Visão geral da arquitetura do Databricks
Este artigo fornece uma visão geral de alto nível da arquitetura Databricks, incluindo sua arquitetura corporativa, em combinação com clouds do Google.
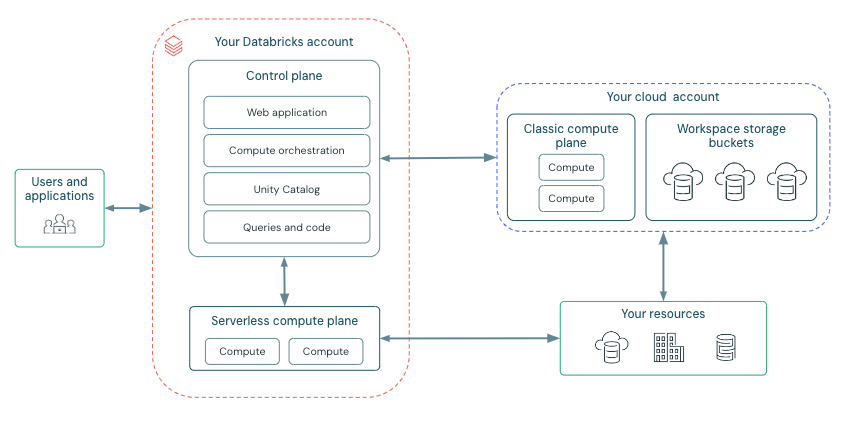
Arquitetura de alto nível
Databricks opera a partir de um plano de controle e de um planocompute .
O plano de controle inclui o serviço de backend que Databricks gerenciar em seu Databricks account. O aplicativo da Web está no plano de controle.
O planocompute é onde seus dados são processados. Há dois tipos de planos compute, dependendo do compute que o senhor estiver usando.
Para serverless compute, o serverless compute recurso execução em um serverless compute plano em seu Databricks account.
Para o clássico Databricks compute, o recurso compute está no seu recurso do Google cloud no que é chamado de plano clássico compute . Isso se refere à rede em seu recurso do Google cloud e seu recurso.
Para saber mais sobre os sites clássicos compute e serverless compute, consulte Types of compute.
Cada Databricks workspace tem dois buckets associados account conhecidos como buckets de armazenamentoworkspace . Os buckets de armazenamento workspace estão em seu Google cloud account.
O diagrama a seguir descreve a arquitetura geral do Databricks.
Plano de computação sem servidor
No plano serverless compute , Databricks compute recurso execução em uma camada compute dentro do seu Databricks account. Databricks cria um serverless compute plano na mesma região da nuvem do Google que workspaceo compute plano clássico do seu. O senhor seleciona essa região ao criar um workspace.
Para proteger os dados do cliente dentro do plano serverless compute , serverless compute execução dentro de um limite de rede para o workspace, com várias camadas de segurança para isolar diferentes espaços de trabalho do cliente Databricks e controles de rede adicionais entre clusters o mesmo cliente.
Para saber mais sobre redes no plano serverless compute , serverless compute plane networking.
Plano de computação clássico
No plano clássico compute, Databricks compute recurso execução em seu Google cloud account. Novos recursos do compute são criados em cada rede virtual do workspaceno Google cloud account do cliente.
Um avião clássico compute tem isolamento natural porque é executado no próprio Google cloud account de cada cliente. Para saber mais sobre a rede no plano clássico compute, consulte Rede no plano clássico compute .
Para obter suporte regional, consulte Nuvens e regiões do Databricks.
Baldes de armazenamento do espaço de trabalho
Quando o senhor cria um workspace, o Databricks cria três buckets no Google cloud account para serem usados como buckets de armazenamento workspace.
Um bucket de armazenamento workspace armazena dados do sistemaworkspace que são gerados à medida que o senhor usa vários recursos Databricks, como a criação do Notebook. Esse bucket inclui Notebook revisões, Job detalhes da execução, resultados do comando e Spark logs.
Outro bucket de armazenamento do workspace é o armazenamento raiz do seu workspace para DBFS. O DBFS (Databricks File System) é um sistema de arquivos distribuído em ambientes Databricks acessível sob o namespace
dbfs:/. DBFS root e DBFS mounts estão ambos no namespacedbfs:/. O armazenamento e o acesso a montagens de uso de dados DBFS root ou DBFS é um padrão obsoleto e não é recomendado por Databricks. Para obter mais informações, consulte O que é DBFS?Se o seu workspace foi ativado para Unity Catalog automaticamente, um terceiro bucket de armazenamento workspace contém o catálogo default Unity Catalog workspace . Todos os usuários do site workspace podem criar ativos no esquema default desse catálogo. Consulte Configurar e gerenciar o Unity Catalog.
Para limitar o acesso aos buckets de armazenamento do espaço de trabalho, consulte Proteger os buckets GCS do espaço de trabalho em seu projeto.