Run Git operations on Databricks Git folders (Repos)
The article describes how to perform common Git operations in your Databricks workspace using Git folders, including cloning, branching, committing, and pushing.
Clone a repo connected to a remote Git repository
In the sidebar, select Workspace and then browser to the folder where you want to create the Git repo clone.
Click the down arrow to the right of the Add in the upper right of the workspace, and select Git folder from the dropdown.
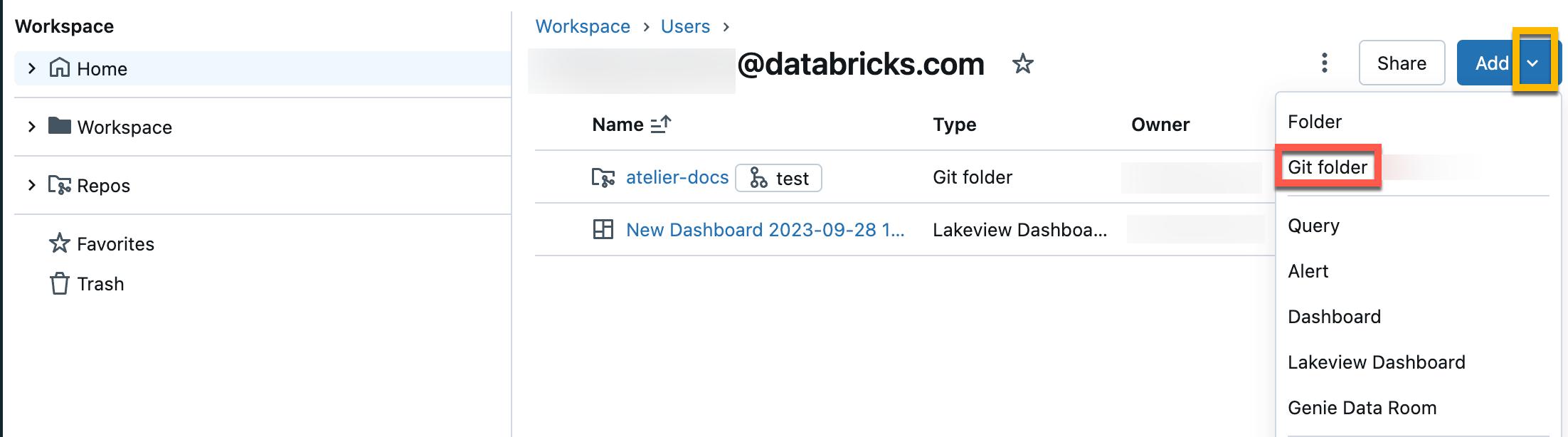
In the Create Git folder dialog, provide the following information:
The URL of the Git repository you want to clone, in the format
https://example.com/organization/project.gitThe Git provider for the repository you want to clone. Options include GitHub, GitHub Enterprise, GitLab, and Azure DevOps (Azure Repos)
The name of the folder in your workspace that will contain the contents of the cloned repo
Whether or not you will use sparse checkout, in which only a subset of your repository’s directories are cloned, specified using a cone pattern. This is useful if your repository is larger than Databricks supported limits.
Click Create Git folder. The contents of the remote repository are cloned to the Databricks repo, and you can begin working with them using supported Git operations through your workspace.
Best practice: Collaborating in Git folders
Databricks Git folders effectively behave as embedded Git clients in your workspace so users can collaborate using Git-based source control and versioning. To make team collaboration more effective, use a separate a Databricks Git folder mapped to a remote Git repo for each user who works in their own development branch . Although multiple users can contribute content to a Git folder, only one designated user should perform Git operations such as pull, push, commit, and branch switching. If multiple users perform Git operations on a Git folder, branch management can become difficult and error-prone, such as when a user switches a branch and unintentionally switches it for all other users of that folder.
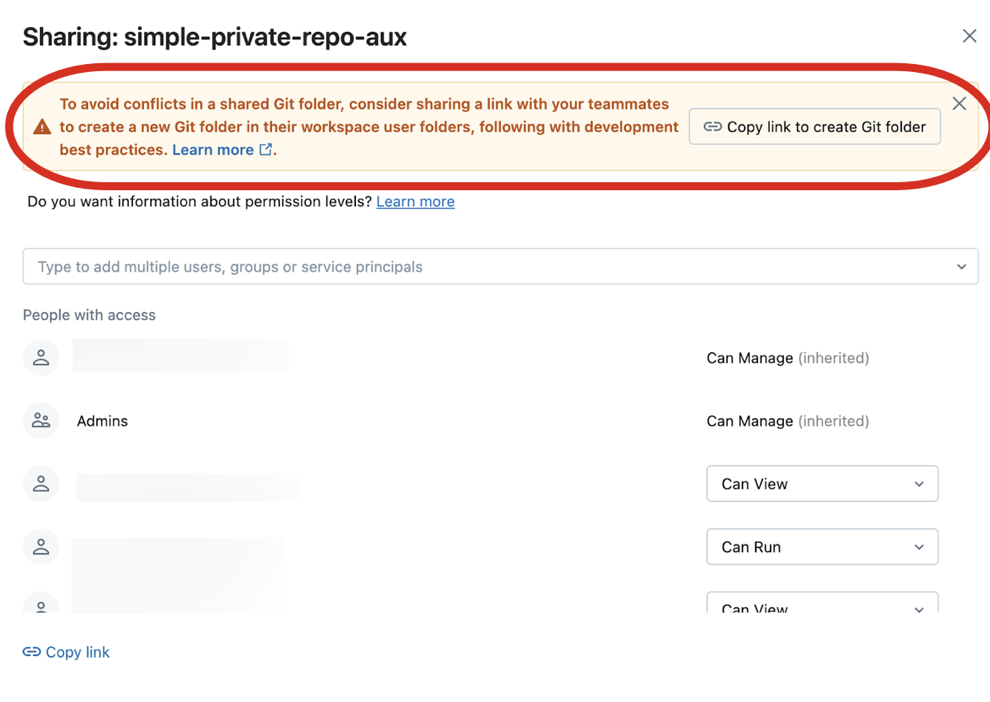
To share a Git folder with a collaborator, click Copy link to create Git folder in the banner at the top of your Databricks workspace. This action copies a URL to your local clipboard which you can send to another user. When the recipient user loads that URL in a browser they will be taken to the workspace where they can create their own Git folder cloned from the same remote Git repository. They will see a Create Git folder modal dialog in the UI, pre-populated with the values taken from your own Git folder. When they click the blue Create Git folder button in the modal, the Git repository is cloned into the workspace under their current working folder, where they can now work with it directly.
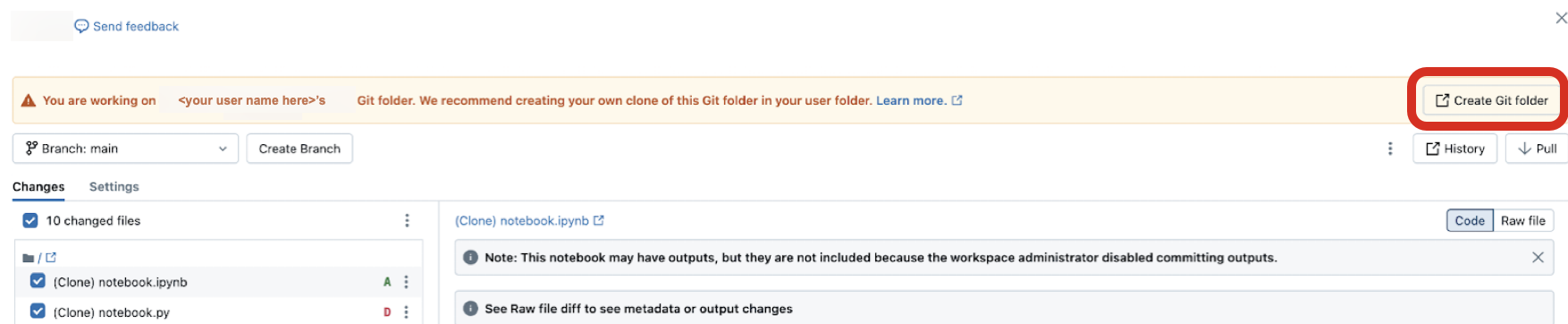
When accessing someone else’s Git folder in a shared workspace, click Create Git folder in the banner at the top. This action opens the Create Git folder dialog for you, pre-populated with the configuration for the Git repository that backs it.
Important
Currently you cannot use the Git CLI to perform Git operations in a Git folder. If you clone a Git repo using the CLI through a cluster’s web terminal, the files won’t display in the Databricks UI.
Access the Git dialog
You can access the Git dialog from a notebook or from the Databricks Git folders browser.
From a notebook, click the button next to the name of the notebook that identifies the current Git branch.

From the Databricks Git folders browser, click the button to the right of the repo name. You can also right-click the repo name and select Git… from the menu.
