O que são transformações de dados em Databricks?
A transformação de dados é o processo de conversão, limpeza e estruturação de dados em um formato utilizável. As transformações de dados normalmente seguem a Databricks arquitetura do medalhão de refinamento incremental dos dados brutos em um formato consumível pela empresa.
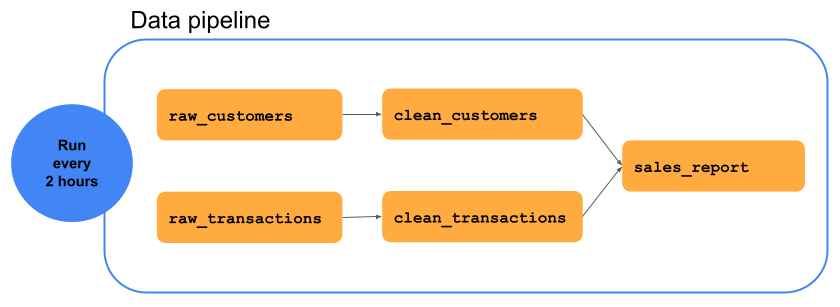
O diagrama a seguir mostra um pipeline de dados contendo uma série de transformações de dados que transformam o raw_customers dataset no clean_customers dataset, eliminando dados do cliente sem nome de cliente neste exemplo. Os dados raw_transactions são transformados em clean_transactions eliminando transações com valor de zero dólar. O dataset resultante, chamado sales_report, é a união do clean_customers e do clean_transactions. O analista pode usar o site sales_report para analítica e Business Intelligence.
Tipos de transformações de dados
A Databricks considera dois tipos de transformações de dados: declarativa e processual. O pipeline de dados no exemplo anterior pode ser expresso usando qualquer um dos paradigmas.
As transformações declarativas concentram-se no resultado desejado e não em como alcançá-lo. O senhor especifica a lógica das transformações usando abstrações de nível superior, e o site Delta Live Tables determina a maneira mais eficiente de executá-la.
As transformações de dados processuais concentram-se na realização de cálculos por meio de instruções explícitas. Esses cálculos definem a sequência exata de operações para manipular os dados. A abordagem processual fornece mais controle sobre a execução, mas ao custo de maior complexidade e maior manutenção.
Escolher entre transformações de dados declarativas e processuais
As transformações declarativas de dados usando o site Delta Live Tables são melhores quando o senhor está em uma situação em que não há necessidade de usar o site:
Você precisa de desenvolvimento e implantação rápidos.
Seu pipeline de dados tem padrões padrão que não exigem controle de baixo nível sobre a execução.
O senhor precisa de verificações integradas da qualidade dos dados.
Manutenção e legibilidade são as principais prioridades.
As transformações de dados procedimentais usando o código Apache Spark são melhores quando o senhor está em uma situação em que o código é mais adequado:
O senhor está migrando uma base de código existente do Apache Spark para a Databricks.
Você precisa de um controle refinado sobre a execução.
O senhor precisa ter acesso a APIs de baixo nível, como
MERGEouforeachBatch.O senhor precisa gravar dados no Kafka ou em tabelas Delta externas.