Unity Catalog で特徴量テーブルを使用する
このページでは、 Unity Catalogで特徴量テーブルを作成および操作する方法について説明します。
このページは、Unity Catalog が有効になっているワークスペースにのみ適用されます。 ワークスペースで Unity Catalogが有効になっていない場合は、「 ワークスペース Feature Store (legacy) で特徴量テーブルを操作する」を参照してください。
このページの例で使用されているコマンドと引数の詳細については、 Feature エンジニアリングPython APIリファレンスを参照してください。
Unity CatalogのFeature Engineeringをインストールする
Unity Catalog の特徴量エンジニアリングにはPythonクライアント FeatureEngineeringClient があります。 このクラスは、 databricks-feature-engineeringパッケージとともに PyPI で使用可能であり、Databricks Runtime 13.3 LTS ML 以上にプリインストールされています。 ML 以外の Databricks Runtime を使用する場合は、クライアントを手動でインストールする必要があります。 互換性マトリックスを使用して、Databricks Runtime バージョンに適したバージョンを見つけます。
%pip install databricks-feature-engineering
dbutils.library.restartPython()
Unity Catalogで特徴量テーブルのカタログとスキーマを作成する
特徴量テーブルには新しいカタログを作成するか、既存のカタログを使用する必要があります。
新しいカタログを作成するには、メタストアに対するCREATE CATALOG特権が必要です。
CREATE CATALOG IF NOT EXISTS <catalog-name>
既存のカタログを使用するには、カタログに対する USE CATALOG 特権が必要です。
USE CATALOG <catalog-name>
Unity Catalog内の特徴テーブルはスキーマに保存する必要があります。 カタログに新しいスキーマを作成するには、カタログに対する CREATE SCHEMA 特権が必要です。
CREATE SCHEMA IF NOT EXISTS <schema-name>
Unity Catalogで特徴量テーブルを作成する
注
Unity Catalog主キー制約を含む既存のDeltaテーブルを特徴量テーブルとして使用できます。テーブルに主キーが定義されていない場合は、 ALTER TABLE DDL ステートメントを使用してテーブルを更新し、制約を追加する必要があります。 「Unity Catalog内の既存のDelta テーブルを特徴量テーブルとして使用する」 を参照してください。
ただし、Delta Live Tables パイプラインによって Unity Catalog に公開されたストリーミング テーブルまたはマテリアライズド ビューに主キーを追加するには、ストリーミング テーブルまたはマテリアライズド ビュー定義のスキーマを変更して主キーを含め、ストリーミング テーブルまたはマテリアライズド ビューを更新する必要があります。 「 Delta Live Tablesパイプラインによって作成されたストリーミング テーブルまたはマテリアライズド ビューを特徴量テーブルとして使用する」を参照してください。
Unity Catalogの特徴テーブルはDeltaテーブルです。 特徴テーブルには主キーが必要です。 特徴量テーブルは、 Unity Catalog内の他のデータ アセットと同様に、3 レベルの名前空間 <catalog-name>.<schema-name>.<table-name> を使用してアクセスされます。
Databricks SQL 、 Python FeatureEngineeringClient、またはDelta Live Tablesパイプラインを使用して、 Unity Catalogに特徴量テーブルを作成できます。
主キー制約 を持つ任意の Deltaテーブルを特徴量テーブルとして使用できます。次のコードは、主キーを持つテーブルを作成する方法を示しています。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
);
時系列特徴量テーブルを作成するには、時間列を主キー列として追加し、TIMESERIES キーワードを指定します。キーワードには 13.3 LTS 以上のDatabricks Runtime が必要です。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
);
テーブルが作成されると、他のDeltaテーブルと同様にデータを書き込むことができ、特徴量テーブルとして使用できます。
次の例で使用されるコマンドとパラメーターの詳細については、 「フィーチャー エンジニアリング Python API リファレンス」を参照してください。
Python 関数を記述して、フィーチャをコンピュートします。 各関数の出力は、一意の主キーを持つ Apache Spark DataFrame である必要があります。 主キーは、1 つ以上の列で構成できます。
特徴量テーブルを作成するには、
FeatureEngineeringClientをインスタンス化し、create_tableを使用します。write_tableを使用して特徴量テーブルを設定します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Prepare feature DataFrame
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
customer_features_df = compute_customer_features(df)