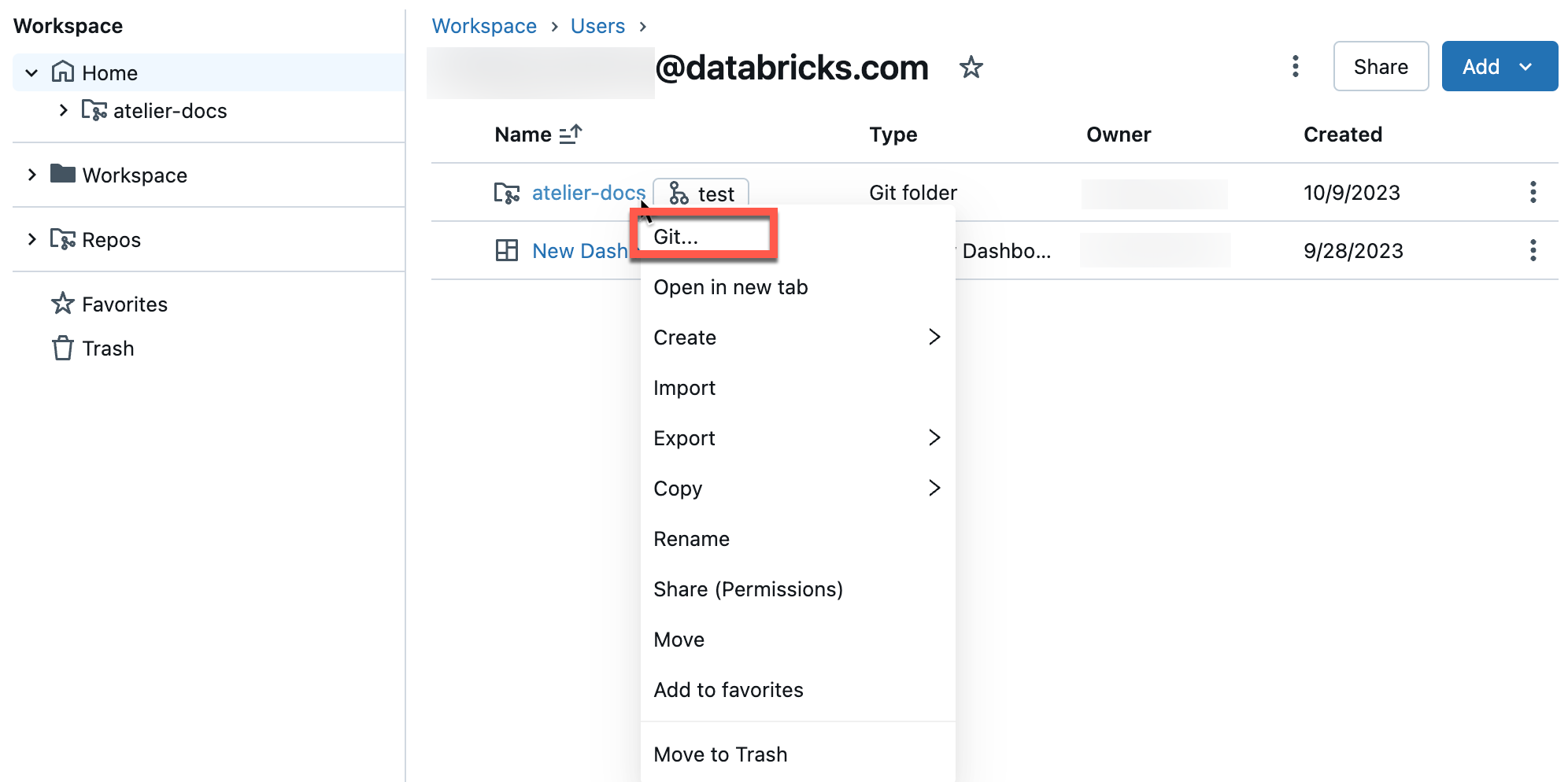
You will see a full-screen dialog where you can perform Git operations.
Your current working branch. You can select other branches here. If other users have access to this Git folder, changing the branch will also change the branch for them if they share the same workspace. See a recommended best practice to avoid this problem.
The button to create a new branch.
The list of file assets and subfolders checked into your current branch.
A button that takes you to your Git provider and shows you the current branch history.
The button to pull content from the remote Git repository.
Text box where you add a commit message and optional expanded description for your changes.
The button to commit your work to the working branch and push the updated branch to the remote Git repository.
Click the  kebab in the upper right to choose from additional Git branch operations, such as a hard reset, a merge, or a rebase.
kebab in the upper right to choose from additional Git branch operations, such as a hard reset, a merge, or a rebase.

This is your home for performing Git operations on your workspace Git folder. You are limited to the Git operations presented in the user interface.
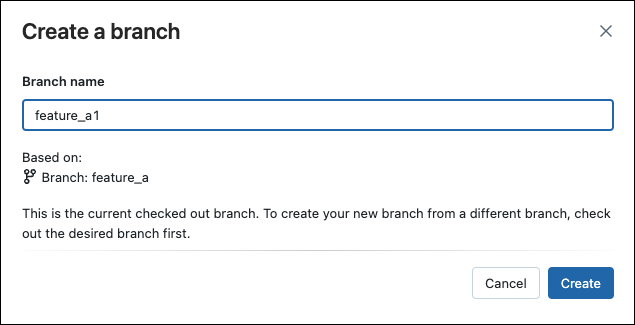
Switch to a different branch
You can switch to (checkout) a different branch using the branch dropdown in the Git dialog:
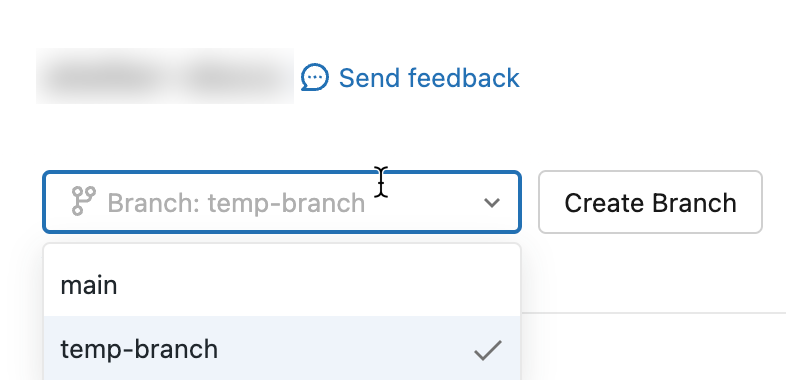
Important
After you checkout a branch in a Git folder, there is always a chance the branch may be deleted on the remote Git repository by someone else. If a branch is deleted on the remote repo, the local version can remain present in the associated Git folder for up to 7 days. Local branches in Databricks cannot be deleted, so if you must remove them, you must also delete and reclone the repository.
Commit and push changes to the remote Git repository
When you have added new notebooks or files, or made changes to existing notebooks or files, the Git folder UI highlights the changes.
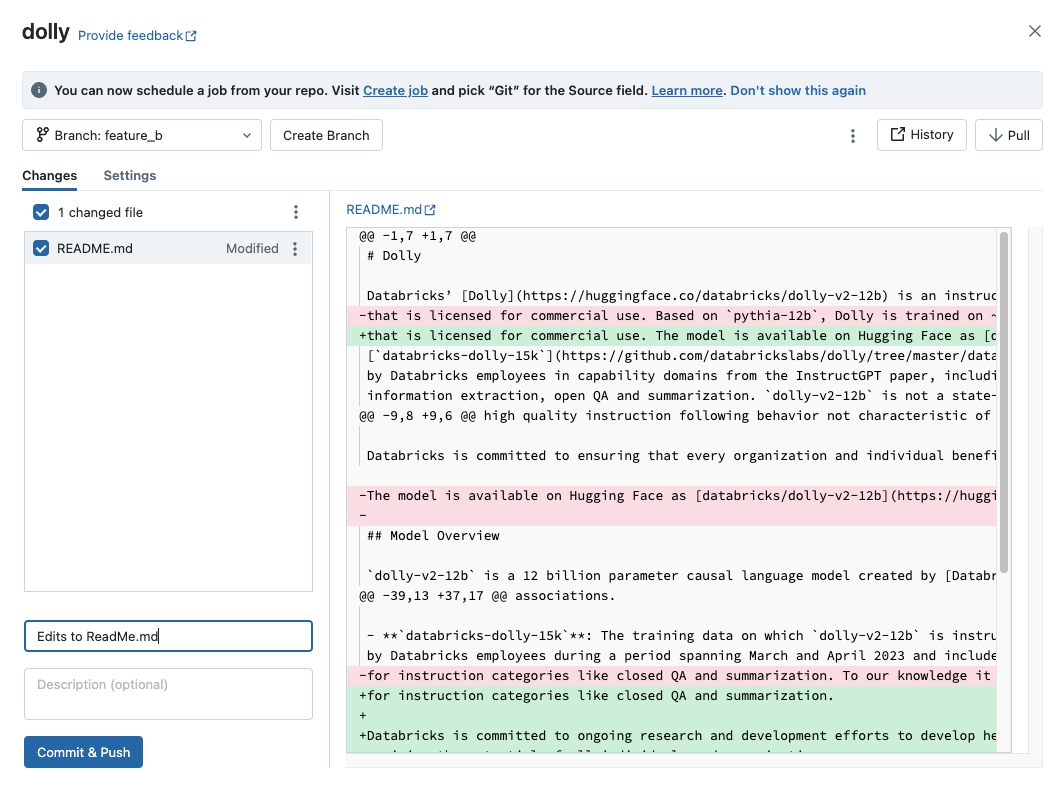
Add a required commit message for the changes, and click Commit & Push to push these changes to the remote Git repository.
If you don’t have permission to commit to the default branch (such as the main branch), create a new branch and use your Git provider’s interface to create a pull request (PR) to merge it into the default branch.
Note
Notebook outputs are not included in commits by default when notebooks are saved in source file formats (
.py,.scala,.sql,.r). For information on committing notebook outputs using the IPYNB format, see Control IPYNB notebook output artifact commits
Pull changes from the remote Git repository
To pull changes from the remote Git repository, click Pull in the Git operations dialog. Notebooks and other files are updated automatically to the latest version in your remote Git repository. If the changes pulled from the remote repo conflict with your local changes in Databricks, you need to resolve the merge conflicts.
Important
Git operations that pull in upstream changes clear the notebook state. For more information, see Incoming changes clear the notebook state.
Merge branches
Access the Git Merge operation by selecting it from the kebab in the upper right of the Git operations dialog.
The merge function in Databricks Git folders merges one branch into another using git merge. A merge operation is a way to combine the commit history from one branch into another branch; the only difference is the strategy it uses to achieve this. For Git beginners, we recommend using merge (over rebase) because it does not require force pushing to a branch and therefore does not rewrite commit history.
If there’s a merge conflict, resolve it in the Git folders UI.
If there’s no conflict, the merge is pushed to the remote Git repo using
git push.
Rebase a branch on another branch
Access the Git Rebase operation by selecting it from the kebab menu in the upper right of the Git operations dialog.
