メダリオンレイクハウスアーキテクチャとは
メダリオンアーキテクチャは、レイクハウスに格納されているデータの品質を示す一連のデータレイヤーを表します。 Databricksでは、エンタープライズデータ製品の信頼できる唯一の情報源を構築するために、多層アプローチを採用することをお勧めします。
このアーキテクチャでは、データを効率的なアナリティクス用に最適化されたレイアウトに格納される前に、検証と変換の複数のレイヤーを通過させることで、原子性、独立性、分離性、および耐久性を保証します。 ブロンズ (生)、シルバー (検証済み)、および ゴールド (補強) という用語は、これらの各レイヤーのデータの品質を表します。
データ設計パターンとしてのメダリオンアーキテクチャ
メダリオンアーキテクチャは、データを論理的に整理するために使用されるデータ設計パターンです。 その目標は、アーキテクチャの各レイヤー (ブロンズ テーブル⇒、シルバー テーブル、ゴールドレイヤー テーブル) を流れるデータの構造と品質を段階的かつ段階的に向上させることです (ブロンズ テーブル、シルバー テーブル⇒)。 メダリオンアーキテクチャは、 マルチホップアーキテクチャと呼ばれることもあります。
これらのレイヤーを通じてデータを進めることで、組織はデータの品質と信頼性を段階的に向上させ、ビジネスインテリジェンスや機械学習アプリケーションにより適したものにすることができます。
メダリオンアーキテクチャに従うことは推奨されるベスト プラクティスですが、必須ではありません。
質問 |
青銅 |
銀 |
ゴールド |
|---|---|---|---|
このレイヤーでは何が起こるのでしょうか? |
Raw データ取り込み |
データのクリーニングと検証 |
ディメンション・モデリングとアグリゲーション |
対象ユーザーは誰ですか? |
|
|
|
例 メダリオンアーキテクチャ
このメダリオンアーキテクチャの例は、ビジネス運用チームが使用するブロンズ、シルバー、およびゴールドレイヤーを示しています。 各レイヤーは、ops カタログの異なるスキーマに格納されます。
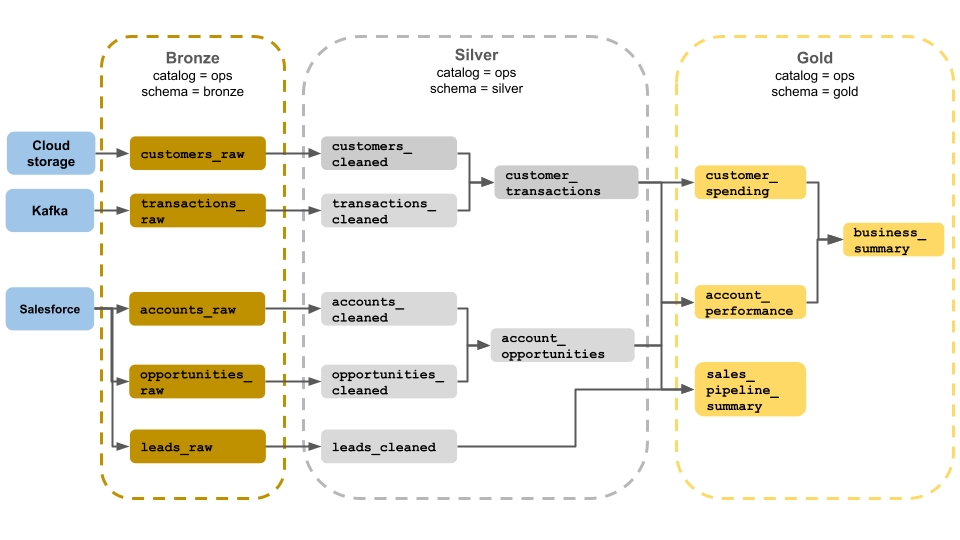
ブロンズレイヤー (
ops.bronze):クラウドストレージ、Kafka、Salesforceから生データを取り込みます。 ここでは、データのクリーンアップや検証は実行されません。シルバーレイヤー (
ops.silver):データのクリーンアップと検証は、このレイヤーで実行されます。顧客とトランザクションに関するデータは、null を削除し、無効なレコードを検疫することでクリーンアップされます。 これらのデータセットは、
customer_transactionsという新しいデータセットに結合されます。 data scientists このデータセットを予測分析に使用できます。同様に、Salesforce のアカウント データセットと opportunity データセットを結合して
account_opportunitiesを作成し、これはアカウント 情報で強化されています。leads_rawデータは、leads_cleanedというデータセットでクリーニングされます。
ゴールドレイヤー (
ops.gold):このレイヤーはビジネスユーザー向けに設計されています。 銀や金よりもデータセットが少なくて済みます。customer_spending: 各顧客の平均支出額と合計支出額。account_performance: 各アカウントの日次パフォーマンス。sales_pipeline_summary: エンドツーエンドの販売パイプラインに関する情報。business_summary: エグゼクティブ スタッフ向けの高度に集約された情報。
生データをブロンズレイヤーに取り込む
ブロンズレイヤーには、未検証の生データが含まれています。 ブロンズレイヤーに取り込まれるデータには、通常、次の特性があります。
データソースの生の状態を元の形式で保存し、維持します。
増分的に追加され、時間の経過と共に大きくなります。
は、シルバー テーブル用のエンリッチデータ ワークロードによる消費を目的としており、アナリストや data scientistsによるアクセスを目的としていません。
真実の 1 つのソースとして機能し、データの忠実性を維持します。
すべてのヒストリカルデータを保持することで、再処理と監査を可能にします。
