概念
このセクションでは、 Databricksで特徴量テーブルを使用するのに役立つ概念について説明します。
Feature Store
特徴ストアは、 data scientists 特徴を見つけて共有できるようにする一元化されたリポジトリであり、特徴値をコンピュートするために使用されるのと同じコードがモデル トレーニングと推論に使用されるようにします。 Databricks での機能ストアの実装は、ワークスペースが Unity Catalog に対して有効になっているかどうかによって異なります。 Unity Catalogが有効になっているワークスペースでは、任意のDeltaテーブルが特徴量テーブルとして機能し、Unity Catalogが特徴ストアとして機能するため、テーブルを特徴量テーブルとして登録するために別の手順は必要ありません。ワークスペースが有効になっていない 2024 年 8 月 19 日 4:00:00 PM (UTC) より前に作成された Unity Catalog は、従来の ワークスペース Feature Store にアクセスできます。
機械学習では既存のデータを使用してモデルを構築し、将来の結果を予測します。生データを使用してモデルを構築するには、ほぼすべてのケースで、生データの前処理と変換が必要になります。このプロセスは特徴量エンジニアリングと呼ばれ、このプロセスの結果は、モデルのビルディングブロックとして特徴量と呼ばれます。
特徴量の開発は複雑で時間がかかります。 さらに複雑なのは、機械学習の場合、モデルのトレーニングのために特徴計算を行う必要があり、その後、モデルを使用して予測を行うときに再度計算を行う必要があることです。 これらの実装は、同じチームによって、または同じコード環境を使用して行われない場合があり、遅延やエラーにつながる可能性があります。 また、組織内の異なるチームは、多くの場合、同様の特徴量のニーズを持っていますが、他のチームが行った作業を認識していない可能性があります。 特徴量ストアはこれらの問題に対処するために設計されています。
特徴量テーブル
特徴量テーブルは特徴量テーブルとして整理されています。 各テーブルには主キーが必要であり、 Delta テーブル と追加のメタデータによってサポートされます。 特徴量テーブル メタデータは、テーブルの生成元のデータ データと、テーブルを作成または書き込んだノートブックとジョブを追跡します。
Databricks Runtime13.3LTS 以降では、ワークスペースでUnity Catalog DeltaUnity Catalogが有効になっている場合、主キーを特徴量テーブルとして の任意の テーブルを使用できます。Unity Catalogの 特徴量テーブルの操作 を参照してください。ローカルのワークスペース Feature Store に保存されている特徴量テーブルは「ワークスペース 特徴量テーブル」と呼ばれます。 「Work with 特徴量テーブル」のワークスペース Feature Store (legacy) を参照してください。
特徴量テーブルの特徴量は通常、一般的な計算関数を使用して計算、更新されます。
FeatureLookup
多くの異なるモデルが特定の特徴量テーブルの特徴量テーブルを使用する可能性があり、すべてのモデルがすべての特徴量テーブルを必要とするわけではありません。 特徴量テーブルごとに FeatureLookup をトレーニングするには、特徴量テーブルごとにモデルをトレーニングします。 この FeatureLookup は、テーブルから使用するフィーチャを指定し、 create_training_setに渡されるラベル データに特徴量テーブルを結合するために使用するキーも定義します。
この図は、 FeatureLookup がどのように機能するかを示しています。 この例では、 customer_features と product_featuresという 2 つの特徴量テーブル の特徴量を使用してモデルをトレーニングします。 特徴量テーブルごとに FeatureLookup を作成し、テーブルの名前、テーブルから選択する特徴量 (列)、および特徴を結合してトレーニングデータセットを作成するときに使用するルックアップキーを指定します。
次に、図に示されている create_training_setを呼び出します。 この API 呼び出しは、生のトレーニング データ (label_df) を含む DataFrame 、使用する FeatureLookups 、グラウンド トゥルースを含む列 labelを指定します。 トレーニングデータには、特徴量テーブルの各主キーに対応する列が含まれている必要があります。 特徴量テーブルのデータは、これらのキーに従って入力 DataFrame に結合されます。 結果は、図に「トレーニングデータセット」として表示されます。