Rebasing alters the commit history of a branch. Like git merge, git rebase integrates changes from one branch into another. Rebase does the following:
Saves the commits on your current branch to a temporary area.
Resets the current branch to the chosen branch.
Reapplies each individual commit previously saved on the current branch, resulting in a linear history that combines changes from both branches.
Warning
Using rebase can cause versioning issues for collaborators working in the same repo.
A common workflow is to rebase a feature branch on the main branch.
To rebase a branch on another branch:
From the Branch menu in the Git folders UI, select the branch you want to rebase.
Select Rebase from the kebab menu.

Select the branch you want to rebase on.
The rebase operation integrates changes from the branch you choose here into the current branch.
Databricks Git folders runs git commit and git push --force to update the remote Git repo.
Resolve merge conflicts
Merge conflicts happen when 2 or more Git users attempt to merge changes to the same lines of a file into a common branch and Git cannot choose the “right” changes to apply. Merge conflicts can also occur when a user attempts to pull or merge changes from another branch into a branch with uncommitted changes.
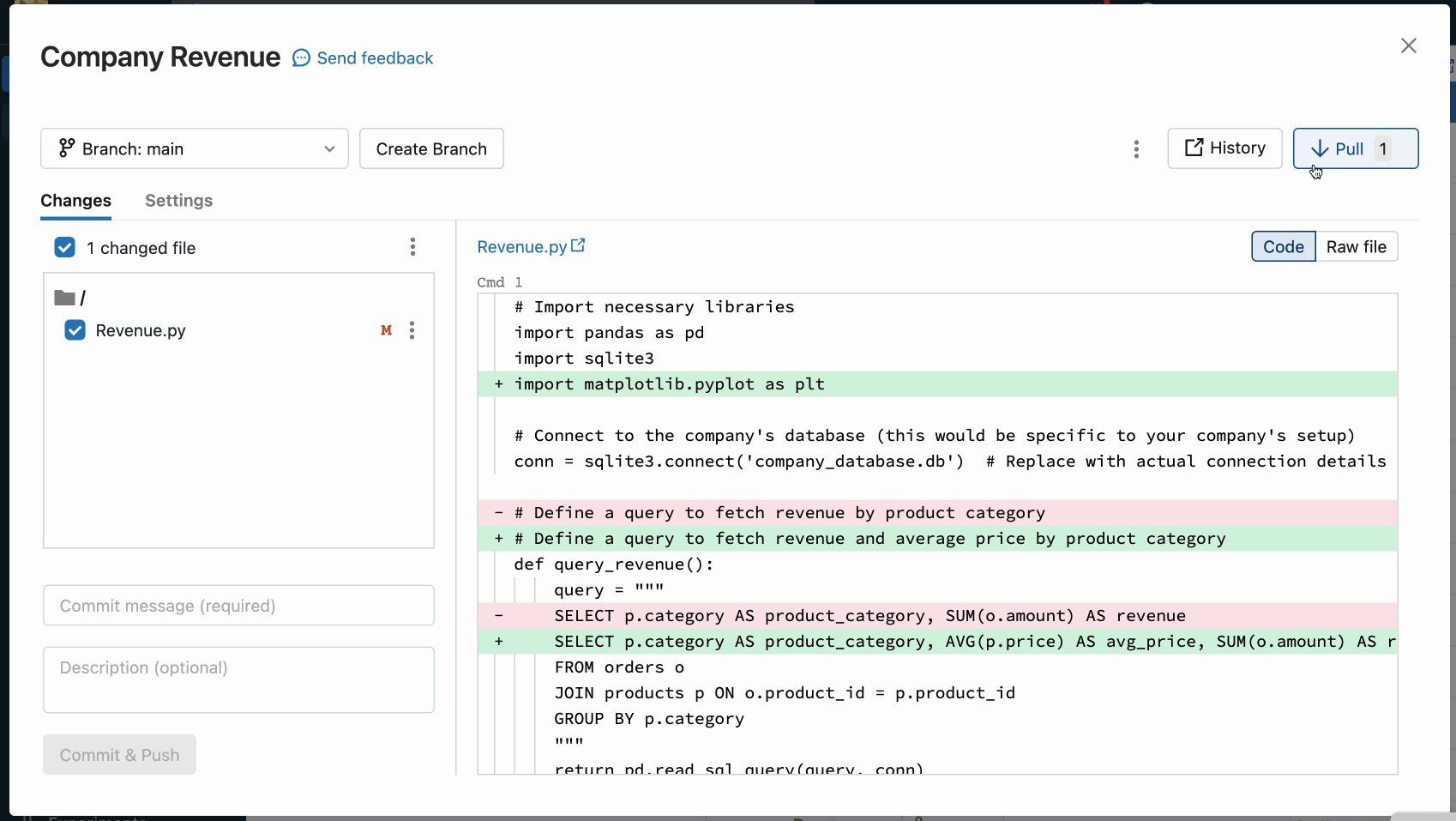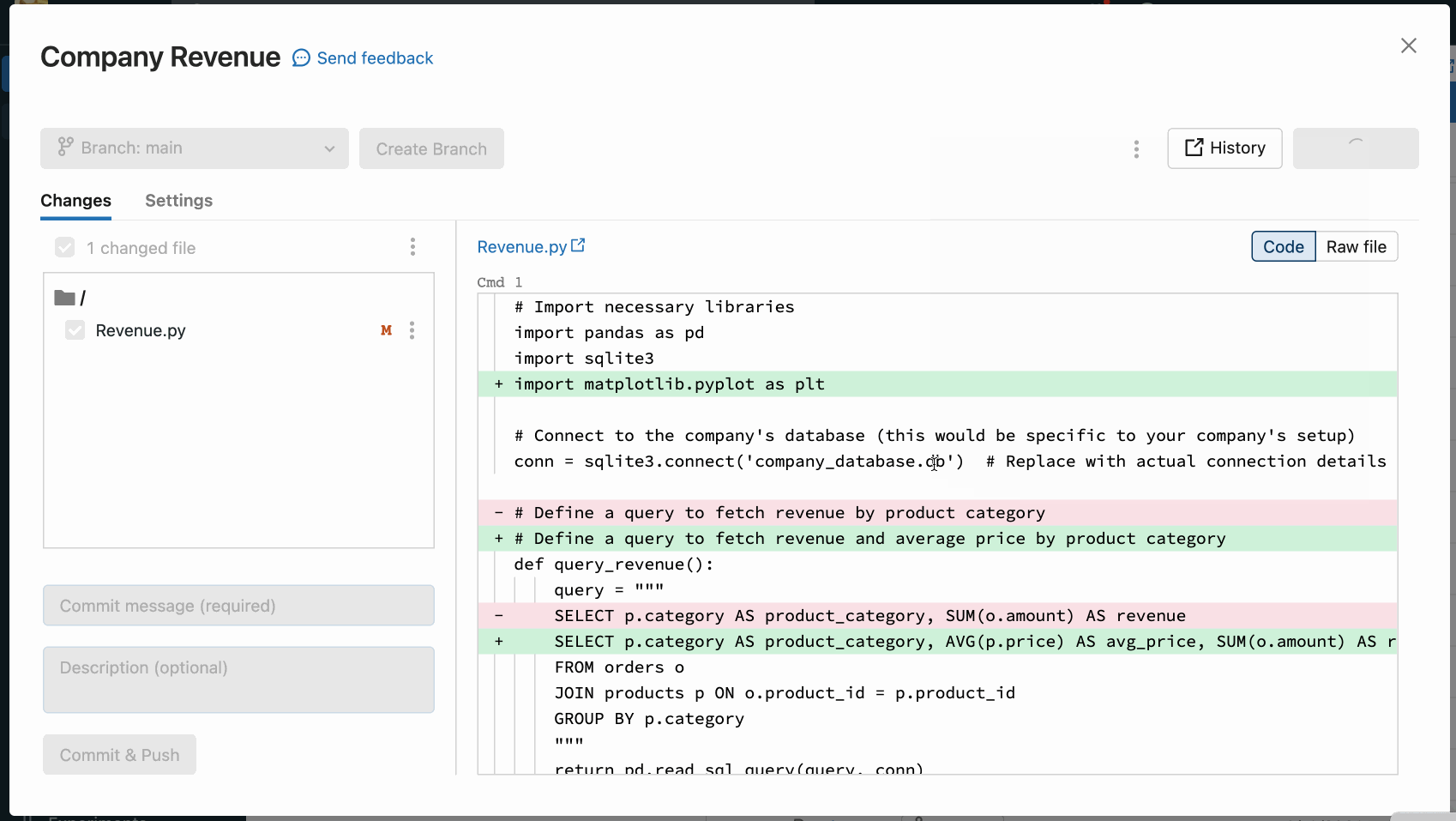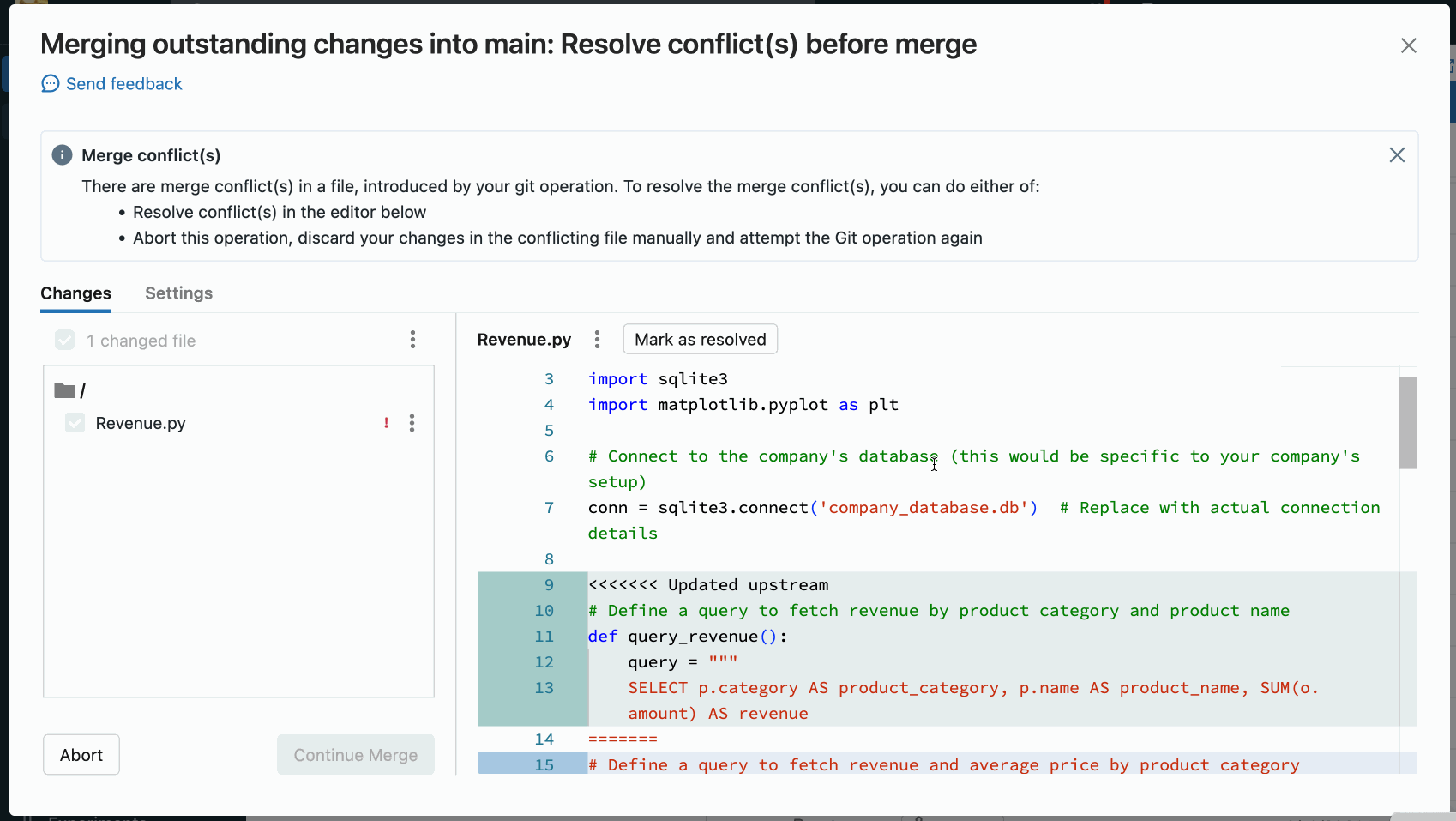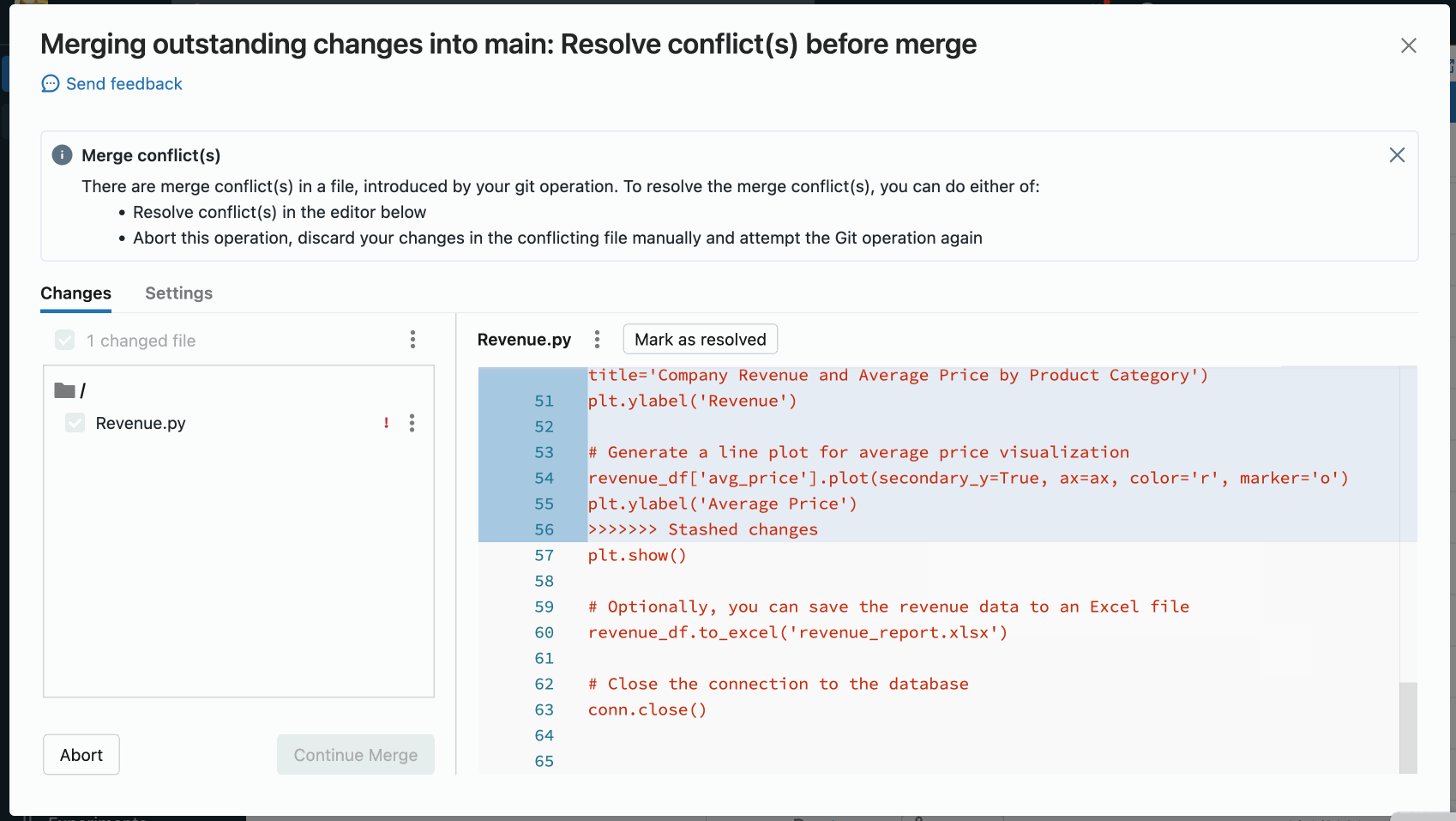
