データレイクハウスとは
データレイクハウスは、データレイクとデータウェアハウスの利点を組み合わせたデータマネジメントシステムです。 この記事では、レイクハウスのアーキテクチャ パターンと、Databricks でそれを使用して実行できる操作について説明します。
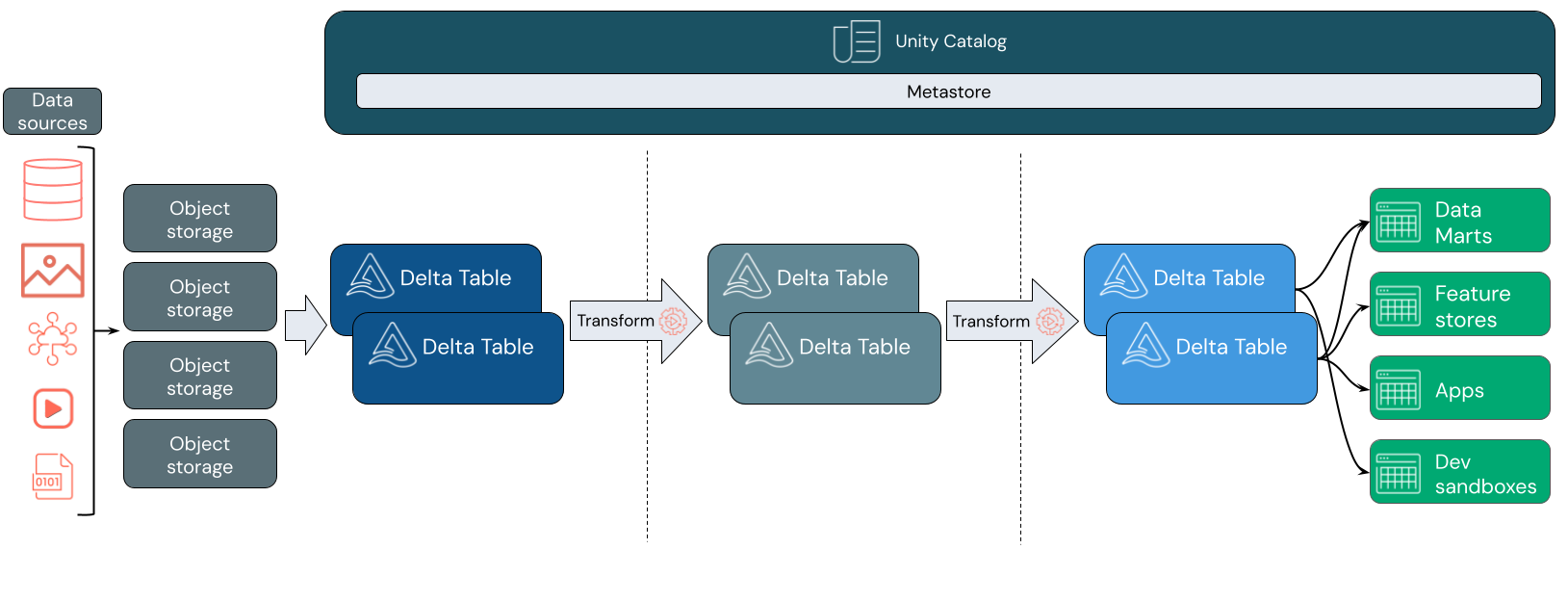
データレイクハウスの用途
データレイクハウスは、機械学習(ML)やビジネスインテリジェンス(BI)など、さまざまなワークロードを処理するための分離されたシステムを避けたいモダンな組織に、スケーラブルなストレージと処理機能を提供します。 データレイクハウスは、信頼できる唯一の情報源を確立し、冗長なコストを排除し、データの鮮度を確保するのに役立ちます。
データレイクハウスでは、多くの場合、ステージングと変換のレイヤーを通過するデータを段階的に改善、強化、精製するデータ設計パターンを使用します。 レイクハウスの各レイヤーには、1 つ以上のレイヤーを含めることができます。 このパターンは、多くの場合、メダリオン アーキテクチャと呼ばれます。 詳細については、メダリオン レイクハウスのアーキテクチャとはを参照してください。
Databricks レイクハウスのしくみ
Databricks は Apache Spark 上に構築されています。 Apache Spark は、ストレージから切り離されたコンピュート リソースで実行される、非常にスケーラブルなエンジンを実現します。 詳細については、Databricks 上の Apache Sparkを参照してください。
Databricks レイクハウスでは、次の2つの重要な技術が使用されています。
Delta Lake: ACIDトランザクションとスキーマ強制をサポートする最適化されたストレージレイヤー。
Unity Catalog: データと AI のための統合されたきめ細かなガバナンス ソリューション。
データの取り込み
データ取り込みレイヤーでは、バッチまたはストリーミングデータがさまざまなソースからさまざまな形式で到着します。 この最初の論理層は、そのデータが生の形式で配置される場所を提供します。 これらのファイルを Delta テーブルに変換するときに、Delta Lake のスキーマ強制機能を使用して、欠落しているデータや予期しないデータがないか確認できます。 Unity Catalog を使用して、データガバナンスモデルと必要なデータ分離境界に従ってテーブルを登録できます。 Unity Catalogでは、変換・精製されるデータのリネージを追跡することができます。また、統合されたガバナンスモデルを適用して、機密データをプライベートかつセキュアに維持することができます。
データ処理、キュレーション、統合
検証を完了させた後、データのキュレーションと精製を開始できます。 データサイエンティストやMLプラクティショナーは、この段階でデータを操作して、新しい特徴量の組み合わせや作成を開始したり、データクレンジングを完了させることが多いです。 データを十分にクレンジングした後、特定のビジネスニーズを満たすように設計されたテーブルとして統合および再編成できます。
スキーマ オン ライト アプローチと Delta スキーマ進化機能を組み合わせると、エンド ユーザーにデータを提供する後段のロジックを必ずしも書き換えることなく、このレイヤーに変更を加えることができます。
データ提供
最後のレイヤーでは、クリーンで補強されたデータをエンドユーザーに提供します。 最終的なテーブルは、すべてのユースケースにおけるデータを提供するように設計する必要があります。 統一されたガバナンスモデルにより、データリネージを単一の真実の情報源までさかのぼって追跡できます。 さまざまなタスクに最適化されたデータレイアウトにより、エンドユーザーは機械学習アプリケーション、 データエンジニアリング、ビジネスインテリジェンス、レポート作成用のデータにアクセスできます。
Delta Lake の詳細については、 Delta Lake とはを参照してください。Unity Catalog の詳細については、Unity Catalog とはを参照してください。
Databricks レイクハウスの機能
