Qual é a arquitetura da casa de lago do medalhão?
A arquitetura medalhão descreve uma série de camadas de dados que denotam a qualidade dos dados armazenados na casa do lago. A Databricks recomenda adotar uma abordagem em várias camadas para criar uma única fonte confiável para produtos de dados corporativos.
Essa arquitetura garante atomicidade, consistência, isolamento e durabilidade à medida que os dados passam por várias camadas de validações e transformações antes de serem armazenados em uma disposição otimizada para uma análise eficiente. Os termos bronze (bruto), prata (validado) e ouro (enriquecido) descrevem a qualidade dos dados em cada uma dessas camadas.
Arquitetura Medallion como padrão de design de dados
A arquitetura medalhão é um padrão de design de dados usado para organizar dados logicamente. Seu objetivo é melhorar de forma incremental e progressiva a estrutura e a qualidade dos dados à medida que eles fluem por cada camada da arquitetura (de Bronze ⇒ Prata ⇒ Ouro). Às vezes, as arquiteturas Medallion também são chamadas de arquiteturas multi-hop.
Com o avanço dos dados por essas camadas, as organizações podem melhorar gradativamente a qualidade e a confiabilidade dos dados, tornando-os mais adequados para aplicativos de Business Intelligence e machine learning.
Seguir a arquitetura do medalhão é uma prática recomendada, mas não um requisito.
Pergunta |
Bronze |
Prata |
ouro |
|---|---|---|---|
O que acontece nessa camada? |
Ingestão bruta de dados |
Limpeza e validação de dados |
Modelagem dimensional e agregação |
Quem é o usuário pretendido? |
|
|
|
Exemplo de arquitetura de medalhão
Este exemplo de arquitetura de medalhão mostra camadas de bronze, prata e ouro para uso por uma equipe de operações comerciais. Cada camada é armazenada em um esquema diferente do catálogo de operações.
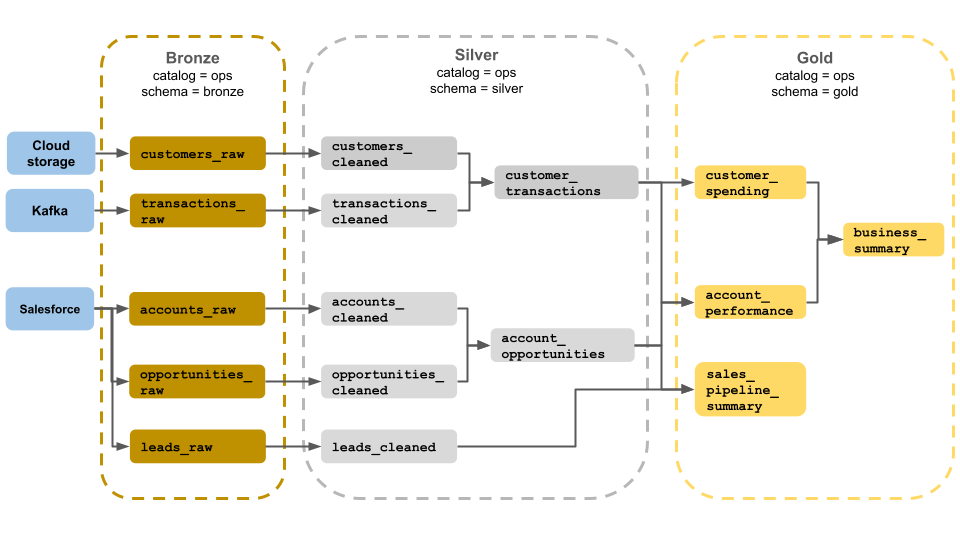
Camada de bronze (
ops.bronze): Ingere dados brutos do armazenamento cloud, Kafka e Salesforce. Nenhuma limpeza ou validação de dados é realizada aqui.Camada prateada (
ops.silver): A limpeza e validação de dados são realizadas nessa camada.Os dados sobre clientes e transações são limpos eliminando os valores nulos e colocando em quarentena os registros inválidos. Esses conjuntos de dados são unidos em um novo dataset chamado
customer_transactions. data scientists pode usar este dataset para análise preditiva.Da mesma forma, os conjuntos de dados de contas e oportunidades do Salesforce são unidos para criar
account_opportunities, que é aprimorado com as informações do account.Os dados
leads_rawsão limpos em um dataset chamadoleads_cleaned.
camada de ouro (
ops.gold): Essa camada foi projetada para usuários corporativos. Ele contém menos conjuntos de dados do que o silver e o ouro.customer_spending: Gasto médio e total de cada cliente.account_performance: Desempenho diário para cada account.sales_pipeline_summary: informações sobre as ventas de ponta a ponta pipeline.business_summary: Informações altamente agregadas para a equipe executiva.
Ingerir dados brutos na camada bronze
A camada de bronze contém dados brutos e não validados. Os dados ingeridos na camada de bronze normalmente têm as seguintes características:
Contém e mantém o estado bruto da fonte de dados em seus formatos originais.
É acrescentado de forma incremental e cresce com o tempo.
Destina-se ao consumo por cargas de trabalho que enriquecem dados para tabelas de prata, não para acesso por analistas e data scientists.
