Concepts
This section describes concepts to help you use feature tables in Databricks.
Feature store
A feature store is a centralized repository that enables data scientists to find and share features and also ensures that the same code used to compute the feature values is used for model training and inference. The implementation of a feature store in Databricks depends on if your workspace is enabled for Unity Catalog or not. In workspaces that are enabled for Unity Catalog, any Delta table serves as a feature table, and Unity Catalog acts as a feature store — no separate step is needed to register a table as a feature table. Workspaces not enabled for Unity Catalog that were created before August 19, 2024, 4:00:00 PM (UTC) have access to the legacy Workspace Feature Store.
Machine learning uses existing data to build a model to predict future outcomes. In almost all cases, the raw data requires preprocessing and transformation before it can be used to build a model. This process is called feature engineering, and the outputs of this process are called features - the building blocks of the model.
Developing features is complex and time-consuming. An additional complication is that for machine learning, feature calculations need to be done for model training, and then again when the model is used to make predictions. These implementations might not be done by the same team or using the same code environment, which can lead to delays and errors. Also, different teams in an organization will often have similar feature needs but might not be aware of work that other teams have done. A feature store is designed to address these problems.
Feature tables
Features are organized as feature tables. Each table must have a primary key, and is backed by a Delta table and additional metadata. Feature table metadata tracks the data sources from which a table was generated and the notebooks and jobs that created or wrote to the table.
With Databricks Runtime 13.3 LTS and above, if your workspace is enabled for Unity Catalog, you can use any Delta table in Unity Catalog with a primary key as a feature table. See Work with feature tables in Unity Catalog. Feature tables that are stored in the local Workspace Feature Store are called “Workspace feature tables”. See Work with feature tables in Workspace Feature Store (legacy).
Features in a feature table are typically computed and updated using a common computation function.
FeatureLookup
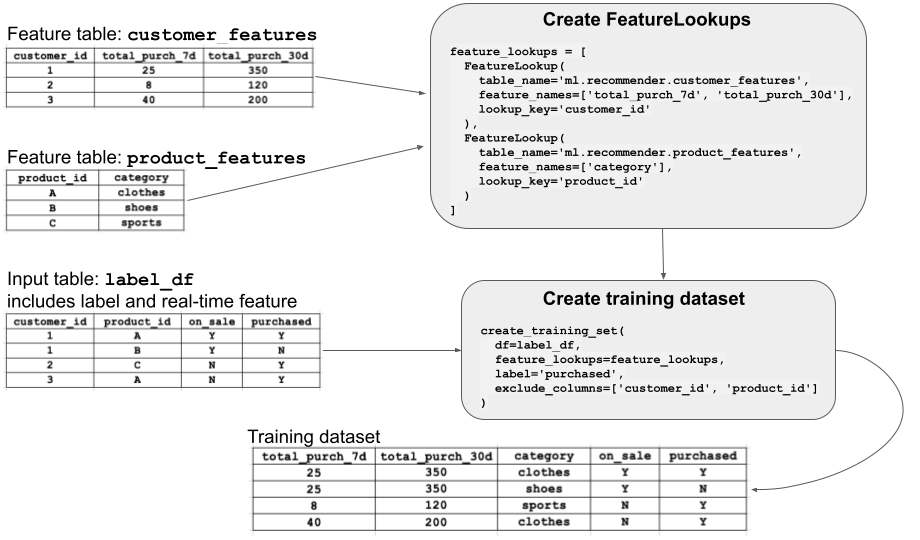
Many different models might use features from a particular feature table, and not all models will need every feature. To train a model using features, you create a FeatureLookup for each feature table. The FeatureLookup specifies which features to use from the table, and also defines the keys to use to join the feature table to the label data passed to create_training_set.
The diagram illustrates how a FeatureLookup works. In this example, you want to train a model using features from two feature tables, customer_features and product_features. You create a FeatureLookup for each feature table, specifying the name of the table, the features (columns) to select from the table, and the lookup key to use when the joining features to create a training dataset.
You then call create_training_set, also shown in the diagram. This API call specifies the DataFrame that contains the raw training data (label_df), the FeatureLookups to use, and label, a column that contains the ground truth. The training data must contain column(s) corresponding to each of the primary keys of the feature tables. The data in the feature tables is joined to the input DataFrame according to these keys. The result is shown in the diagram as the “Training dataset”.
Training set
A training set consists of a list of features and a DataFrame containing raw training data, labels, and primary keys by which to look up features. You create the training set by specifying features to extract from Feature Store, and provide the training set as input during model training.
See Create a training dataset for an example of how to create and use a training set.
When you train and log a model using Feature Engineering in Unity Catalog, you can view the model’s lineage in Catalog Explorer. Tables and functions that were used to create the model are automatically tracked and displayed. See Feature governance and lineage.
Time series feature tables (point-in-time lookups)
The data used to train a model often has time dependencies built into it. When you build the model, you must consider only feature values up until the time of the observed target value. If you train on features based on data measured after the timestamp of the target value, the model’s performance may suffer.
Time series feature tables include a timestamp column that ensures that each row in the training dataset represents the latest known feature values as of the row’s timestamp. You should use time series feature tables whenever feature values change over time, for example with time series data, event-based data, or time-aggregated data.
When you create a time series feature table, you specify time-related columns in your primary keys to be timeseries columns using the timeseries_columns argument (for Feature Engineering in Unity Catalog) or the timestamp_keys argument (for Workspace Feature Store). This enables point-in-time lookups when you use create_training_set or score_batch. The system performs an as-of timestamp join, using the timestamp_lookup_key you specify.
If you do not use the timeseries_columns argument or the timestamp_keys argument, and only designate a timeseries column as a primary key column, Feature Store does not apply point-in-time logic to the timeseries column during joins. Instead, it matches only rows with an exact time match instead of matching all rows prior to the timestamp.
Offline store
The offline feature store is used for feature discovery, model training, and batch inference. It contains feature tables materialized as Delta tables.
Streaming
In addition to batch writes, Databricks Feature Store supports streaming. You can write feature values to a feature table from a streaming source, and feature computation code can utilize Structured Streaming to transform raw data streams into features.
Model packaging
When you train a machine learning model using Feature Engineering in Unity Catalog or Workspace Feature Store and log it using the client’s log_model() method, the model retains references to these features. At inference time, the model can optionally retrieve feature values automatically. The caller only needs to provide the primary key of the features used in the model (for example, user_id), and the model retrieves all required feature values.
In batch inference, feature values are retrieved from the offline store and joined with new data prior to scoring. In real-time inference, feature values are retrieved from the online store.
To package a model with feature metadata, use FeatureEngineeringClient.log_model (for Feature Engineering in Unity Catalog) or FeatureStoreClient.log_model (for Workspace Feature Store).