If an operation such as pull, rebase, or merge causes a merge conflict, the Git folders UI shows a list of files with conflicts and options for resolving the conflicts.
You have two primary options:
Use the Git folders UI to resolve the conflict.
Abort the Git operation, manually discard the changes in the conflicting file, and try the Git operation again.
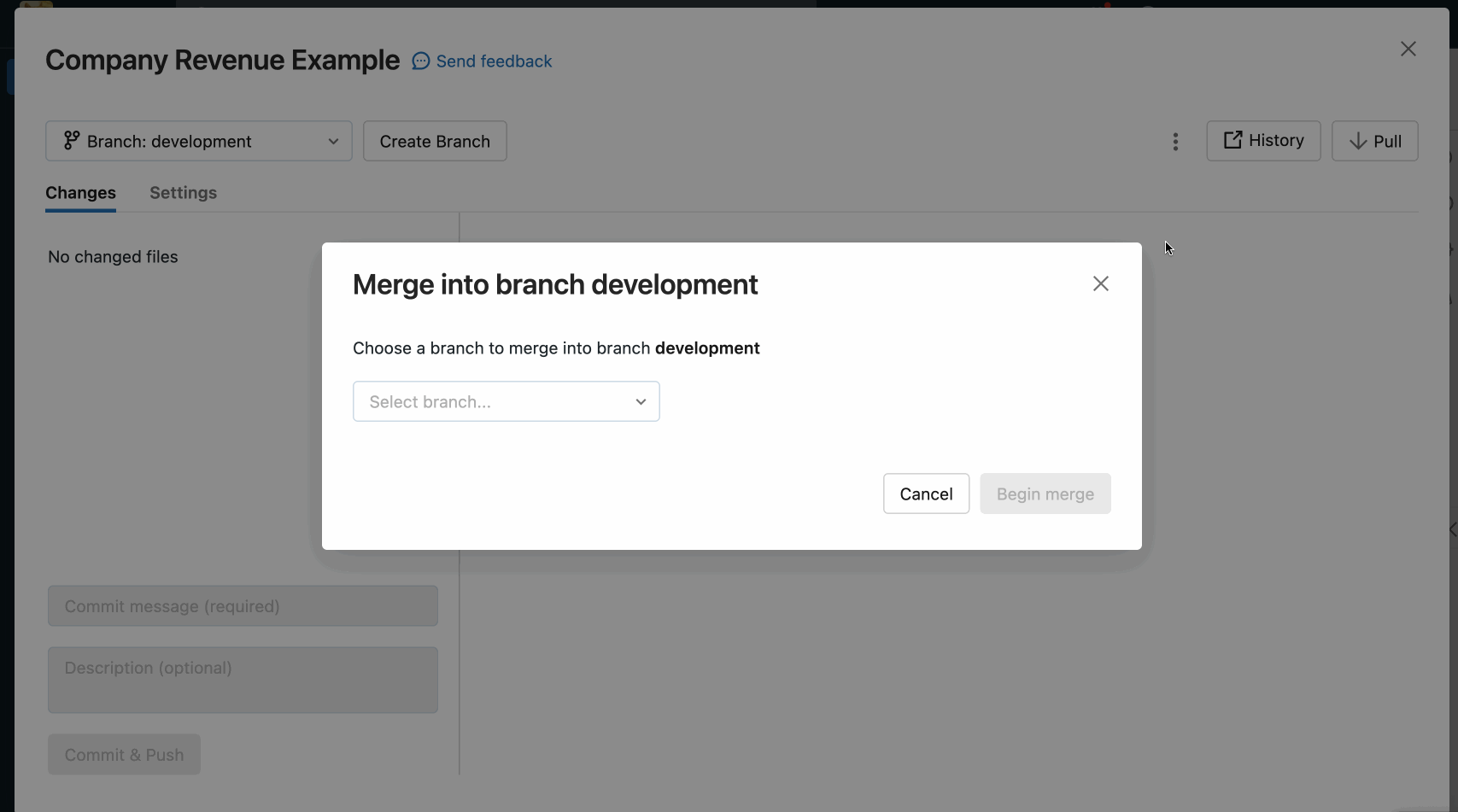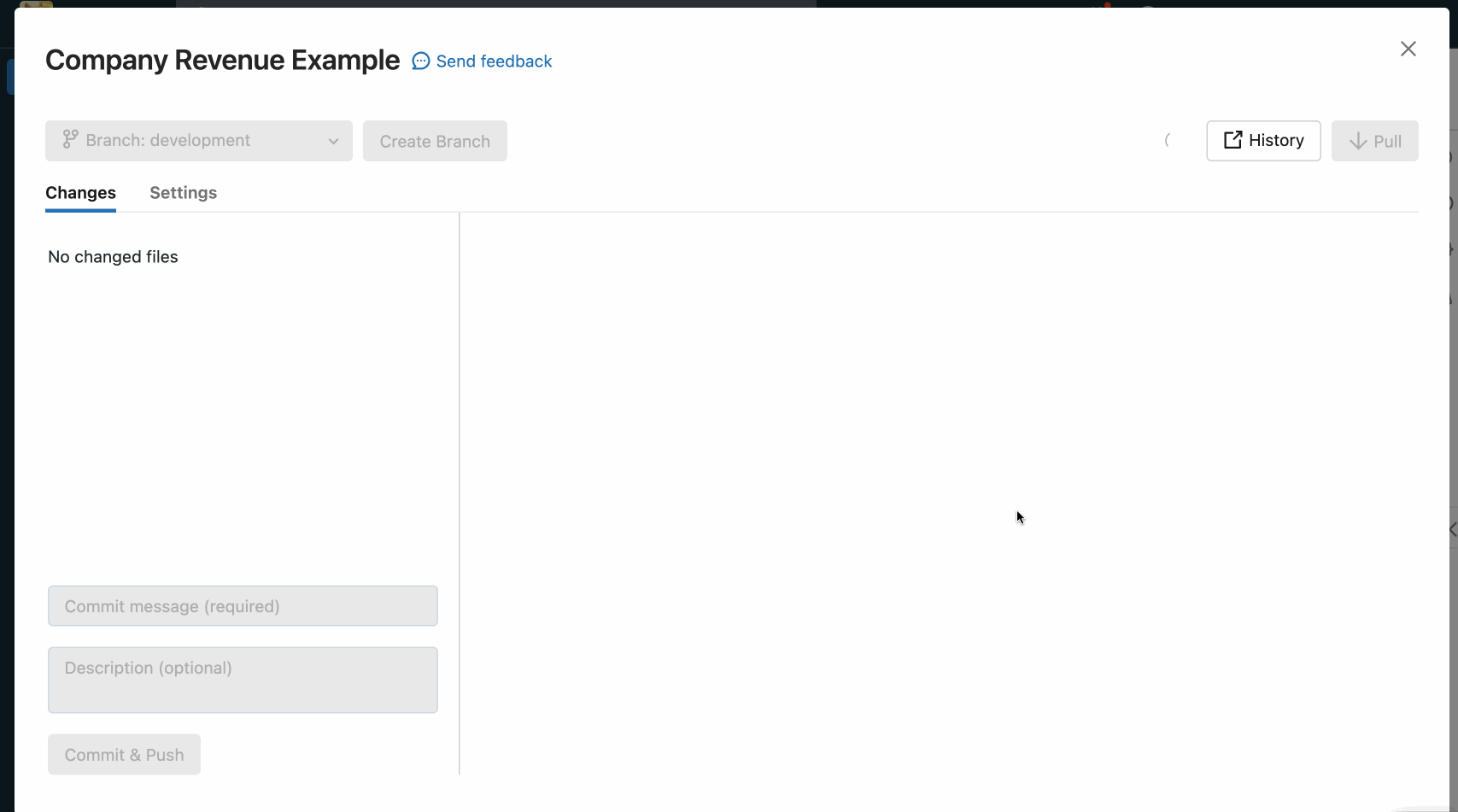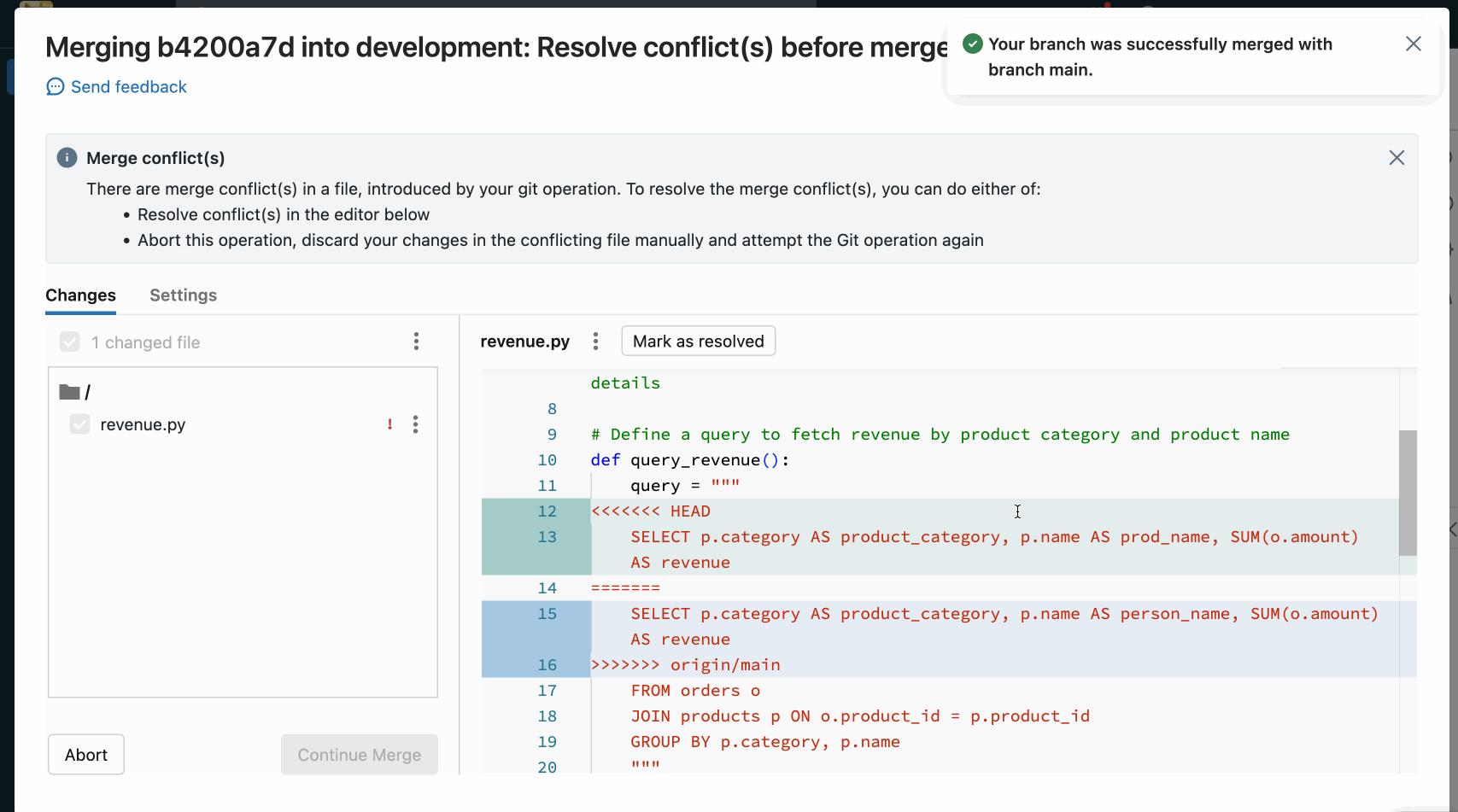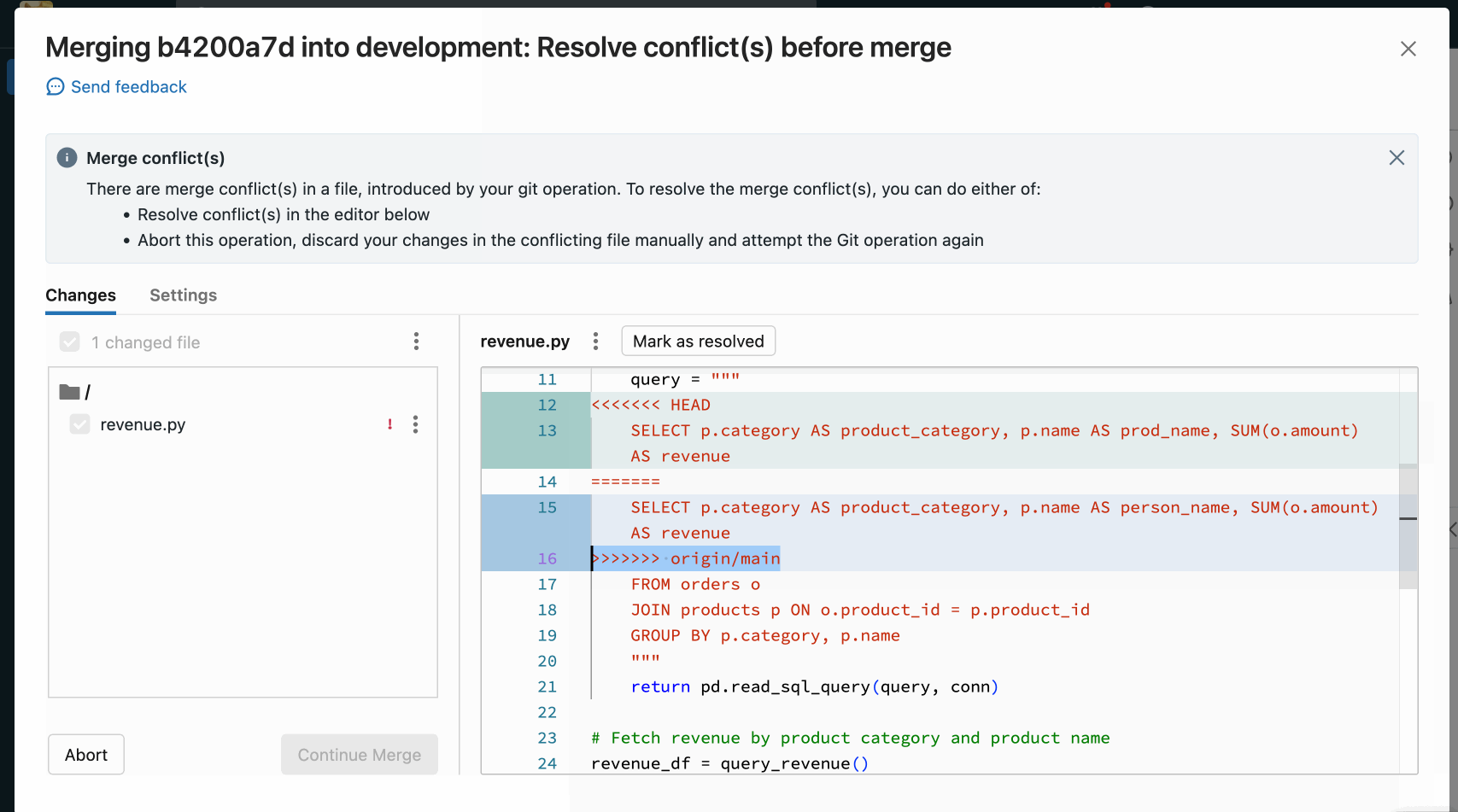
When resolving merge conflicts with the Git folders UI, you must choose between manually resolving the conflicts in the editor or keeping all incoming or current changes.
