Navigate the workspace
This article walks you through the Databricks workspace UI, an environment for accessing all of your Databricks objects.
You can manage the workspace using the workspace UI and the Workspace API. Most of the articles in the Databricks documentation focus on performing tasks using the workspace UI.
Homepage
The following sections of the workspace homepage provide shortcuts to common tasks and workspace objects to help you onboard to and navigate the Databricks Data Intelligence Platform:
Get started
This section provides shortcuts to the following common tasks across product areas:
Import data using the Create or modify table from file upload page
Create a notebook
Create a query
Configure an AutoML experiment
Note
The tiles that display on your homepage depend on your assigned entitlements.
Recents
This section displays your recently viewed objects across product areas, including files, notebooks, experiments, queries, dashboards, alerts, and Unity Catalog objects.
You can also access recents from the sidebar and from the search bar.
Popular
This section displays objects with the most user interactions in the last 30 days across product areas, including files, notebooks, experiments, queries, dashboards, and alerts.
Sidebar
The following common Databricks Data Intelligence Platform categories are visible at the top of the sidebar:
Workspace
Recents
Data
Workflows
Compute
Note
There is a lock icon next to items that require an entitlement you aren’t assigned.
The features in the following sections are also always visible in the sidebar, grouped by product area:

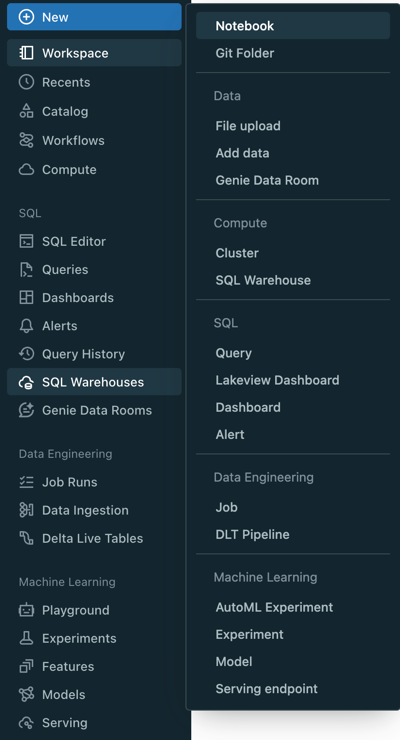
+ New menu
Click + New to complete the following tasks:
Create workspace objects such as notebooks, queries, repos, dashboards, alerts, jobs, experiments, models, and serving endpoints
Create compute resources such as clusters, SQL warehouses, and ML endpoints
Upload CSV or TSV files to Delta Lake using the Create or modify table from file upload page or load data from various data sources using the add data UI
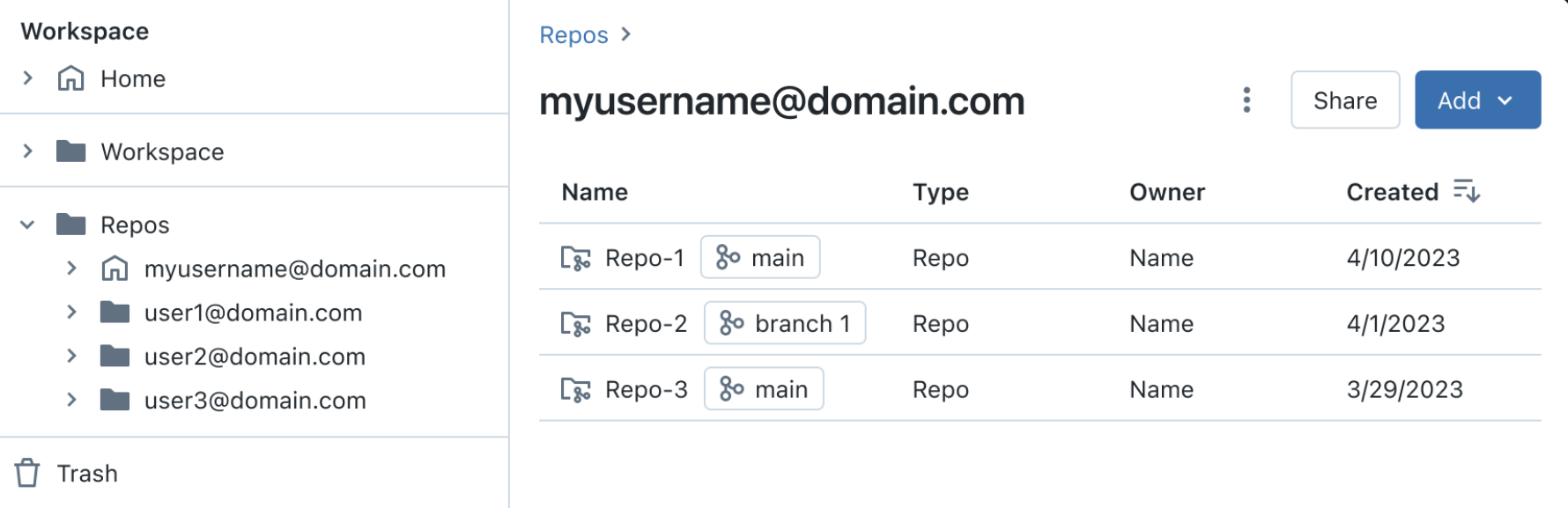
Full-page workspace browser
The full-page workspace browser experience unifies Workspace and Git folders.
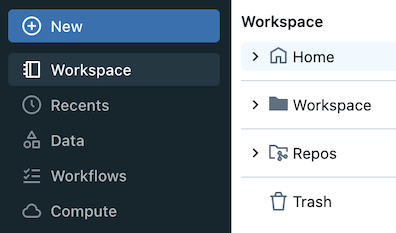
You can browse content in Databricks Git folders alongside workspace objects by clicking Workspace in the sidebar.
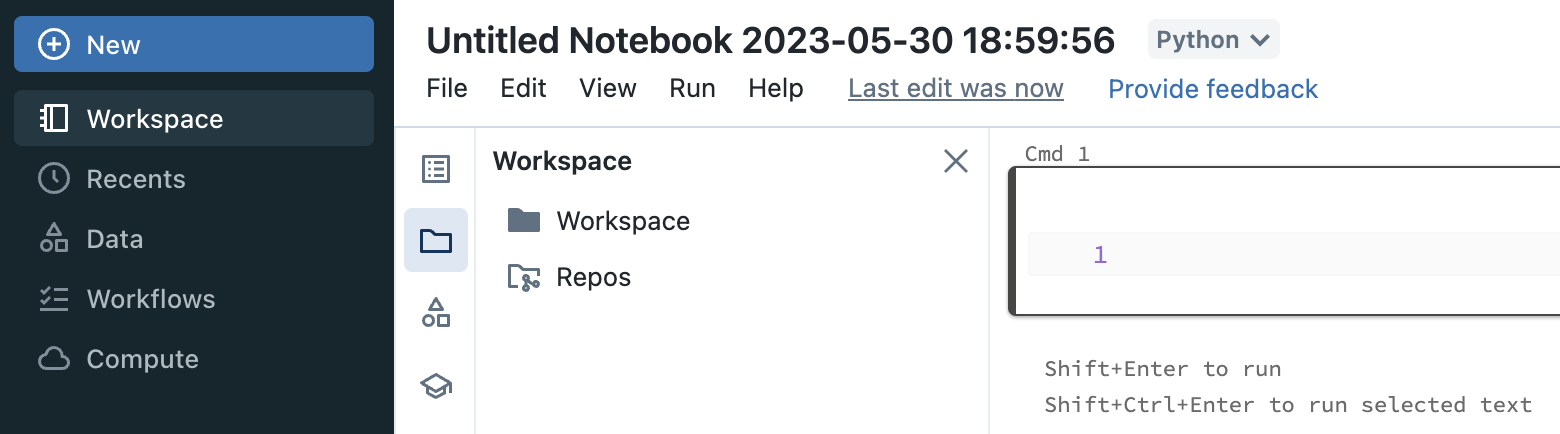
You can also browse workspace content and Git folders content from within a notebook using a contextual browser.
Search