# Create feature table with `customer_id` as the primary key.
# Take schema from DataFrame output by compute_customer_features
customer_feature_table = fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fe.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite primary key, pass all primary key columns in the create_table call
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# To create a time series table, set the timeseries_columns argument
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# timeseries_columns='date',
# ...
# )
Delta Live Tablesパイプラインを使用してUnity Catalogに特徴量テーブルを作成する
注
Delta Live Tables のテーブル制約のサポートはパブリック プレビュー段階です。 次のコード例は、 Delta Live Tables プレビュー チャンネルを使用して実行する必要があります。
Delta Live Tables主キー制約 を含む パイプラインから公開されたテーブルは、特徴量テーブルとして使用できます。Delta Live Tables パイプラインに主キーを持つテーブルを作成するには、Databricks SQL またはDelta Live Tables Python プログラミング インターフェイスのいずれかを使用できます。
Delta Live Tables パイプラインに主キーを持つテーブルを作成するには、次の構文を使用します。
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
) AS SELECT * FROM ...;
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
""")
def customer_features():
return ...
時系列特徴量テーブルを作成するには、時間列を主キー列として追加し、 TIMESERIESキーワードを指定します。
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
) AS SELECT * FROM ...;
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
""")
def customer_features():
return ...
テーブルが作成されると、他のDelta Live Tablesと同様にデータを書き込むことができ、特徴量テーブルとして使用できます。
Unity Catalog 内の既存の Delta テーブルを特徴量テーブルとして使用する
Unity Catalog内の主キーを持つDeltaテーブルは、 Unity Catalog内の特徴量テーブルにすることができ、そのテーブルで特徴量UI とAPI を使用できます。
注
主キー制約を宣言できるのは、テーブルの所有者だけです。 オーナーの名前は、「カタログエクスプローラ」(Catalog Explorer) のテーブル詳細ページに表示されます。
Deltaテーブルのデータ型が Unity Catalog での特徴量エンジニアリングでサポートされていることを確認します。 「サポートされているデータ型」を参照してください。
TIMESERIES キーワードには 13.3 LTS 以上Databricks Runtimeが必要です。
既存の Delta テーブルに主キー制約がない場合は、次のように作成できます。
主キー列を
NOT NULLに設定します。 主キー列ごとに、実行:ALTER TABLE <full_table_name> ALTER COLUMN <pk_col_name> SET NOT NULL
テーブルを変更して、主キー制約を追加します。
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1, pk_col2, ...)
pk_nameは、主キー制約の名前です。 慣例により、テーブル名 (スキーマとカタログなし) に_pkサフィックスを付けることができます。 たとえば、"ml.recommender_system.customer_features"という名前のテーブルは、主キー制約の名前としてcustomer_features_pkになります。テーブルを 時系列特徴テーブルにするには、次のように、主キー列の 1 つに TIMESERIES キーワードを指定します。
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1 TIMESERIES, pk_col2, ...)
