Databricks architecture overview
This article provides a high-level overview of Databricks architecture, including its enterprise architecture, in combination with Google Cloud.
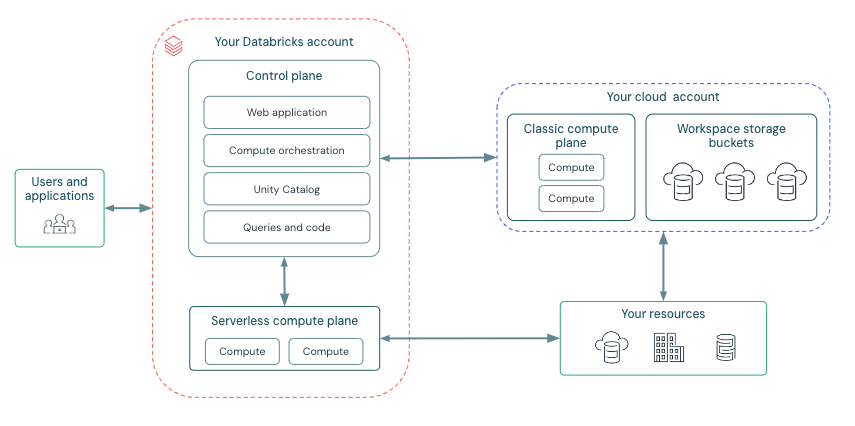
High-level architecture
Databricks operates out of a control plane and a compute plane.
The control plane includes the backend services that Databricks manages in your Databricks account. The web application is in the control plane.
The compute plane is where your data is processed. There are two types of compute planes depending on the compute that you are using.
For serverless compute, the serverless compute resources run in a serverless compute plane in your Databricks account.
For classic Databricks compute, the compute resources are in your Google Cloud resources in what is called the classic compute plane. This refers to the network in your Google Cloud resources and its resources.
To learn more about classic compute and serverless compute, see Types of compute.
Each Databricks workspace has two associated buckets account known as the workspace storage buckets. The workspace storage buckets are in your Google Cloud account.
The following diagram describes the overall Databricks architecture.
Serverless compute plane
In the serverless compute plane, Databricks compute resources run in a compute layer within your Databricks account. Databricks creates a serverless compute plane in the same Google Cloud region as your workspace’s classic compute plane. You select this region when creating a workspace.
To protect customer data within the serverless compute plane, serverless compute runs within a network boundary for the workspace, with various layers of security to isolate different Databricks customer workspaces and additional network controls between clusters of the same customer.
To learn more about networking in the serverless compute plane, Serverless compute plane networking.
Classic compute plane
In the classic compute plane, Databricks compute resources run in your Google Cloud account. New compute resources are created within each workspace’s virtual network in the customer’s Google Cloud account.
A classic compute plane has natural isolation because it runs in each customer’s own Google Cloud account. To learn more about networking in the classic compute plane, see Classic compute plane networking.
For regional support, see Databricks clouds and regions.
Workspace storage buckets
When you create a workspace, Databricks creates three buckets in your Google Cloud account to use as the workspace storage buckets.
One workspace storage bucket stores workspace system data that is generated as you use various Databricks features such as creating notebooks. This bucket includes notebook revisions, job run details, command results, and Spark logs.
Another workspace storage bucket is your workspace’s root storage for DBFS. DBFS (Databricks File System) is a distributed file system in Databricks environments accessible under the
dbfs:/namespace. DBFS root and DBFS mounts are both in thedbfs:/namespace. Storing and accessing data using DBFS root or DBFS mounts is a deprecated pattern and not recommended by Databricks. For more information, see What is DBFS?.If your workspace was enabled for Unity Catalog automatically, a third workspace storage buckets contains the default Unity Catalog workspace catalog. All users in your workspace can create assets in the default schema in this catalog. See Set up and manage Unity Catalog.
To limit access to your workspace storage buckets, see Secure the workspace’s GCS buckets in your project.