Work with files on Databricks
Databricks has multiple utilities and APIs for interacting with files in the following locations:
Unity Catalog volumes
Workspace files
Cloud object storage
DBFS mounts and DBFS root
Ephemeral storage attached to the driver node of the cluster
This article has examples for interacting with files in these locations for the following tools:
Apache Spark
Spark SQL and Databricks SQL
Databricks file system utilities (
dbutils.fsor%fs)Databricks CLI
Databricks REST API
Bash shell commands (
%sh)Notebook-scoped library installs using
%pippandas
OSS Python file management and processing utilities
Important
File operations requiring FUSE data access cannot directly access cloud object storage using URIs. Databricks recommends using Unity Catalog volumes to configure access to these locations for FUSE.
Scala supports FUSE for Unity Catalog volumes and workspace files on compute configured with Unity Catalog and dedicated access mode (formerly shared access mode). On compute configured with dedicated access mode (formerly single user access mode) and Databricks Runtime 14.3 and above, Scala supports FUSE for Unity Catalog volumes and workspace files, except for subprocesses that originate from Scala, such as the Scala command "cat /Volumes/path/to/file".!!.
Spark and other JVM processes can only access Unity Catalog volumes or workspace files using the readers and writers that support Unity Catalog. For example, you cannot specify a JAR file as a dependency in a Spark configuration, and you cannot use PySpark custom data sources. If you have a JVM workload from libraries that need to access files in volumes or in workspace files, copy the files into compute local storage using Python or shell commands such as %sh mv.. Do not use %fs or dbutils.fs which uses the JVM. If a file needs to be present during cluster start, use an init script to move the file first. See What are init scripts?.
Do I need to provide a URI scheme to access data?
Data access paths in Databricks follow one of the following standards:
URI-style paths include a URI scheme. For Databricks-native data access solutions, URI schemes are optional for most use cases. When directly accessing data in cloud object storage, you must provide the correct URI scheme for the storage type.
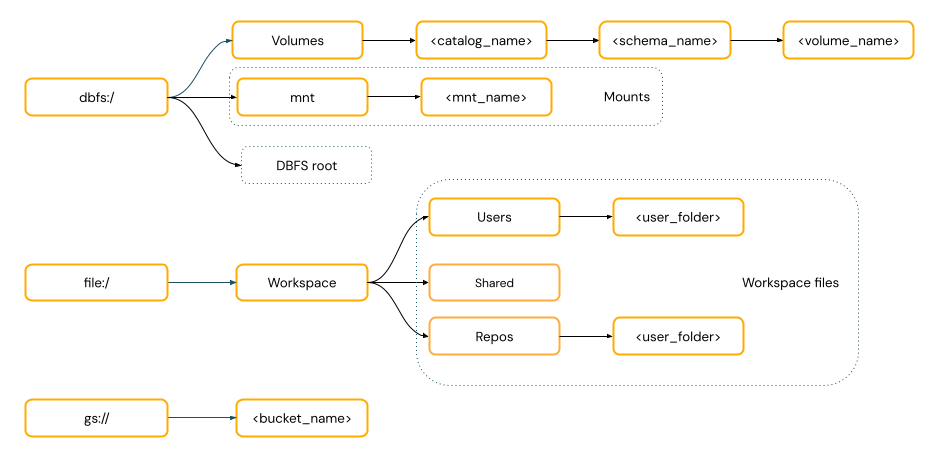
POSIX-style paths provide data access relative to the driver root (
/). POSIX-style paths never require a scheme. You can use Unity Catalog volumes or DBFS mounts to provide POSIX-style access to data in cloud object storage. Many ML frameworks and other OSS Python modules require FUSE and can only use POSIX-style paths.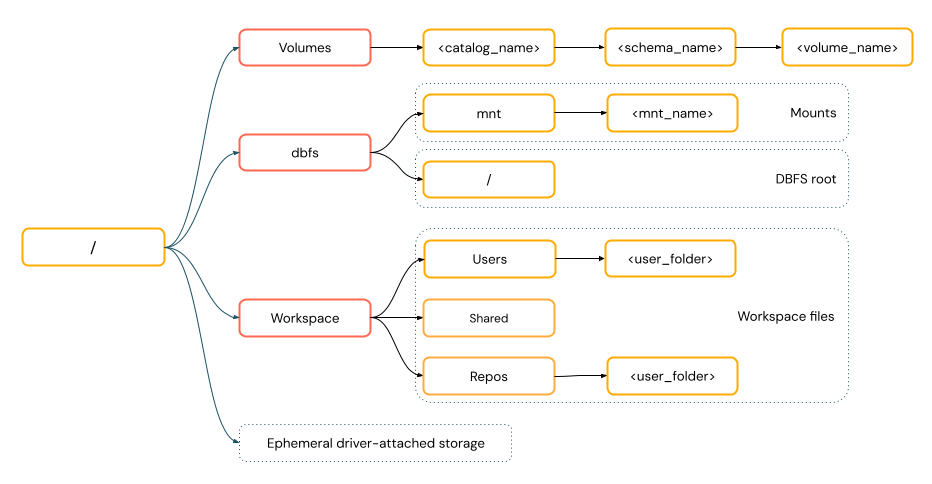
Work with files in Unity Catalog volumes
Databricks recommends using Unity Catalog volumes to configure access to non-tabular data files stored in cloud object storage. See What are Unity Catalog volumes?.