テーブルに主キー制約を追加すると、テーブルが機能 UI に表示され、特徴テーブルとして使用できるようになります。
Delta Live Tablesパイプラインによって作成されたストリーミング テーブルまたはマテリアライズド ビューを特徴量テーブルとして使用する
主キーを持つUnity Catalogのストリーミング テーブルまたはマテリアライズド ビューは、 Unity Catalogの特徴量テーブルにすることができ、そのテーブルで機能 UI とAPIを使用できます。
注
Delta Live Tables のテーブル制約のサポートはパブリック プレビュー段階です。 次のコード例は、 Delta Live Tables プレビュー チャンネルを使用して実行する必要があります。
主キー制約を宣言できるのは、テーブルの所有者だけです。 オーナーの名前は、「カタログエクスプローラ」(Catalog Explorer) のテーブル詳細ページに表示されます。
Unity Catalog の特徴量エンジニアリングがDeltaテーブル内のデータ型をサポートしていることを確認します。 「サポートされているデータ型」を参照してください。
既存のストリーミング テーブルまたはマテリアライズド ビューの主キーを設定するには、オブジェクトを管理するノートブック内のストリーミング テーブルまたはマテリアライズド ビューのスキーマを更新します。 次に、 テーブルを更新してUnity Catalog オブジェクトを更新します。
以下は、実体化ビュー (Materialized View) に主キーを追加する構文です。
CREATE OR REFRESH MATERIALIZED VIEW existing_live_table(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT ...
import dlt
@dlt.table(
schema="""
id int NOT NULL PRIMARY KEY,
...
"""
)
def existing_live_table():
return ...
Unity Catalogの既存のビューを特徴量テーブルとして使用する
ビューを特徴量テーブルとして使用するには、 Databricks Runtime 16.0 MLに組み込まれている 0.7.0 以降のバージョンを使用する必要がありますdatabricks-feature-engineering。
Unity Catalog の単純な SELECT ビューは、 Unity Catalogの特徴量テーブルになることができ、テーブルで Features API を使用できます。
注
単純な SELECT ビューは、特徴量テーブルとして使用でき、プライマリ・キーが JOIN、グループ BY、または DISTINCT 句なしで選択されている 内の 1 つの ・テーブルから作成されたビューとして定義されます。DeltaUnity CatalogSQL 文で使用できるキーワードは、SELECT、FROM、WHERE、ORDER BY、LIMIT、および OFFSET です。
サポートされているデータ型については、 サポートされているデータ型 を参照してください。
ビューに裏打ちされた特徴量テーブルは、フィーチャー UI に表示されません。
ソース Delta テーブルで列の名前を変更する場合は、ビュー定義の SELECT ステートメントの列の名前を一致させる必要があります。
以下は、特徴量テーブルとして使用できる単純な SELECT ビューの例です。
CREATE OR REPLACE VIEW ml.recommender_system.content_recommendation_subset AS
SELECT
user_id,
content_id,
user_age,
user_gender,
content_genre,
content_release_year,
user_content_watch_duration,
user_content_like_dislike_ratio
FROM
ml.recommender_system.content_recommendations_features
WHERE
user_age BETWEEN 18 AND 35
AND content_genre IN ('Drama', 'Comedy', 'Action')
AND content_release_year >= 2010
AND user_content_watch_duration > 60;
特徴量テーブル based on views は、オフラインモデルのトレーニングと評価に使用できます。 オンラインストアに公開することはできません。 これらのテーブルの特徴と、これらの特徴に基づくモデルは提供できません。
Unity Catalogで特徴量テーブルを更新する
Unity Catalog で特徴量テーブルを更新するには、新しい特徴量テーブルを追加するか、主キーに基づいて特定の行を変更します。
次の特徴量テーブルのメタデータは更新しないでください。
主キー。
パーティション キー。
既存のフィーチャの名前またはデータ タイプ。
これらを変更すると、トレーニングとサービング モデルの機能を使用するダウンストリーム パイプラインが壊れます。