Keep All Current or Take Incoming Changes
If you know you only want to keep all of the current or incoming changes, click the kebab to the right of the file name in your notebook pane and select either Keep all current changes or Take all incoming changes. Click the button with the same label to commit the changes and resolve the conflict.
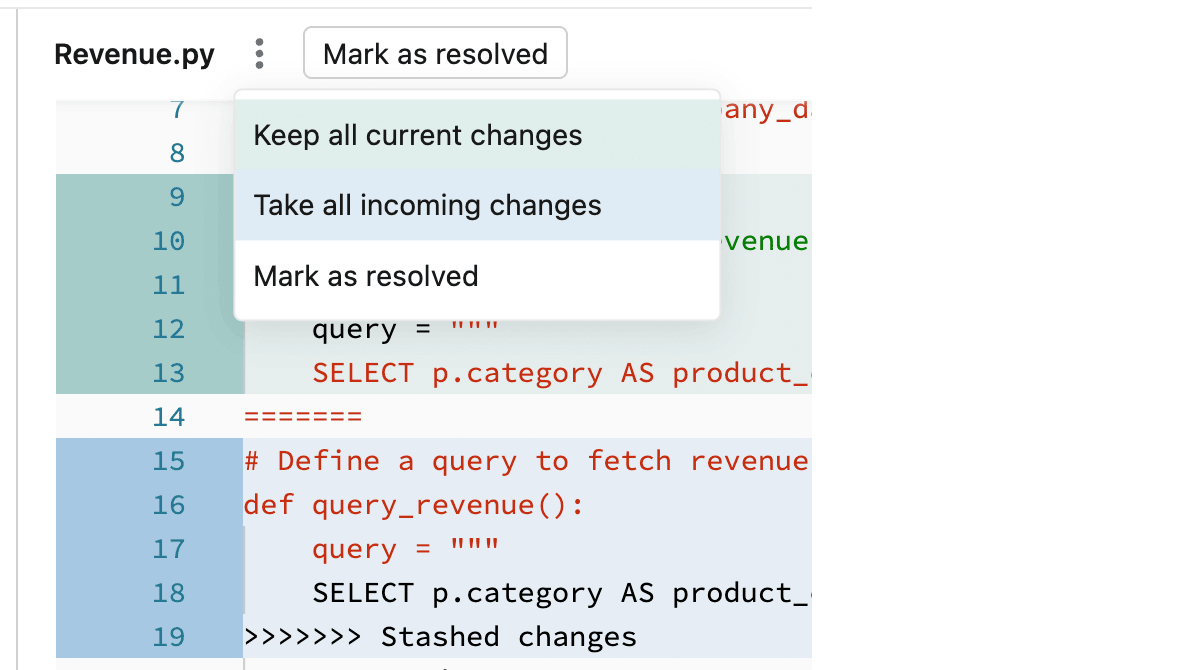
Tip
Confused about which option to pick? The color of each option matches the respective code changes that it will keep in the file.
Manually Resolving Conflicts
