Databricks Runtime para aprendizado de máquina
Este artigo descreve o site Databricks Runtime for Machine Learning e fornece orientações sobre como criar um clustering que o utilize.
O que é o Databricks Runtime for Machine Learning?
Databricks Runtime para aprendizado de máquina (Databricks Runtime ML) automatiza a criação de um clustering com aprendizado de máquina pré-construído e infraestrutura profunda de aprendizagem, incluindo a biblioteca ML e DL mais comum.
biblioteca incluída em Databricks Runtime ML
Databricks Runtime ML inclui uma variedade de ML biblioteca populares. A biblioteca é atualizada a cada versão para incluir novos recursos e correções.
Databricks designou um subconjunto das bibliotecas apoiadas como biblioteca de primeira linha. Para essas bibliotecas, o site Databricks oferece uma cadência de atualização mais rápida, atualizando para as versões mais recentes do pacote a cada versão de tempo de execução (salvo conflitos de dependência). Databricks também oferece suporte avançado, testes e otimizações incorporadas para bibliotecas de primeira linha. As bibliotecas de primeira linha são adicionadas ou removidas apenas com as principais versões.
Para obter uma lista completa das bibliotecas de primeira linha e outras fornecidas, consulte as notas sobre a versão para Databricks Runtime ML.
Para obter informações sobre a frequência com que as bibliotecas são atualizadas e quando são obsoletas, consulte Databricks Runtime ML maintenance policy.
Você pode instalar bibliotecas adicionais para criar um ambiente personalizado para o seu notebook ou cluster.
Para tornar uma biblioteca disponível para todos os notebooks em execução em um cluster, crie uma biblioteca cluster . O senhor também pode usar um init script para instalar o biblioteca em clusters após a criação.
Para instalar uma biblioteca que está disponível apenas para uma sessão do notebook específica, use bibliotecas Python com escopo para notebooks.
Configurar compute recurso para Databricks Runtime ML
O processo de criação do site compute com base no site Databricks Runtime ML depende do fato de o site workspace estar ou não habilitado para o Public Preview de clustering de grupo dedicado. que estão habilitados para a visualização têm uma nova interface de usuário simplificada em compute .
Criar um cluster usando o Databricks Runtime ML
Quando o senhor criar um cluster, selecione uma versão do Databricks Runtime ML no menu suspenso Versão do tempo de execução do Databricks. Estão disponíveis tempos de execução de ML habilitados para CPU e GPU.
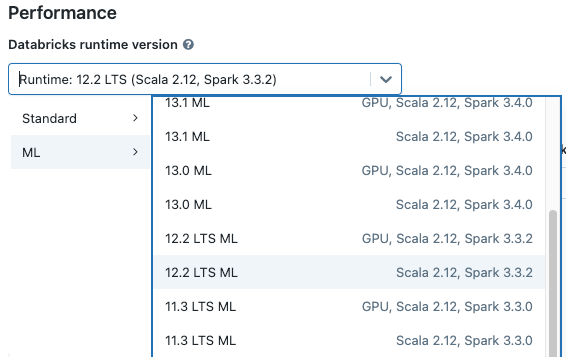
Se o senhor selecionar um cluster no menu suspenso do Notebook, a versão Databricks Runtime aparecerá à direita do nome cluster:
Se o senhor selecionar um tempo de execução ML habilitado para GPU, será solicitado a selecionar um tipo de driver e um tipo de trabalhador compatíveis. Os tipos de instância incompatíveis estão acinzentados no menu suspenso. Os tipos de instância habilitados para GPU são listados sob o rótulo GPU accelerated. Para obter informações sobre como criar Databricks GPU clusters, consulte GPU-enabled compute. Databricks Runtime ML Inclui drivers de hardware de GPU e biblioteca NVIDIA, como CUDA.
Crie um novo clustering com a nova UI simplificada do compute
Use as etapas desta seção somente se o site workspace estiver habilitado para a visualização de clustering de grupo dedicado.
Para usar a versão de aprendizado de máquina do Databricks Runtime, marque a caixa de seleção Aprendizado de máquina.
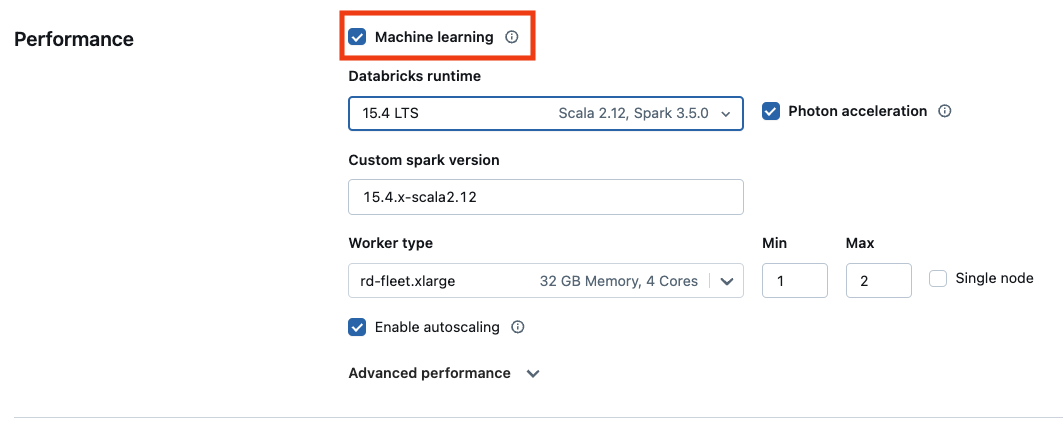
Para o site compute baseado em GPU, selecione um tipo de instância habilitado para GPU. Para ver a lista completa dos tipos de GPU compatíveis, consulte Tipos de instância compatíveis.
Photon e Databricks Runtime ML
Quando o senhor cria uma CPU cluster executando Databricks Runtime 15.2 ML ou acima, pode optar por ativar Photon. Photon melhora o desempenho de aplicativos que usam Spark SQL, Spark DataFrames, recurso engenharia, GraphFrames, e xgboost4j. Não se espera que melhore o desempenho dos aplicativos que usam Spark RDDs, Pandas UDFs e linguagens não JVM, como Python. Portanto, o pacote Python, como XGBoost, PyTorch e TensorFlow, não terá melhorias com o Photon.
As APIs do Spark RDD e o Spark MLlib têm compatibilidade limitada com o Photon. Ao processar grandes conjuntos de dados usando Spark RDD ou Spark MLlib, o senhor pode ter problemas de memória em Spark. Consulte Problemas de memória do Spark.
Modo de acesso para Databricks Runtime ML clustering
Para acessar os dados em Unity Catalog em um clustering que executa Databricks Runtime ML, o senhor deve executar uma das seguintes ações:
Configure o clustering usando o modo de acesso de usuário único.
Configure o clustering usando o modo de acesso Dedicated. O modo de acesso dedicado está atualmente em Pré-visualização Pública. O modo de acesso dedicado oferece o recurso do modo de acesso compartilhado em Databricks Runtime ML.
Quando um recurso compute tem acesso dedicado, o recurso pode ser atribuído a um único usuário ou a um grupo. Quando atribuídas a um grupo (um agrupamento de grupos), as permissões do usuário reduzem automaticamente o escopo para as permissões do grupo, permitindo que o usuário compartilhe o recurso com segurança com outros membros do grupo.