Use the top bar to search for workspace objects such as notebooks, queries, dashboards, alerts, files, folders, libraries, tables registered in Unity Catalog, jobs, and repos in a single place. You can also access recently viewed objects in the search bar.
Workspace admin and user settings
Workspace admin and workspace user settings are unified across product areas. SQL settings are combined with general settings to create a unified experience for admin and non-admin users.
All workspace admin settings are now accessed from Settings.
All workspace user settings are now accessed from Settings.
The Password setting is on the Profile tab.
SQL query snippets (Settings > Developer) is visible to users with the Databricks SQL access entitlement.
Switch to a different workspace
If you have access to more than one workspace in the same account, you can quickly switch among them.
Click the workspace name in the top bar of the Databricks workspace.
Select a workspace from the drop-down to switch to it.
Change the workspace language settings
The workspace is available in multiple languages. To change the workspace language, click your username in the top navigation bar, select Settings and go to the Preferences tab.
Get help
This section describes the in-product help experience.
Click ![]() in the top bar of the workspace to access the following resources:
in the top bar of the workspace to access the following resources:
AI Assistant: Enter a question for the assistant in the text box. If your organization has a Databricks Support contract, at the top of your conversation, you can click Contact Support for additional help.

The assistant is intended to help quickly answer questions that can be answered with Databricks documentation and knowledge base articles. Its answers are based on documentation that the AI can find related to the question. If it cannot find documentation related to the user question, it declines to answer. Results include a link to any documentation used to answer the question. The assistant is new, so mistakes are possible. Check the facts with the linked documentation and share feedback.
You can also access Contact Support by clicking your user icon in the top bar of the workspace.

The assistant opens and triages your issue. If you still need help, click No, continue with ticket submission.

The Contact support modal opens.

Help: Visit the Help Center to search across Databricks documentation, Databricks Knowledge Base articles, Apache Spark documentation, training courses, and Databricks forums.
Send feedback: Use the feedback form to submit product feedback from your workspace. See Submit product feedback.