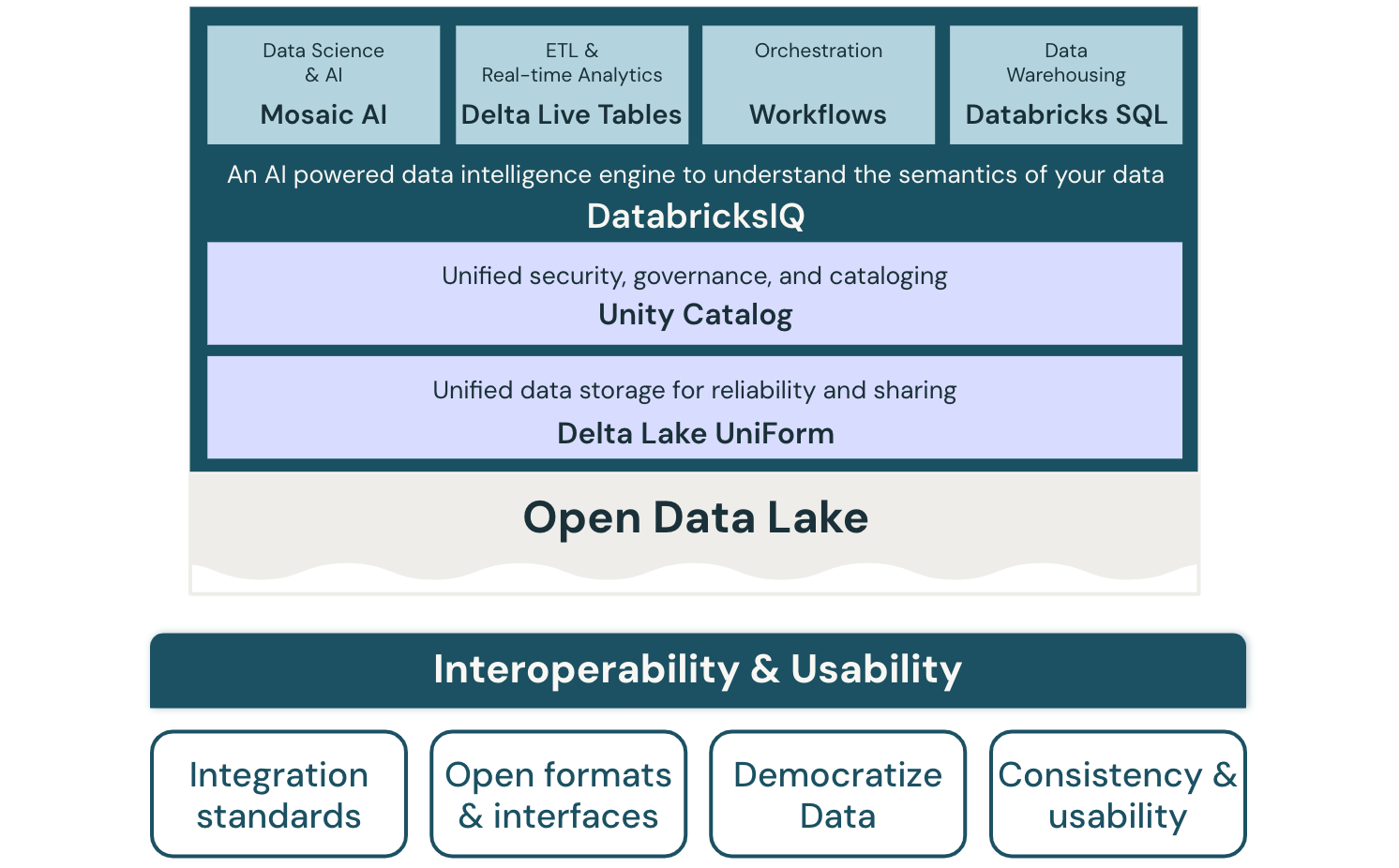
Interoperability and usability for the data lakehouse
This article covers architectural principles of the interoperability and usability pillar, referring to the lakehouse’s interaction with users and other systems. One of the fundamental ideas of the lakehouse is to provide a great user experience for all the personas that work with it, and to be able to interact with a wide ecosystem of external systems.
Interoperability is the ability of a system to work with and integrate with other systems. It implies interaction between different components and products, possibly from multiple vendors, and between past and future versions of the same product.
Usability is the measure of how well a system enables users to perform tasks safely, effectively, and efficiently.
Following the principles of this pillar help to:
Achieve a consistent and collaborative user experience.
Leverage synergies across clouds.
Simplify integration from and to the lakehouse.
Reduce training and enablement costs.
And ultimately lead to a faster time-to-value.
Principles of interoperability and usability
Define standards for integration
Integration has different aspects and can be done in many different ways. To avoid proliferating tools and approaches, best practices must be defined and a list of well-supported and preferred tools and connectors should be provided.
One of the key architectural principles are modularity and loose coupling rather than tight integration. This reduces dependencies between components and workloads, helps eliminate side effects, and enables independent development on different time scales. Use datasets and their schema as a contract. Separate workloads such as data wrangling jobs (such as loading and transforming data into a data lake) from value-adding jobs (for example reporting, dashboards, and data science feature engineering). Define a central data catalog with guidelines for data formats, data quality, and data lifecycle.
Use open interfaces and open data formats
Often, solutions are developed where data can only be accessed through a specific system. This can lead to vendor lock-in, but it can also become a huge cost driver if data access via that system is subject to license fees. Using open data formats and interfaces helps to avoid this. They also simplify integration with existing systems and open up an ecosystem of partners who have already integrated their tools with the lakehouse.
If you use open source ecosystems such as Python or R for data science, or Spark or ANSI SQL for data access and access rights control, you will have an easier time finding personnel for projects. It will also simplify potential migrations to and from a platform.
Simplify new use case implementation
To get the most out of the data in the data lake, users must be able to easily deploy their use cases on the platform. This starts with lean processes around platform access and data management. For example, self-service access to the platform helps prevent a central team from becoming a bottleneck. Shared environments and predefined blueprints for deploying new environments ensure that the platform is quickly available to any business user.
Ensure data consistency and usability
Two important activities on a data platform are data publishing and data consumption. From a publishing perspective, data should be offered as a product. Publishers need to follow a defined lifecycle with consumers in mind, and the data needs to be clearly defined with managed schemas, descriptions, and so on.
It is also important to provide semantically consistent data so that consumers can easily understand and correctly combine different data sets. In addition, all data must be easily discoverable and accessible to consumers through a central catalog with properly curated metadata and data lineage.
Next: Best practices for interoperability and usability
See Best practices for interoperability and usability.