Databricks上に構築されたレイクハウスは、モダンなデータ企業のデータレイクとデータウェアハウスへの依存性を排除します。実行できる主なタスクには、次のようなものがあります。
リアルタイムデータ処理: ストリーミングデータをリアルタイムで処理し、即座に分析とアクションを行います。
データ統合: データを 1 つのシステムに統合してコラボレーションを可能にし、組織にとって信頼できる唯一の情報源を確立します。
スキーマ進化: データスキーマを時間の経過とともに変更し、既存のデータパイプラインを中断することなく、変化するビジネスニーズに適応します。
データ変換: Apache Spark と Delta Lake を使用して、データの速度、スケーラビリティ、信頼性を向上させます。
データ分析とレポート作成: データウェアハウジングのワークロードに最適化されたエンジンによって、複雑な分析クエリーを実行します。
機械学習とAI: 高度な分析手法をすべてのデータに適用します。 機械学習を使用してデータを拡張し、他のワークロードをサポートします。
データのバージョン管理とリネージ: データセットのバージョン履歴を維持し、リネージを追跡して、データの出所とトレーサビリティを確保します。
データガバナンス: 単一の統合システムを使用して、データへのアクセスを制御し、監査を実行します。
データ共有: キュレーションされたデータセット、レポート、知見をチーム間で共有できるようにすることで、コラボレーションを促進します。
オペレーショナルアナリティクス: レイクハウスのモニタリングデータに機械学習を適用することで、データ品質メトリクス、モデル品質メトリクス、ドリフトを監視します。
レイクハウス vs データレイク vs データウェアハウス
データウェアハウスは、約30年にわたりビジネスインテリジェンス(BI)の意思決定を支え、データフローを制御するシステムの一連の設計ガイドラインとして進化してきました。 エンタープライズデータウェアハウスは、BIレポートのクエリーを最適化しますが、結果の生成には数分から数時間かかる場合があります。 データウェアハウスは、高い頻度で変更される可能性が低いデータ用に設計されており、同時に実行されるクエリー間の競合を防止しようとします。 多くのデータウェアハウスは独自の形式に依存しているため、機械学習のサポートが制限されることがよくあります。 Databricks 上のデータウェアハウジングは、Databricks レイクハウスと Databricks SQL の機能を活用します。 詳細については、Databricks のデータウェアハウジングとはを参照してください。
データストレージの技術の進歩とデータの種類と量の急激な増加を受けて、データレイクは過去10年間で広く利用されるようになりました。データレイクは、安価かつ効率的なデータの保存と処理を行います。多くの場合、データレイクはデータウェアハウスと対比して定義されます。データウェアハウスはBIアナリティクス用にクリーンな構造化データを提供しますが、データレイクは、あらゆる性質のデータをあらゆる形式で永続的かつ安価に保存します。多くの組織においてデータレイクはデータサイエンスと機械学習に使用されていますが、検証されていない性質があるためBIレポートには使用されません。
データレイクハウスは、データレイクとデータウェアハウスの利点を組み合わせることにより、以下を提供します。
標準的なデータ形式で保存されたデータへのオープンかつダイレクトなアクセス。
機械学習とデータサイエンス向けに最適化されたインデックス作成プロトコル。
クエリーの待ち時間が短く、BIと高度なアナリティクスに対する高い信頼性。
データレイクハウスは、最適化されたメタデータレイヤーと、クラウドオブジェクトストレージに標準形式で保存された検証済みデータを組み合わせることで、データサイエンティストと機械学習エンジニアが同じデータドリブンBIレポートからモデルを構築できるようにします。
次のステップ
Databricks を使用してレイクハウスを実装および運用するための原則とベスト プラクティスの詳細については、 well-architectedデータレイクハウスの紹介を参照してください。