Trabalhar com tabelas de recursos em Unity Catalog
Esta página descreve como criar e trabalhar com tabelas de recursos no Unity Catalog.
Esta página se aplica somente ao espaço de trabalho que está habilitado para Unity Catalog. Se o site workspace não estiver habilitado para Unity Catalog, consulte Trabalhar com tabelas de recurso no espaço de trabalho Recurso Store (legado).
Para obter detalhes sobre o comando e os parâmetros usados nos exemplos desta página, consulte a referência do recurso engenharia Python API .
Instale o recurso Engineering no cliente Unity Catalog Python
recurso engenharia em Unity Catalog tem um cliente Python FeatureEngineeringClient. A classe está disponível em PyPI com o pacote databricks-feature-engineering e é pré-instalada em Databricks Runtime 13.3 LTS ML e acima. Se o senhor usar um Databricks Runtime não-ML, deverá instalar o cliente manualmente. Use a matriz de compatibilidade para encontrar a versão correta para sua versão do Databricks Runtime.
%pip install databricks-feature-engineering
dbutils.library.restartPython()
Crie um catálogo e um esquema para tabelas de recursos no Unity Catalog
O senhor deve criar um novo catálogo ou usar um catálogo existente para tabelas de recurso.
Para criar um novo catálogo, o senhor deve ter o privilégio CREATE CATALOG no metastore.
CREATE CATALOG IF NOT EXISTS <catalog-name>
Para usar um catálogo existente, você deve ter o privilégio USE CATALOG no catálogo.
USE CATALOG <catalog-name>
As tabelas de recurso em Unity Catalog devem ser armazenadas em um esquema. Para criar um novo esquema no catálogo, o senhor deve ter o privilégio CREATE SCHEMA no catálogo.
CREATE SCHEMA IF NOT EXISTS <schema-name>
Crie uma tabela de recursos no Unity Catalog
Observação
O senhor pode usar uma tabela Delta existente em Unity Catalog que inclua uma restrição primária key como uma tabela de recurso. Se a tabela não tiver um key primário definido, o senhor deverá atualizar a tabela usando ALTER TABLE instruções DDL para adicionar a restrição. Consulte Usar uma tabela Delta existente em Unity Catalog como uma tabela de recurso.
No entanto, para adicionar um key primário a uma tabela de transmissão ou materializada view que foi publicada em Unity Catalog por um Delta Live Tables pipeline é necessário modificar o esquema da tabela de transmissão ou materializada view definição para incluir o key primário e, em seguida, atualizar a tabela de transmissão ou materializada view. Consulte Usar uma tabela de transmissão ou materializada view criada por uma Delta Live Tables pipeline como uma tabela de recurso.
As tabelas de recurso em Unity Catalog são tabelasDelta . As tabelas de recurso devem ter um primário key. As tabelas de recurso, como outros dados ativos em Unity Catalog, são acessadas usando um namespace de três níveis: <catalog-name>.<schema-name>.<table-name>.
O senhor pode usar Databricks SQL, o Python FeatureEngineeringClient ou um Delta Live Tables pipeline para criar tabelas de recurso em Unity Catalog.
O senhor pode usar qualquer tabela Delta com uma restrição key primária como uma tabela de recurso. O código a seguir mostra como criar uma tabela com um primário key:
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
);
Para criar uma tabela de recursos de série temporal, adicione uma coluna de tempo como uma coluna key primária e especifique a palavra-chave TIMESERIES . A palavra-chave TIMESERIES requer Databricks Runtime 13.3 LTS ou acima.
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
);
Depois que a tabela for criada, o senhor poderá gravar dados nela como em outras tabelas do site Delta, e ela poderá ser usada como uma tabela de recurso.
Para obter detalhes sobre o comando e os parâmetros usados nos exemplos a seguir, consulte a referência da API Python do recurso engenharia.
Escreva as funções do Python para compute os recursos. A saída de cada função deve ser um Apache Spark DataFrame com uma key primária exclusiva. A key primária pode consistir em uma ou mais colunas.
Crie uma tabela de recursos instanciando um
FeatureEngineeringCliente usandocreate_table.Preencha a tabela de recursos usando
write_table.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Prepare feature DataFrame
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
customer_features_df = compute_customer_features(df)
# Create feature table with `customer_id` as the primary key.
# Take schema from DataFrame output by compute_customer_features
customer_feature_table = fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fe.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite primary key, pass all primary key columns in the create_table call
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# To create a time series table, set the timeseries_columns argument
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# timeseries_columns='date',
# ...
# )
Criar uma tabela de recursos em Unity Catalog com Delta Live Tables pipeline
Observação
O suporte do Delta Live Tables para restrições de tabela está na visualização pública. Os exemplos de código a seguir devem ser executados usando o Delta Live Tables canal de visualização .
