Databricks でのデータ変換とは
データ変換とは、データを使用可能な形式に変換、クレンジング、構造化するプロセスです。 データ変換は通常、Databricksの メダリオンアーキテクチャ に従って、生のデータをビジネスで利用可能な形式に段階的に絞り込みます。
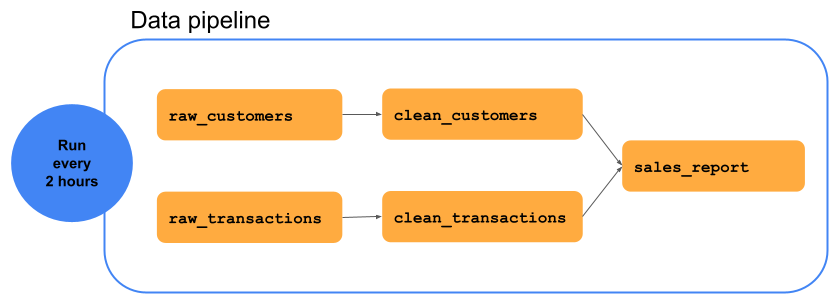
次の図は、この例で顧客名のない顧客データを削除することで、 raw_customers データセットを clean_customers データセットに変換する一連のデータ変換を含むデータパイプラインを示しています。 raw_transactionsデータは、ゼロのドル値でトランザクションを削除することでclean_transactionsに変換されます。sales_report と呼ばれる結果のデータセットは、clean_customers と clean_transactionsの結合です。アナリストは、 sales_report をアナリティクスとビジネスインテリジェンスに使用できます。
データ変換の種類
Databricks では、 宣言型 と 手続き型の 2 種類のデータ変換が考慮されます。 前の例のデータパイプラインは、どちらのパラダイムを使用しても表現できます。
宣言型変換は、目的の結果をどのように達成するかではなく、望ましい結果に焦点を当てます。 変換のロジックは上位レベルの抽象化を使用して指定し、Delta Live Tables によって最も効率的な実行方法が決定されます。
手続き型データ変換は、明示的な命令による計算の実行に重点を置いています。 これらの計算は、データを操作するための操作の正確なシーケンスを定義します。 手続き型アプローチでは、実行をより詳細に制御できますが、複雑さが増し、メンテナンスが難しくなります。
宣言型データ変換と手続き型データ変換のどちらを選択するか
Delta Live Tables を使用した宣言型データ変換は、次の場合に最適です。
迅速な開発とデプロイが必要です。
データパイプラインには、実行を低レベルで制御する必要のない標準パターンがあります。
組み込みのデータ品質チェックが必要です。
メンテナンスと可読性は最優先事項です。
Apache Spark コードを使用した手続き型データ変換は、次の場合に最適です。
既存の Apache Spark コードベースを Databricks に移行しています。
実行をきめ細かく制御する必要があります。
MERGEやforeachBatchなどの低レベルの APIs にアクセスする必要があります。Kafka または外部の Delta テーブルにデータを書き込む必要があります。