Manual conflict resolution lets you determine which of the conflicting lines should be accepted in the merge. For merge conflicts, you resolve the conflict by directly editing the contents of the file with the conflicts.
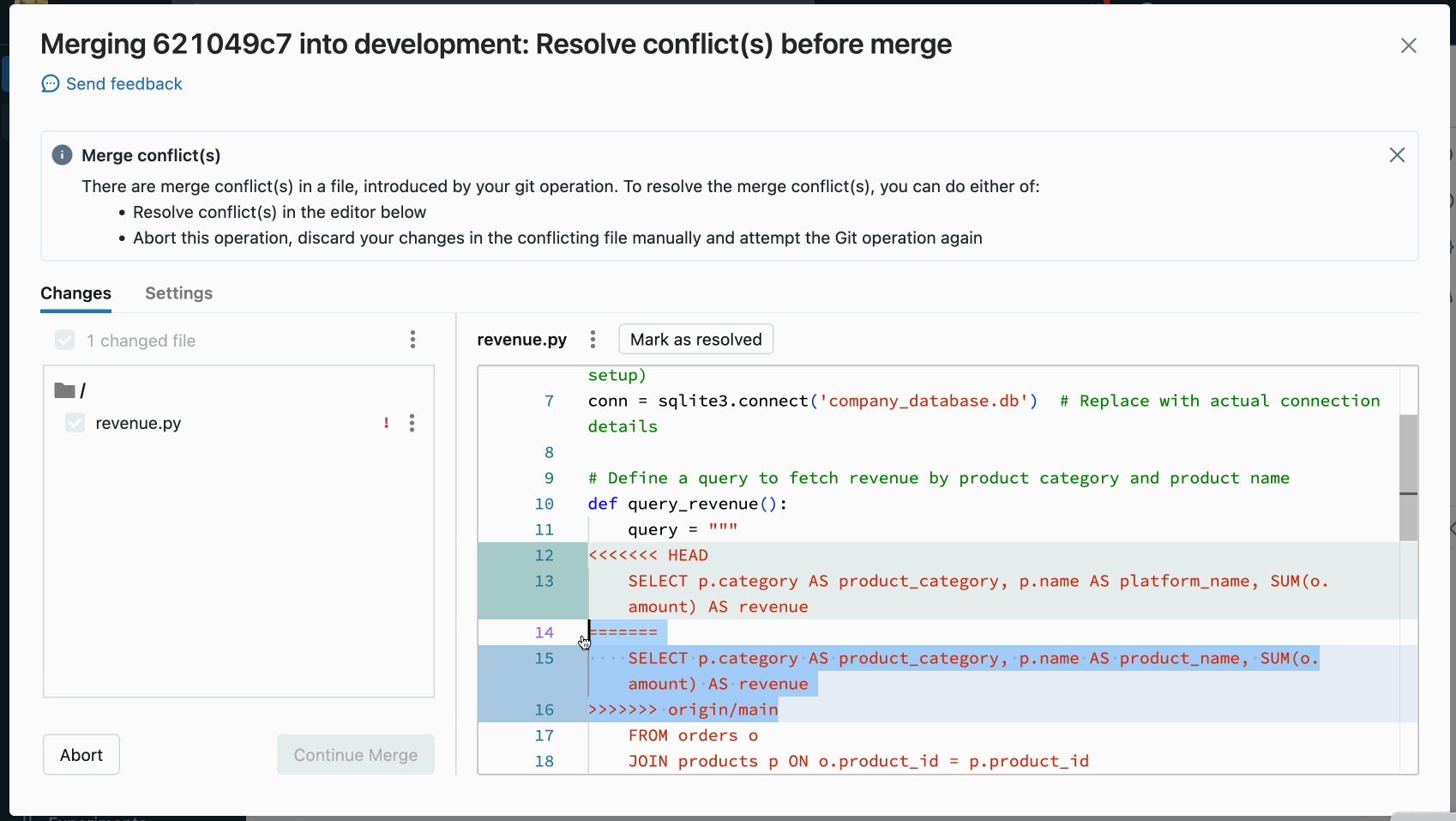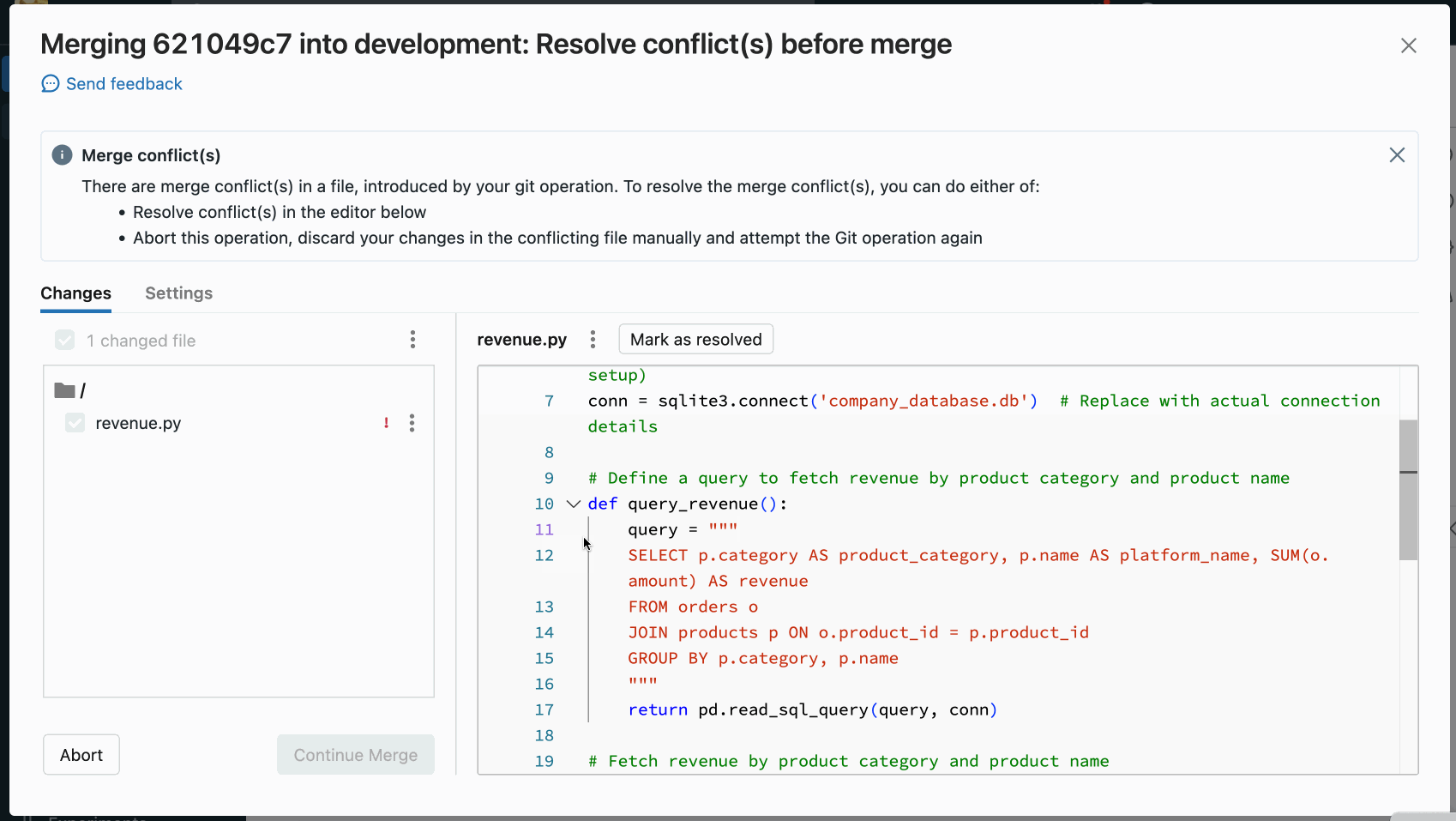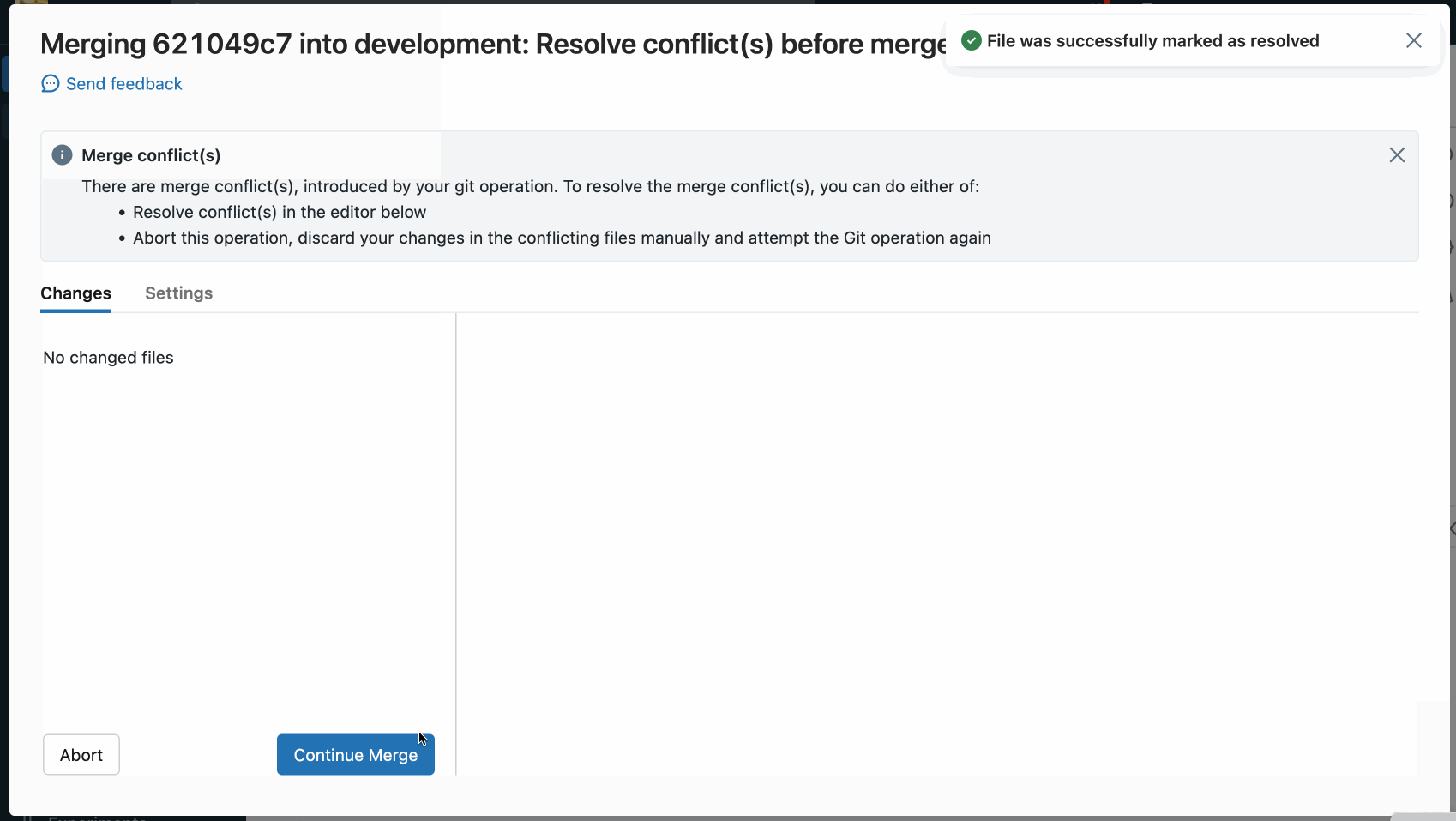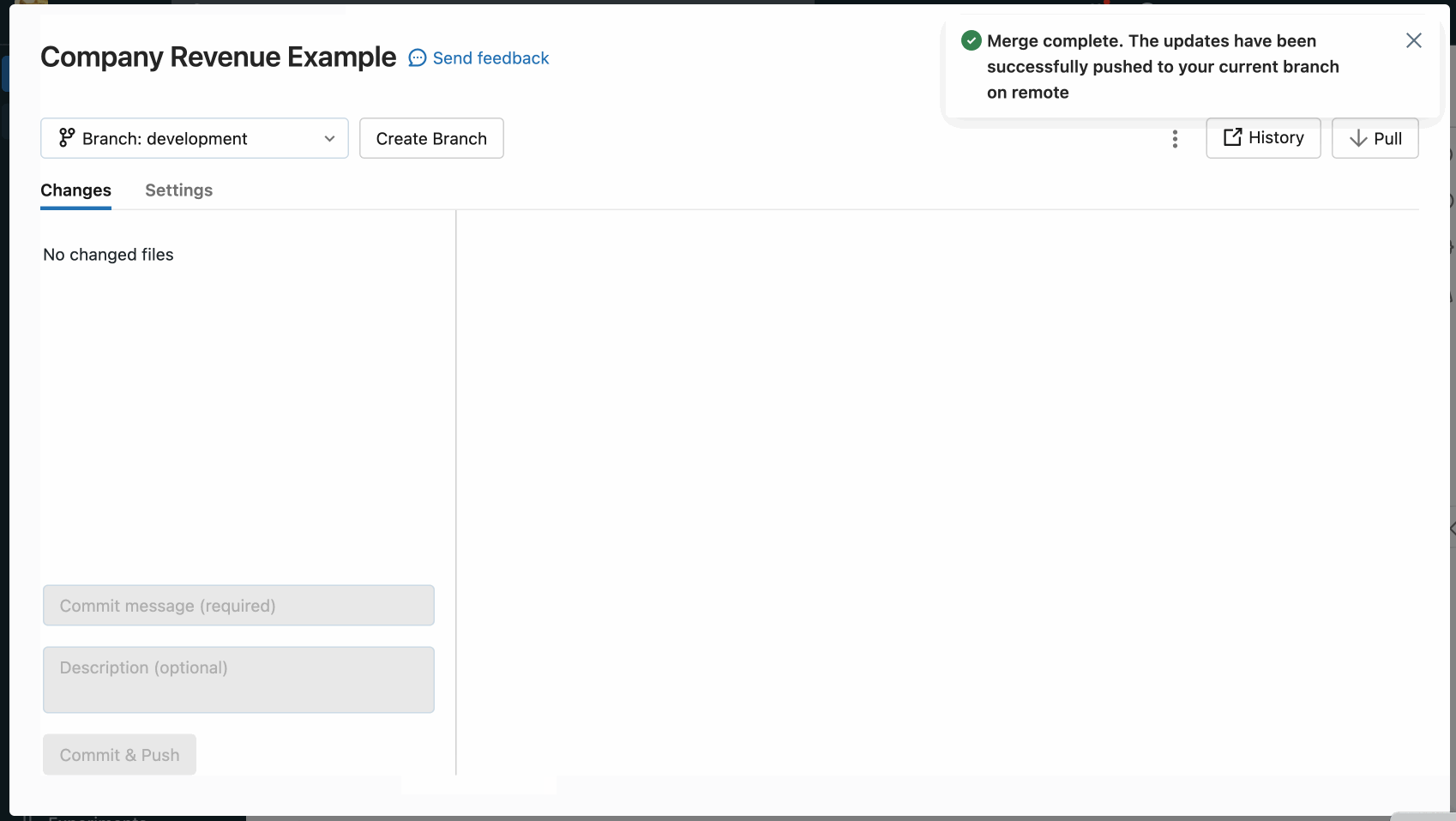
To resolve the conflict, select the code lines you want to preserve and delete everything else, including the Git merge conflict markers. When you’re done, select Mark As Resolved.
