Databricksアーキテクチャの概要
この記事では、Databricks アーキテクチャの概要 (エンタープライズ アーキテクチャを含む) と Google クラウドの組み合わせについて説明します。
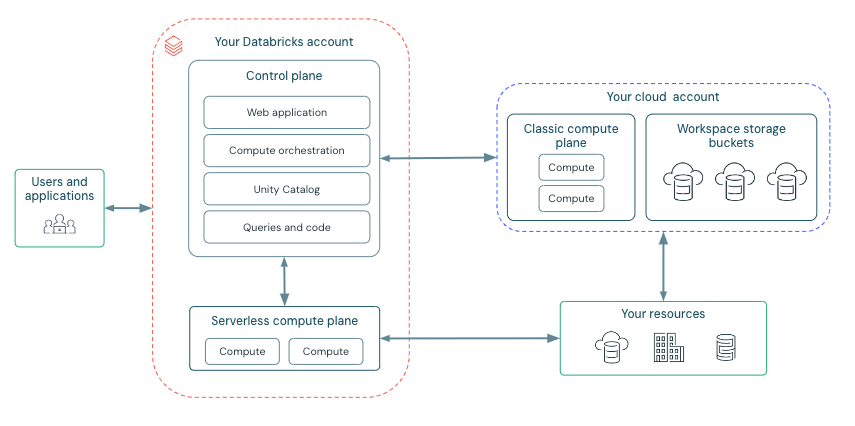
ハイレベルのアーキテクチャ
Databricks は、コントロールプレーンとコンピュートプレーンから動作します。
コントロールプレーンには、DatabricksアカウントでDatabricksが管理するバックエンドサービスが含まれます。 Webアプリケーションはコントロールプレーンにあります。
コンピュートプレーンは、データが処理される場所です。 使用するコンピュートに応じた2 種類のコンピュートプレーンが存在します。
サーバレスコンピュートの場合、サーバレスコンピュートリソースはDatabricksアカウントの サーバレスコンピュートプレーンで実行されます。
クラシックDatabricksコンピュートの場合、コンピュート リソースは、クラシック コンピュート プレーンと呼ばれる Google クラウド リソース内にあります。 これは、Google クラウド リソース内のネットワークとそのリソースを指します。
クラシック コンピュートとサーバレス コンピュートの詳細については、 コンピュートの種類を参照してください。
各 Databricks ワークスペースには、ワークスペース ストレージ バケットと呼ばれる 2 つの関連付けられたバケット アカウントがあります。 ワークスペース ストレージ バケットは Google クラウド アカウント内にあります。
次の図は、Databricks の全体的なアーキテクチャを示しています。
サーバレスコンピュートプレーン
サーバレス コンピュート プレーンで、Databricks アカウント内のコンピュート レイヤーでコンピュート リソースDatabricks実行します。Databricks は、ワークスペースの従来のコンピュート平面と同じ Google クラウド リージョンにサーバレス コンピュート平面を作成します。 このリージョンは、ワークスペースの作成時に選択します。
サーバーレスコンピュートプレーン内の顧客データを保護するために、サーバーレスコンピュートはワークスペースのネットワーク境界内で実行され、さまざまなセキュリティレイヤーを使用して、同じ顧客のクラスター間で異なるDatabricksワークスペースと追加のネットワーク制御を分離します。
サーバレスコンピュートプレーンでのネットワークの詳細については、 「サーバレスコンピュートプレーンのネットワーク」を参照してください。
クラシックコンピュートプレーン
従来のコンピュート プレーンでは、 Databricksコンピュート リソース が Google クラウド アカウントで実行されます。 顧客の Google クラウド アカウント内の各ワークスペースの仮想ネットワーク内に、新しいコンピュート リソースが作成されます。
従来のコンピュート プレーンは、各顧客独自の Google クラウド アカウントで実行されるため、自然な分離が実現します。 クラシック コンピュート プレーンでのネットワークの詳細については、 「クラシック コンピュート プレーンのネットワーク」を参照してください。
リージョンサポートについては、「Databricksのクラウドとリージョン」を参照してください。
ワークスペースストレージバケット
ワークスペースを作成すると、 Databricksワークスペース ストレージ バケットとして使用するために Google クラウド アカウントに 3 つのバケットを作成します。
1 つのワークスペース ストレージ バケットには、ノートブックの作成などのさまざまな Databricks 機能を使用するときに生成されるワークスペース システム データが格納されます。 このバケットには、ノートブックのリビジョン、ジョブ実行の詳細、コマンドの結果、Spark ログが含まれます。
もう 1 つのワークスペース ストレージ バケットは、 DBFS用のワークスペースのルート ストレージです。 DBFS (Databricks ファイル システム) は、
dbfs:/名前空間でアクセスできる Databricks 環境の分散ファイル システムです。 DBFSルートとDBFSマウントは両方ともdbfs:/名前空間にあります。 DBFSルートまたはDBFSマウントを使用してデータを保存およびアクセスすることは非推奨のパターンであり、 Databricksでは推奨されていません。 詳細については、 「 DBFSとは?」を参照してください。 。ワークスペースが Unity Catalog に対して自動的に有効になっている場合、3 番目のワークスペース ストレージ バケットにはデフォルトのUnity Catalog ワークスペース カタログが含まれます。 ワークスペース内のすべてのユーザーは、このカタログのデフォルト スキーマでアセットを作成できます。 「Unity Catalog のセットアップと管理」を参照してください。
ワークスペース ストレージ バケットへのアクセスを制限するには、 「プロジェクト内のワークスペースの GCS バケットを保護する」をご覧ください。