Qualquer tabela publicada a partir de uma Delta Live Tables pipeline que inclua uma restrição primária key pode ser usada como uma tabela de recurso. Para criar uma tabela em um Delta Live Tables pipeline com um key primário, o senhor pode usar o Databricks SQL ou a interface de programaçãoDelta Live Tables Python .
Para criar uma tabela em um Delta Live Tables pipeline com um key primário, use a seguinte sintaxe:
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
) AS SELECT * FROM ...;
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
""")
def customer_features():
return ...
Para criar uma tabela de recurso de série temporal, adicione uma coluna de tempo como uma coluna primária key e especifique a palavra-chave TIMESERIES.
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
) AS SELECT * FROM ...;
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
""")
def customer_features():
return ...
Depois que a tabela for criada, o senhor poderá gravar dados nela como em qualquer outro conjunto de dados Delta Live Tables, e ela poderá ser usada como uma tabela de recurso.
Use uma tabela Delta existente no Unity Catalog como uma tabela de recursos
Qualquer tabela Delta em Unity Catalog com um key primário pode ser uma tabela de recurso em Unity Catalog, e o senhor pode usar o recurso UI e API com a tabela.
Observação
Somente o proprietário da tabela pode declarar restrições primárias key. O nome do proprietário é exibido na página de detalhes da tabela do Catalog Explorer.
Verifique se o tipo de dados na tabela Delta é compatível com o recurso engenharia em Unity Catalog. Consulte Tipos de dados suportados.
A palavra-chave TIMESERIES requer Databricks Runtime 13.3 LTS ou acima.
Se uma tabela Delta existente não tiver uma restrição key primária, o senhor poderá criar uma da seguinte forma:
Defina colunas key primária como
NOT NULL. Para cada coluna key primária, execução:ALTER TABLE <full_table_name> ALTER COLUMN <pk_col_name> SET NOT NULL
Altere a tabela para adicionar a restrição primária key:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1, pk_col2, ...)
pk_nameé o nome da restrição primária key. Por convenção, o senhor pode usar o nome da tabela (sem esquema e catálogo) com um sufixo_pk. Por exemplo, uma tabela com o nome"ml.recommender_system.customer_features"teriacustomer_features_pkcomo o nome de sua restrição primária key.Para tornar a tabela uma tabela de recursos de série temporal, especifique a palavra key TIMESERIES em uma das colunas key primária, como segue:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1 TIMESERIES, pk_col2, ...)
Depois de adicionar a restrição primária key à tabela, ela aparecerá na UI de recurso e o senhor poderá usá-la como uma tabela de recurso.
Usar uma tabela de transmissão ou materializada view criada por uma Delta Live Tables pipeline como uma tabela de recurso
Qualquer tabela de transmissão ou materializada view em Unity Catalog com um key primário pode ser uma tabela de recurso em Unity Catalog, e o senhor pode usar a UI de recurso e API com a tabela.
Observação
O suporte do Delta Live Tables para restrições de tabela está na visualização pública. Os exemplos de código a seguir devem ser executados usando o Delta Live Tables canal de visualização .
Somente o proprietário da tabela pode declarar restrições primárias key. O nome do proprietário é exibido na página de detalhes da tabela do Catalog Explorer.
Verifique se o recurso engenharia em Unity Catalog suporta o tipo de dados na tabela Delta. Consulte Tipos de dados suportados.
Para definir a chave primária de uma tabela de transmissão existente ou materializada view, atualize o esquema da tabela de transmissão ou materializada view no site Notebook que gerencia o objeto. Em seguida, atualize a tabela para atualizar o objeto do Unity Catalog.
A seguir, a sintaxe para adicionar um key primário a um view materializado:
CREATE OR REFRESH MATERIALIZED VIEW existing_live_table(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT ...
import dlt
@dlt.table(
schema="""
id int NOT NULL PRIMARY KEY,
...
"""
)
def existing_live_table():
return ...
Usar uma view existente em Unity Catalog como uma tabela de recurso
Para usar o view como uma tabela de recurso, o senhor deve usar a versão 0.7.0 do databricks-feature-engineering ou o acima, que está integrado ao Databricks Runtime 16.0 ML.
Um simples SELECT view em Unity Catalog pode ser uma tabela de recurso em Unity Catalog, e o senhor pode usar o recurso API com a tabela.
Observação
Um SELECT view simples é definido como um view criado a partir de uma única tabela Delta em Unity Catalog que pode ser usada como uma tabela de recurso e cuja chave primária é selecionada sem cláusulas join, GROUP BY ou DISTINCT. As palavras-chave aceitáveis na instrução SQL são SELECT, FROM, WHERE, ORDER BY, LIMIT e OFFSET.
Consulte Tipos de dados compatíveis para ver os tipos de dados compatíveis.