クラウドオブジェクトストレージ ( S3、 GCS、 ADLSなど)、メッセージバス ( Kafka、 Kinesisなど)、フェデレーテッドシステム (レイクハウスフェデレーションなど) など、ソースからのストリーミングトランザクションとバッチトランザクションの任意の組み合わせにすることができます。
シルバーレイヤーのデータを検証して重複排除する
データのクリーンアップと検証は、シルバーレイヤーで実行されます。
ブロンズレイヤーからシルバーテーブルを組み立てる
シルバーレイヤーを構築するには、1 つ以上のブロンズテーブルまたはシルバーテーブルからデータを読み取り、シルバーテーブルにデータを書き込みます。
Databricks では、インジェストから直接シルバー テーブルに書き込むことはお勧めしません。 インジェストから直接書き込むと、スキーマの変更やデータソースのレコードの破損によるエラーが発生します。 すべてのソースが追加専用であると仮定して、ブロンズからのほとんどの読み取りをストリーミング読み取りとして構成します。 バッチ読み取りは、小さなデータセット (小さなディメンション テーブルなど) 用に予約する必要があります。
シルバーレイヤーは、検証、クリーニング、およびエンリッチされたバージョンのデータを表します。 シルバーレイヤー:
各レコードの少なくとも 1 つの検証済みの非集計表現を常に含める必要があります。 集約表現が多くのダウンストリーム ワークロードを駆動する場合、それらの表現はシルバーレイヤーにある可能性がありますが、通常はゴールドレイヤーにあります。
ここでは、データクレンジング、重複除去、正規化を実行します。
エラーや不整合を修正することでデータ品質を向上させます。
データをより消費しやすい形式に構造化し、ダウンストリーム処理に利用できるようにします。
ゴールドレイヤーを使用して高度な分析を行う
ゴールドレイヤーは、ダウンストリーム分析、ダッシュボード、 ML、およびアプリケーションを推進するデータの高度に洗練されたビューを表します。 ゴールドレイヤー データは、多くの場合、特定の期間または地理的地域に対して高度に集約され、フィルタリングされます。 これには、ビジネス機能とニーズに対応する意味的に意味のあるデータセットが含まれています。
ゴールドレイヤー:
アナリティクスとレポート用に調整された集計データで構成されます。
ビジネス ロジックと要件に合わせます。
クエリとダッシュボードのパフォーマンスに最適化されています。
ビジネスロジックと要件に合わせる
ゴールドレイヤーでは、ディメンションモデルを使用して、関係を確立し、メジャーを定義することで、レポート作成と分析のためのデータをモデル化します。 ゴールドのデータにアクセスできるアナリストは、ドメイン固有のデータを見つけて質問に答えることができるはずです。
ゴールドレイヤーはビジネス ドメインをモデル化するため、一部の顧客は、人事、財務、 ITなど、さまざまなビジネス ニーズを満たすために複数のゴールドレイヤーを作成します。
アナリティクスとレポート用に調整された集計を作成する
多くの場合、組織は、平均、カウント、最大値、最小値などのメジャーの集計関数を作成する必要があります。 たとえば、ビジネスで週次売上の合計に関する質問に答える必要がある場合は、このデータを事前に集計する weekly_sales という具体化されたビューを作成して、アナリストや他のユーザーが頻繁に使用する具体化されたビューを再作成する必要がないようにすることができます。
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
クエリとダッシュボードのパフォーマンスの最適化
ゴールドレイヤーテーブルのパフォーマンスを最適化することは、これらのデータセットが頻繁にクエリされるため、ベストプラクティスです。 通常、大量のヒストリカルデータはスライバー レイヤーでアクセスされ、ゴールド レイヤーでは具体化されません。
データ取り込みの頻度を調整することでコストを制御
データを取り込む頻度を決定することで、コストを制御します。
データ取り込み頻度 |
コスト |
レイテンシー |
宣言型の例 |
手続きの例 |
|---|---|---|---|---|
継続的なインクリメンタルインジェスト |
高い |
下げる |
|
|
トリガーされた増分インジェスト |
下げる |
高い |
|
|
手動インクリメンタルインジェストによるバッチインジェスト |
下げる |
最も高かったのは、実行頻度が低いためです。 |
|