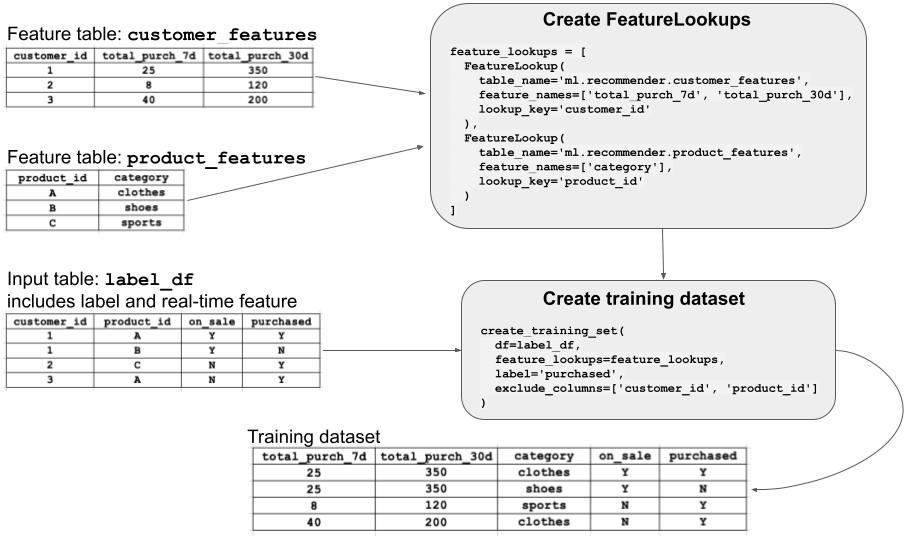
トレーニングセット
トレーニング セットは、特徴のリストと、特徴を検索するための生のトレーニング データ、ラベル、および主キーを含む DataFrame で構成されます。 Feature Store から抽出する特徴を指定してトレーニング セットを作成し、モデルのトレーニング中にトレーニング セットを入力として提供します。
トレーニングセットを作成して使用する方法の例については、「 トレーニングデータセットの作成 」を参照してください。
Unity Catalogで特徴量エンジニアリングを使用してモデルをトレーニングしてログに記録すると、Catalog Explorer でモデルのリネージを表示できます。 モデルの作成に使用されたテーブルと関数は自動的に追跡され、表示されます。 特徴量のガバナンスのリネージを参照してください。
時系列特徴量テーブル(時点検索)
モデルのトレーニングに使用されるデータには、多くの場合、時間の依存関係が組み込まれています。 モデルを構築するときは、観測されたターゲット値の時点までの特徴値のみを考慮する必要があります。 ターゲット値のタイムスタンプ以降に測定されたデータに基づいて特徴をトレーニングすると、モデルのパフォーマンスが低下する可能性があります。
時系列特徴量テーブル には、トレーニングデータセットの各行が行のタイムスタンプの時点で最新の既知の特徴値を表すことを保証するタイムスタンプ列が含まれています。 時系列特徴量テーブルは、時系列データ、イベントベースのデータ、時間集計データなど、時間の経過と共に特徴値が変化するたびに使用する必要があります。
時系列特徴量テーブルを作成するときは、主キーの時間関連列を時系列列として指定するには、引数 timeseries_columns ( Unity Catalogでの特徴量エンジニアリングの場合) または timestamp_keys 引数 (ワークスペース Feature Storeの場合) を使用します。 これにより、 create_training_set または score_batchを使用するときにポイントインタイムルックアップが可能になります。 システムは、指定された timestamp_lookup_key を使用して、タイムスタンプ時結合を実行します。
timeseries_columns 引数または timestamp_keys 引数を使用せず、時系列列のみを主キー列として指定した場合、Feature Store は結合中に時系列列に特定の時点のロジックを適用しません。代わりに、タイムスタンプより前のすべての行を照合するのではなく、時刻が完全に一致する行のみを照合します。
オフラインストア
オフラインの特徴量ストアは、特徴量の検出、モデルのトレーニング、およびバッチ推論に使用されます。 これには、Deltaテーブルとしてマテリアライズされた特徴量テーブルが含まれています。
ストリーミング
バッチ書き込みに加えて、Databricks Feature Storeでは ストリーミングもサポートされています。 ストリーミング ソースから特徴量テーブルに特徴値を書き込むことができ、特徴量計算コードでは 構造化ストリーミング を利用して生データ ストリームを特徴量に変換できます。
モデルのパッケージ化
Unity Catalog Feature Storeを使用して機械学習モデルをトレーニングし、クライアントの log_model() メソッドを使用してログに記録すると、モデルはこれらの特徴量への参照を保持します。 推論時に、モデルはオプションで特徴量の値を自動的に取得できます。 呼び出し元は、モデルで使用される特徴量の主キー ( user_idなど) を指定するだけでよく、モデルは必要なすべての特徴量の値を取得します。
バッチ推論では、特徴値はオフライン ストアから取得され、スコアリングの前に新しいデータと結合されます。 リアルタイム推論では、特徴値はオンラインストアから取得されます。
フィーチャー メタデータを使用してモデルをパッケージ化するには、FeatureEngineeringClient.log_model ( Unity Catalogでの特徴量エンジニアリングの場合) または FeatureStoreClient.log_model (ワークスペース Feature Storeの場合) を使用します。