Unity Catalogの既存の特徴量テーブルに新しい特徴量を追加する
既存の特徴量テーブルに新しい特徴量テーブルを追加するには、次の 2 つの方法があります。
既存の特徴量計算関数を更新し、返された DataFrameで
write_tableを実行します。 これにより、特徴量テーブル スキーマが更新され、主キーに基づいて新しい特徴量テーブル値がマージされます。新しい特徴量を計算するための新しい特徴量計算関数を作成します。 この新しい計算関数によって返されるDataFrameには、特徴テーブルの主キーとパーティション キー (定義されている場合) が含まれている必要があります。 DataFrameを使用して
write_tableを実行し、同じ主キーを使用して新しい機能を既存の特徴量テーブルに書き込みます。
特徴量テーブル内の特定の行のみを更新する
write_tableで mode = "merge" を使用します。write_table 呼び出しで送信された DataFrame に主キーが存在しない行は変更されません。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.write_table(
name='ml.recommender_system.customer_features',
df = customer_features_df,
mode = 'merge'
)
特徴量テーブルを更新するジョブをスケジュールする
特徴量テーブルの特徴量テーブルに常に最新の値が含まれるようにするために、 Databricks では、ノートブックを実行して特徴量テーブルを定期的に (毎日など) 更新するジョブを作成することをお勧めします。 スケジュールされていないジョブがすでに作成されている場合は、スケジュール済みジョブに変換して、機能値が常に最新の状態になるようにすることができます。 「 ワークフローのスケジュールと調整」を参照してください。
特徴量テーブルを更新するコードでは、次の例に示すように、 mode='merge'を使用します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = compute_customer_features(data)
fe.write_table(
df=customer_features_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
日次特徴量の過去の値を保存する
複合主キーを持つ特徴量テーブルを定義します。 主キーに日付を含めます。 たとえば、特徴量テーブル customer_featuresの場合、効率的な読み取りのために複合主キー (date、 customer_id) とパーティション キー date を使用できます。
Databricks 、効率的な読み取りのために、テーブル上でリキッドクラスタリングを有効にすることをお勧めします。 リキッドクラスタリングを使用しない場合は、読み取りパフォーマンスを向上させるために、日付列をパーティション キーとして設定します。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
`date` date NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (`date`, customer_id)
)
-- If you are not using liquid clustering, uncomment the following line.
-- PARTITIONED BY (`date`)
COMMENT "Customer features";
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
# If you are not using liquid clustering, uncomment the following line.
# partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
その後、特徴量テーブルから date をフィルター処理して対象期間に読み取るコードを作成できます。
また、 時系列特徴量テーブル を作成して、 create_training_set または score_batchを使用するときに特定の時点のルックアップを有効にすることもできます。 「 Unity Catalog で特徴量テーブルを作成する」を参照してください。
特徴量テーブルを最新の状態に保つには、特徴を書き込んだり、新しい特徴値を特徴量テーブルにストリーム配信したりする定期的なジョブを設定します。
ストリーミング特徴量計算パイプラインを作成して特徴量を更新する
ストリーミング特徴量計算パイプラインを作成するには、ストリーミング DataFrame を引数として write_tableに渡します。 このメソッドは、 StreamingQuery オブジェクトを返します。
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_transactions = spark.readStream.table("prod.events.customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fe.write_table(