If you decide you made the wrong choices when resolving merge conflicts, click the Abort button to abort the process and undo everything. Once all conflicts are resolved, click the Continue Merge or Continue Rebase option to resolve the conflict and complete the operation.
Git reset
In Databricks Git folders, you can perform a Git reset within the Databricks UI. Git reset in Databricks Git folders is equivalent to git reset --hard combined with git push --force.
Git reset replaces the branch contents and history with the most recent state of another branch. You can use this when edits are in conflict with the upstream branch, and you don’t mind losing those edits when you reset to the upstream branch. Read more about git `reset –hard`.
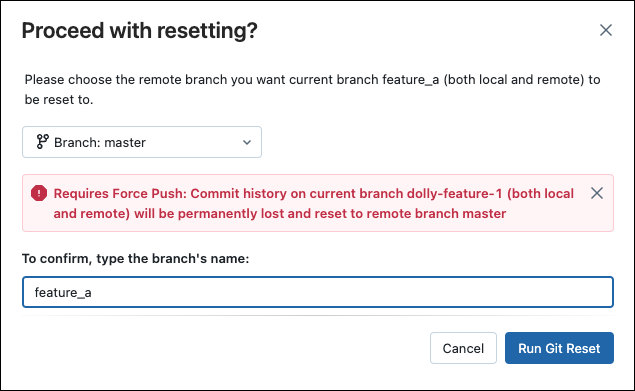
Reset to an upstream (remote) branch
With git reset in this scenario:
You reset your selected branch (for example,
feature_a) to a different branch (for example,main).You also reset the upstream (remote) branch
feature_ato main.
Important
When you reset, you lose all uncommitted and committed changes in both the local and remote version of the branch.
To reset a branch to a remote branch:
In the Git folders UI from the Branch menu, choose the branch you want to reset.
Select Reset from the kebab menu.

Select the branch to reset.
Configure sparse checkout mode
Sparse checkout is a client side setting which allows you to clone and work with only a subset of the remote repositories’s directories in Databricks. This is especially useful if your repository’s size is beyond the Databricks supported limits.
You can use the Sparse Checkout mode when adding (cloning) a new repo.
In the Add Git folder dialog, open Advanced.
Select Sparse checkout mode.
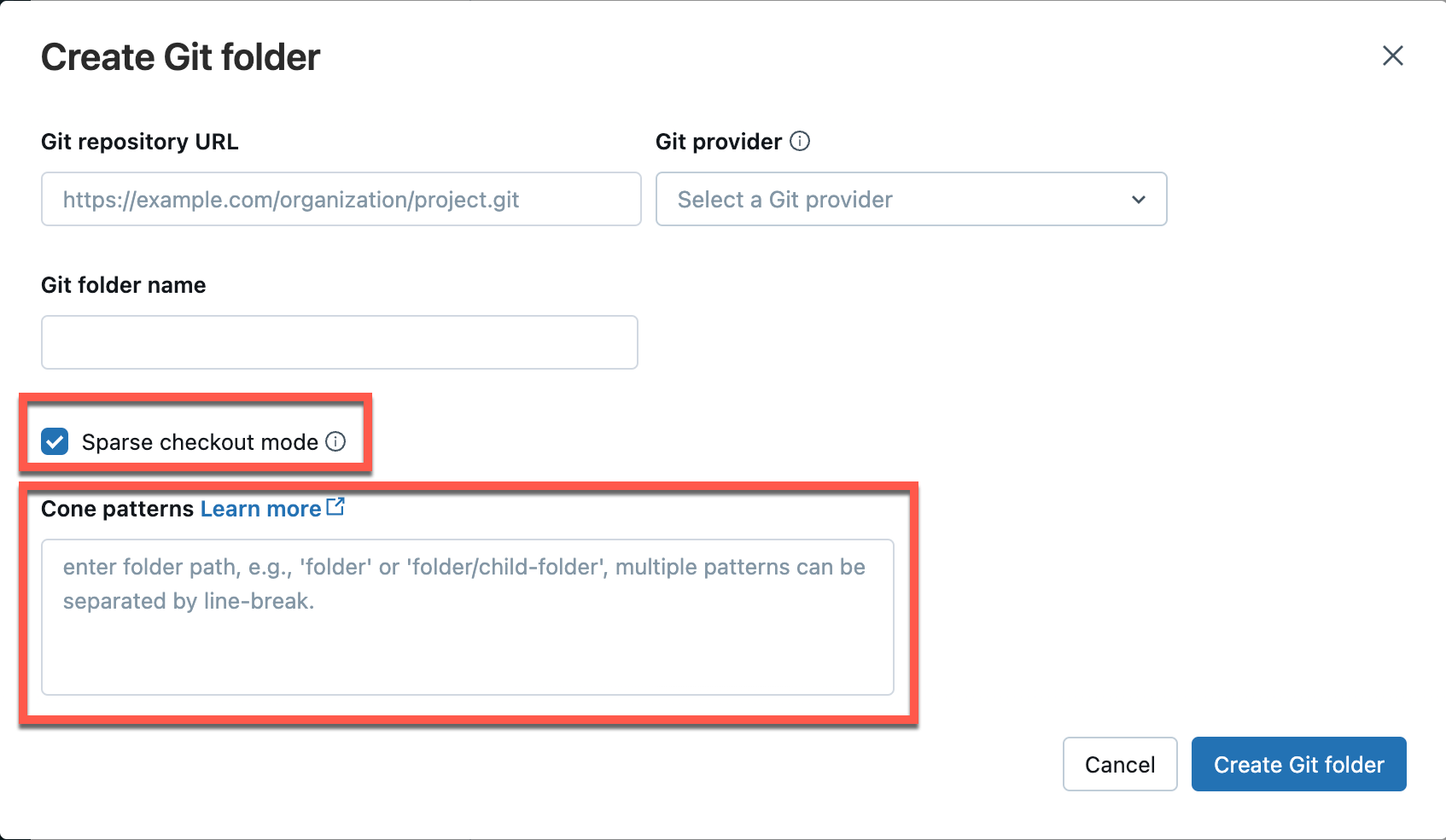
In the Cone patterns box, specify the cone checkout patterns you want. Separate multiple patterns by line breaks.
At this time, you can’t disable sparse checkout for a repo in Databricks.
How cone patterns work
To understand how cone pattern works in the sparse checkout mode, see the following diagram representing the remote repository structure.
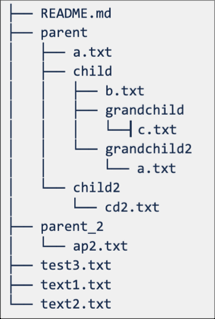
If you select Sparse checkout mode, but do not specify a cone pattern, the default cone pattern is applied. This includes only the files in root and no subdirectories, resulting in a repo structure as following:

Setting the sparse checkout cone pattern as parent/child/grandchild results in all contents of the grandchild directory being recursively included. The files immediately in the /parent, /parent/child and root directory are also included. See the directory structure in the following diagram:
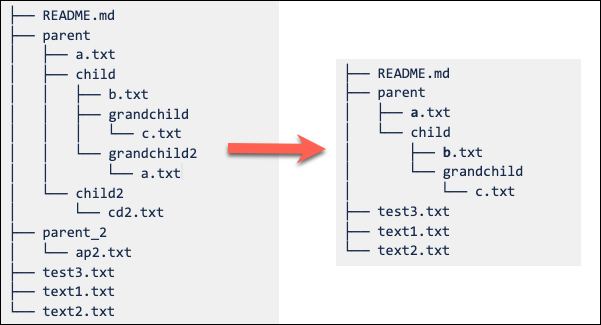
You can add multiple patterns separated by line breaks.
Note
Exclusion behaviors (!) are not supported in Git cone pattern syntax.
Modify sparse checkout settings
Once a repo is created, the sparse checkout cone pattern can be edited from Settings > Advanced > Cone patterns.
Note the following behavior:
Removing a folder from the cone pattern removes it from Databricks if there are no uncommitted changes.
Adding a folder via editing the sparse checkout cone pattern adds it to Databricks without requiring an additional pull.
Sparse checkout patterns cannot be changed to remove a folder when there are uncommitted changes in that folder.
For example, a user edits a file in a folder and does not commit changes. She then tries to change the sparse checkout pattern to not include this folder. In this case, the pattern is accepted, but the actual folder is not deleted. She needs to revert the pattern to include that folder, commit changes, and then reapply the new pattern.
Note
You can’t disable sparse checkout for a repo that was created with Sparse Checkout mode enabled.
Make and push changes with sparse checkout
You can edit existing files and commit and push them from the Git folder. When creating new folders of files, include them in the cone pattern you specified for that repo.
Including a new folder outside of the cone pattern results in an error during the commit and push operation. To fix it, edit the cone pattern to include the new folder you are trying to commit and push.
Patterns for a repo config file
The commit outputs config file uses patterns similar to gitignore patterns and does the following:
Positive patterns enable outputs inclusion for matching notebooks.
Negative patterns disable outputs inclusion for matching notebooks.
Patterns are evaluated in order for all notebooks.
Invalid paths or paths not resolving to
.ipynbnotebooks are ignored.
Positive pattern: To include outputs from a notebook path folder/innerfolder/notebook.ipynb, use following patterns:
**/*
folder/**
folder/innerfolder/note*
Negative pattern: To exclude outputs for a notebook, check that none of the positive patterns match or add a negative pattern in a correct spot of the configuration file. Negative (exclude) patterns start with !:
!folder/innerfolder/*.ipynb
!folder/**/*.ipynb
!**/notebook.ipynb
Add a repo and connect remotely later
To manage and work with Git folders programmatically, use the Git folders REST API.