Tool |
Example |
|---|---|
Apache Spark |
|
Spark SQL and Databricks SQL |
|
Databricks file system utilities |
|
Databricks CLI |
|
Databricks REST API |
|
Bash shell commands |
|
Library installs |
|
Pandas |
|
OSS Python |
|
Note
The dbfs:/ scheme is required when working with the Databricks CLI.
Volumes limitations
Volumes have the following limitations:
Direct-append or non-sequential (random) writes, such as writing Zip and Excel files are not supported. For direct-append or random-write workloads, perform the operations on a local disk first and then copy the results to Unity Catalog volumes. For example:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')
Sparse files are not supported. To copy sparse files, use
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
Work with workspace files
Databricks workspace files are the files in a workspace, stored in the workspace storage account. You can use workspace files to store and access files such as notebooks, source code files, data files, and other workspace assets. Because workspace files have size restrictions, Databricks recommends only storing small data files here primarily for development and testing.
Tool |
Example |
|---|---|
Apache Spark |
|
Spark SQL and Databricks SQL |
|
Databricks file system utilities |
|
Databricks CLI |
|
Databricks REST API |
|
Bash shell commands |
|
Library installs |
|
Pandas |
|
OSS Python |
|
Note
The file:/ schema is required when working with Databricks Utilities, Apache Spark, or SQL.
For the limitations in working with workspace files, see Limitations.
Where do deleted workspace files go?
Deleting a workspace file sends it to the trash. You can recover or permanently delete files from the trash using the UI.
See Delete an object.
Work with files in cloud object storage
Databricks recommends using Unity Catalog volumes to configure secure access to files in cloud object storage. You must configure permissions if you choose to directly access data in cloud object storage using URIs. See Manage external locations, external tables, and external volumes.
The following examples use URIs to access data in cloud object storage:
Tool |
Example |
|---|---|
Apache Spark |
|
Spark SQL and Databricks SQL |
|
Databricks file system utilities |
|
Databricks CLI |
Not supported |
Databricks REST API |
Not supported |
Bash shell commands |
Not supported |
Library installs |
|
Pandas |
Not supported |
OSS Python |
Not supported |
Work with files in DBFS mounts and DBFS root
DBFS mounts are not securable using Unity Catalog and are no longer recommended by Databricks. Data stored in the DBFS root is accessible by all users in the workspace. Databricks recommends against storing any sensitive or production code or data in the DBFS root. See What is DBFS?.
Tool |
Example |
|---|---|
Apache Spark |
|
Spark SQL and Databricks SQL |
|
Databricks file system utilities |
|
Databricks CLI |
|
Databricks REST API |
|
Bash shell commands |
|
Library installs |
|
Pandas |
|
OSS Python |
|
Note
The dbfs:/ scheme is required when working with the Databricks CLI.
Work with files in ephemeral storage attached to the driver node
The ephemeral storage attached to the driver node is block storage with built-in POSIX-based path access. Any data stored in this location disappears when a cluster terminates or restarts.
Tool |
Example |
|---|---|
Apache Spark |
Not supported |
Spark SQL and Databricks SQL |
Not supported |
Databricks file system utilities |
|
Databricks CLI |
Not supported |
Databricks REST API |
Not supported |
Bash shell commands |
|
Library installs |
Not supported |
Pandas |
|
OSS Python |
|
Note
The file:/ schema is required when working with Databricks Utilities.
Move data from ephemeral storage to volumes
You might want to access data downloaded or saved to ephemeral storage using Apache Spark. Because ephemeral storage is attached to the driver and Spark is a distributed processing engine, not all operations can directly access data here. Suppose you must move data from the driver filesystem to Unity Catalog volumes. In that case, you can copy files using magic commands or the Databricks utilities, as in the following examples:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
Additional resources
For information about uploading local files or downloading internet files to Databricks, see Upload files to Databricks.