df=stream_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
Unity Catalogの特徴量テーブルから読み取る
read_table を使用してフィーチャ値を読み取ります。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = fe.read_table(
name='ml.recommender_system.customer_features',
)
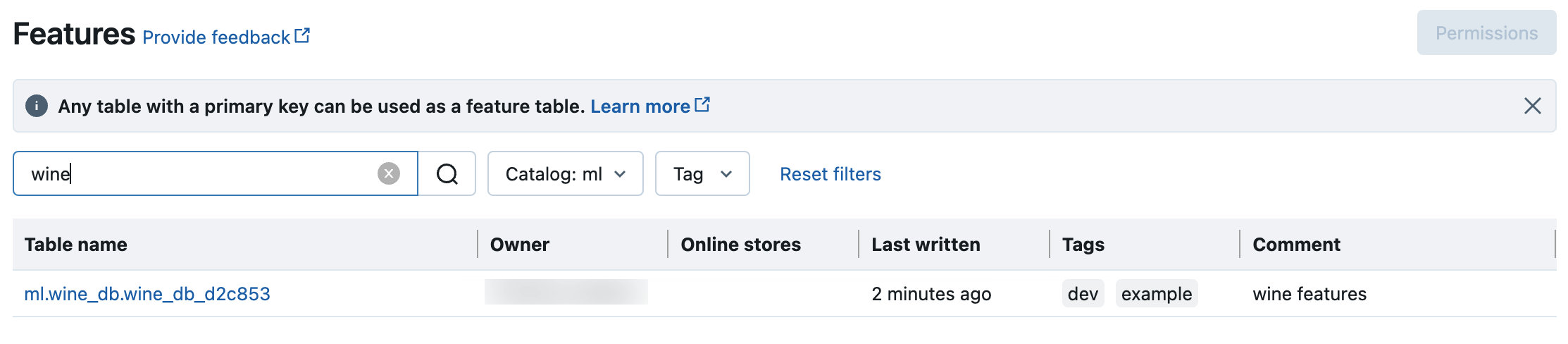
Unity Catalogの特徴量テーブルを検索および参照する
フィーチャー UI を使用して、 Unity Catalogでフィーチャー テーブルを検索または参照します。
サイドバーの [ 機能 ]
 をクリックして 、機能 UI を表示します。
をクリックして 、機能 UI を表示します。カタログセレクタでカタログを選択すると、そのカタログで使用可能なすべての特徴量テーブルが表示されます。 検索ボックスに、特徴量テーブル、機能、またはコメントの名前の全部または一部を入力します。 また、タグのキーまたは値の全部または一部を入力することもできます。検索テキストでは、大文字と小文字が区別されません。
Unity Catalogで特徴量テーブルのメタデータを取得する
get_table を使用して、特徴量テーブルのメタデータを取得します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
ft = fe.get_table(name="ml.recommender_system.user_feature_table")
print(ft.features)
Unity Catalogの特徴量テーブルや特徴量にタグを使用する
シンプルなキーと値のペアであるタグを使用して、特徴量テーブルと機能を分類して管理できます。
特徴量テーブルでは、カタログ エクスプローラー、データベースまたはSQLクエリ エディターのSQLステートメント、または Feature エンジニアリングPython APIを使用して、タグを作成、編集、および削除できます。
フィーチャの場合、カタログ エクスプローラー、ノートブック内の SQL ステートメント、または SQL クエリ エディターを使用して、タグを作成、編集、および削除できます。
「Unity Catalogセキュリティ保護可能なオブジェクトへのタグの適用」および「Feature エンジニアリングとワークスペース Feature Store Python API」を参照してください。
次の例は、Feature エンジニアリングPython API使用して特徴量テーブル タグを作成、更新、および削除する方法を示しています。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Create feature table with tags
customer_feature_table = fe.create_table(
# ...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
# ...
)
# Upsert a tag
fe.set_feature_table_tag(name="customer_feature_table", key="tag_key_1", value="new_key_value")
# Delete a tag
fe.delete_feature_table_tag(name="customer_feature_table", key="tag_key_2")
Unity Catalogで特徴量テーブルを削除する
カタログエクスプローラーまたは Feature Engineering Python API を使用してUnity CatalogのDeltaテーブルを直接削除することでUnity Catalogの特徴量テーブルを削除することができます。
注
特徴量テーブルを削除すると、上流のプロデューサーと下流のコンシューマー (モデル、エンドポイント、スケジュール済みジョブ) で予想外のエラーが発生する恐れがあります。
Unity Catalogで特徴量テーブルを削除すると、基になる Delta テーブルも削除されます。
drop_tableは、 Databricks Runtime 13.1 機械学習以前ではサポートされていません。 SQL コマンドを使用してテーブルを削除します。
Databricks SQL または FeatureEngineeringClient.drop_table を使用して、 Unity Catalogで特徴量テーブルを削除できます。
DROP TABLE ml.recommender_system.customer_features;
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.drop_table(
name='ml.recommender_system.customer_features'
)