Serve como a única fonte da verdade, preservando a fidelidade dos dados.
Permite o reprocessamento e a auditoria ao reter todos os dados históricos.
Pode ser qualquer combinação de transações de transmissão e lotes de fontes, incluindo armazenamento de objetos em cloud (por exemplo, S3, GCS, ADLS), barramentos de mensagens (por exemplo, Kafka, Kinesis, etc.) e sistemas federados (por exemplo, Lakehouse Federation).
Limitar a limpeza ou validação de dados
A validação mínima de dados é realizada na camada de bronze. Para garantir que os dados não sejam descartados, o site Databricks recomenda armazenar a maioria dos campos como strings, VARIANT ou binários para proteger contra alterações inesperadas no esquema. Colunas de metadados podem ser adicionadas, como a proveniência ou a fonte dos dados (por exemplo, _metadata.file_name ).
Validar e eliminar a duplicação de dados na camada prateada
A limpeza e validação dos dados são realizadas na camada prateada.
Construa mesas de prata a partir da camada de bronze
Para criar a camada prateada, leia os dados de uma ou mais tabelas de bronze ou prata e grave os dados nas tabelas prateadas.
A Databricks não recomenda a gravação em tabelas silver diretamente da ingestão. Se o senhor escrever diretamente a partir da ingestão, ocorrerão falhas devido a alterações no esquema ou registros corrompidos na fonte de dados. Supondo que todas as fontes sejam append-only, configure a maioria das leituras do bronze como leituras de transmissão. As leituras em lotes devem ser reservadas para conjuntos de dados pequenos (por exemplo, tabelas dimensionais pequenas).
A camada prateada representa versões validadas, limpas e enriquecidas dos dados. A camada prateada:
Sempre deve incluir pelo menos uma representação validada e não agregada de cada registro. Se as representações agregadas conduzirem muitas cargas de trabalho downstream, essas representações podem estar na camada prata, mas normalmente estão na camada ouro.
É onde o senhor realiza a limpeza de dados, a deduplicação e a normalização.
Melhora a qualidade dos dados corrigindo erros e inconsistências.
Estrutura os dados em um formato mais consumível para processamento posterior.
Imponha a qualidade dos dados
As seguintes operações são realizadas em tabelas de prata:
Imposição de esquema
Tratamento de valores nulos e ausentes
Desduplicação de dados
Resolução de problemas de dados fora de ordem e de chegada tardia
Verificações e fiscalização da qualidade dos dados
evolução do esquema
Tipo de fundição
unir-se
começar a modelar dados
É comum começar a realizar a modelagem de dados na camada prata, incluindo a escolha de como representar dados muito aninhados ou semiestruturados:
Use o tipo de dados
VARIANT.Use
JSONstrings.Crie estruturas, mapas e matrizes.
Nivele o esquema ou normalize os dados em várias tabelas.
Potencialize a análise com a camada dourada
A camada de ouro representa uma visão altamente refinada dos dados que impulsionam análises downstream, dashboards, ML e aplicativos. Os dados da camada de ouro geralmente são altamente agregados e filtrados para períodos de tempo ou regiões geográficas específicas. Ele contém um conjunto de dados semanticamente significativo que mapeia as funções e as necessidades da empresa.
A camada de ouro:
Consiste em dados agregados adaptados para análise e geração de relatórios.
Alinha-se à lógica e aos requisitos de negócios.
É otimizado para desempenho em consultas e painéis.
Alinhe-se à lógica e aos requisitos de negócios
A camada de ouro é onde o senhor modelará seus dados para relatórios e análises usando um modelo dimensional, estabelecendo relacionamentos e definindo medidas. O analista com acesso aos dados no ouro deve ser capaz de encontrar dados específicos do domínio e responder a perguntas.
Como a camada ouro modela um domínio de negócios, alguns clientes criam várias camadas ouro para atender a diferentes necessidades de negócios, como RH, finanças e IT.
Criar agregados adaptados para análises e relatórios
As organizações geralmente precisam criar funções agregadas para medidas como médias, contagens, máximos e mínimos. Por exemplo, se sua empresa precisa responder a perguntas sobre o total de vendas semanais, o senhor pode criar uma materialização view chamada weekly_sales que pré-agrega esses dados para que o analista e outros não precisem recriar a visualização materializada usada com frequência.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Otimizar o desempenho em consultas e painéis
A otimização das tabelas de camada de ouro para desempenho é uma prática recomendada porque esses conjuntos de dados são consultados com frequência. Grandes quantidades de dados históricos são normalmente acessadas na camada sliver e não materializadas na camada ouro.
Controle os custos ajustando a frequência da ingestão de dados
Controle os custos determinando a frequência com que os dados devem ser ingeridos.
Frequência de ingestão de dados |
Custo |
Latência |
Exemplos declarativos |
Exemplos processuais |
|---|---|---|---|---|
Ingestão incremental contínua |
Mais alto |
Inferior |
|
|
Ingestão incremental desencadeada |
Inferior |
Mais alto |
|
|
ingestão de lotes com ingestão incremental manual |
Inferior |
Mais alto, por causa da execução pouco frequente. |
|