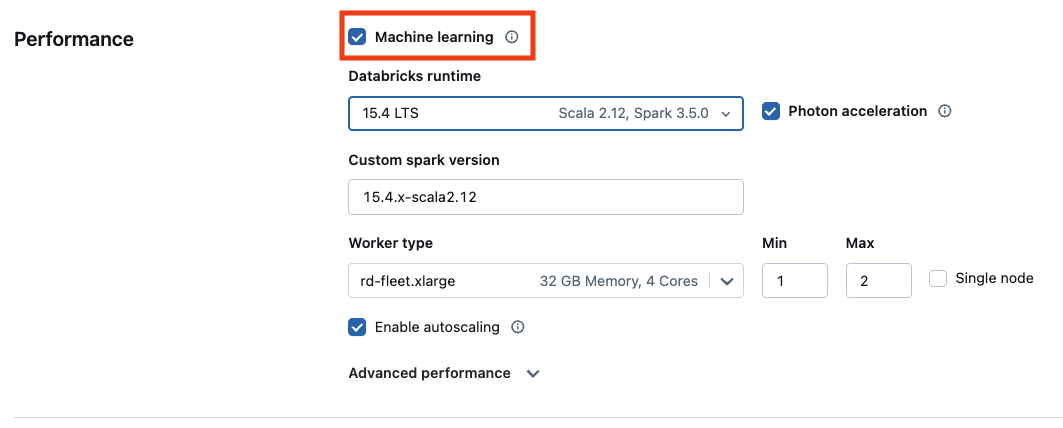
GPU ベースのコンピュートの場合は、GPU 対応のインスタンスタイプを選択します。 サポートされている GPU タイプの完全なリストについては、「 サポートされているインスタンスタイプ」を参照してください。
Photon と Databricks Runtime ML
Databricks Runtime 15.2 ML 以降を実行する CPU クラスターを作成する場合は、 Photon を有効にすることを選択できます。 Photon 、 Spark SQL、 Spark DataFrames、Feature エンジニアリング、 GraphFrames、および xgboost4j を使用するアプリケーションのパフォーマンスが向上します。 Spark RDD、Pandas UDF、および Python などの非 JVM 言語を使用するアプリケーションのパフォーマンスが向上することは期待されていません。 したがって、XGBoost、PyTorch、TensorFlowなどのPythonパッケージでは、Photonによる改善は見られません。
Spark RDD APIs と Spark MLlib は Photonとの互換性が限られています。Spark RDD または Spark MLlib を使用して大規模なデータセットを処理すると、Spark メモリの問題が発生する可能性があります。 Spark メモリの問題を参照してください。
Databricks Runtime ML クラスタリングのアクセスモード
Unity Catalogクラスタリング実行中の でDatabricks RuntimeML のデータにアクセスするには、次のいずれかを実行する必要があります。
シングル ユーザー アクセス モードを使用してクラスタリングを設定します。
専用アクセスモードを使用してクラスタリングを設定します。専用アクセス モードは現在パブリック プレビュー段階です。 専用アクセス モードは、Databricks Runtime ML の共有アクセス モードの機能を提供します。
コンピュート リソースに Dedicated アクセス権がある場合、リソースは 1 人のユーザーまたは 1 つのグループに割り当てることができます。 グループ (グループ クラスタリング) に割り当てると、ユーザーのアクセス許可は自動的にグループのアクセス許可にスコープが縮小され、ユーザーはグループの他のメンバーとリソースを安全に共有できます。