As tabelas de recurso apoiadas pela visualização não aparecem na UI de recurso.
Se as colunas forem renomeadas na tabela Delta de origem, as colunas na instrução SELECT da definição view deverão ser renomeadas para corresponder.
Aqui está um exemplo de um SELECT view simples que pode ser usado como uma tabela de recurso:
CREATE OR REPLACE VIEW ml.recommender_system.content_recommendation_subset AS
SELECT
user_id,
content_id,
user_age,
user_gender,
content_genre,
content_release_year,
user_content_watch_duration,
user_content_like_dislike_ratio
FROM
ml.recommender_system.content_recommendations_features
WHERE
user_age BETWEEN 18 AND 35
AND content_genre IN ('Drama', 'Comedy', 'Action')
AND content_release_year >= 2010
AND user_content_watch_duration > 60;
As tabelas de recursos baseadas na visualização podem ser usadas para treinamento e avaliação de modelos off-line. Eles não podem ser publicados em lojas on-line. O senhor não pode usar os recursos dessas tabelas e modelos baseados nesses recursos.
Atualize uma tabela de recursos no Unity Catalog
Você pode atualizar uma tabela de recursos no Unity Catalog adicionando novos recursos ou modificando linhas específicas com base na key primária.
Os seguintes metadados da tabela de recursos não devem ser atualizados:
key primária.
key de partição.
Nome ou tipo de dados de um recurso existente.
Alterá-los fará com que os pipelines downstream que usam recursos para modelos de treinamento e veiculação sejam interrompidos.
Adicionar novos recursos a uma tabela de recursos existente no Unity Catalog
Você pode adicionar novos recursos a uma tabela de recursos existente de duas maneiras:
Atualize a função de computação de recurso existente e a execução
write_tablecom o DataFrame retornado. Isso atualiza o esquema da tabela de recursos e merge novos valores de recursos com base na key primária.Crie uma nova função de computação de recurso para calcular os novos valores de recurso. O DataFrame retornado por essa nova função de computação deve conter a chave primária e de partição das tabelas de recurso (se definidas). execução
write_tablecom o DataFrame para gravar o novo recurso na tabela de recursos existente usando o mesmo primário key.
Atualize apenas linhas específicas em uma tabela de recursos
Use mode = "merge" em write_table. As linhas cuja key primária não existe no DataFrame enviado na chamada write_table permanecem inalteradas.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.write_table(
name='ml.recommender_system.customer_features',
df = customer_features_df,
mode = 'merge'
)
programar um Job para atualizar uma tabela de características
Para garantir que as tabelas de recursos tenham sempre os valores mais recentes, o site Databricks recomenda que o senhor crie um trabalho que execute um Notebook para atualizar a tabela de recursos regularmente, por exemplo, todos os dias. Se o senhor já tiver criado um trabalho não programado, poderá convertê-lo em um trabalho programado para garantir que os valores de recurso estejam sempre atualizados. Veja programar e orquestrar fluxo de trabalho.
O código para atualizar uma tabela de recursos usa mode='merge', conforme mostrado no exemplo a seguir.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = compute_customer_features(data)
fe.write_table(
df=customer_features_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
Armazenar valores anteriores de recursos diários
Defina uma tabela de recursos com uma key primária composta. Inclua a data na key primária. Por exemplo, para uma tabela de recursos customer_features, você pode usar uma key primária composta (date, customer_id) e key de partição date para leituras eficientes.
A Databricks recomenda que o senhor ative o clustering líquido na tabela para obter leituras eficientes. Se o senhor não usar o clustering líquido, defina a coluna de data como uma partição key para obter um melhor desempenho de leitura.
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
`date` date NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (`date`, customer_id)
)
-- If you are not using liquid clustering, uncomment the following line.
-- PARTITIONED BY (`date`)
COMMENT "Customer features";
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
# If you are not using liquid clustering, uncomment the following line.
# partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
Você pode então criar um código para ler da tabela de recursos filtrando date para o período de interesse.
Você também pode criar uma tabela de recursos de série temporal que permite pesquisas pontuais quando você usa create_training_set ou score_batch. Consulte Criar uma tabela de recursos no Unity Catalog.
Para manter a tabela de recursos atualizada, configure um horário regular em Job para gravar recursos ou transmitir novos valores de recursos para a tabela de recursos.
Crie um pipeline de computação de recursos transmitidos para atualizar os recursos
Para criar um pipeline de computação de recurso de transmissão, passe um DataFrame de transmissão como um argumento para write_table. Este método retorna um objeto StreamingQuery .
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_transactions = spark.readStream.table("prod.events.customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fe.write_table(
df=stream_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
Leia a partir de uma tabela de recursos no Unity Catalog
Use read_table para ler os valores do recurso.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = fe.read_table(
name='ml.recommender_system.customer_features',
)
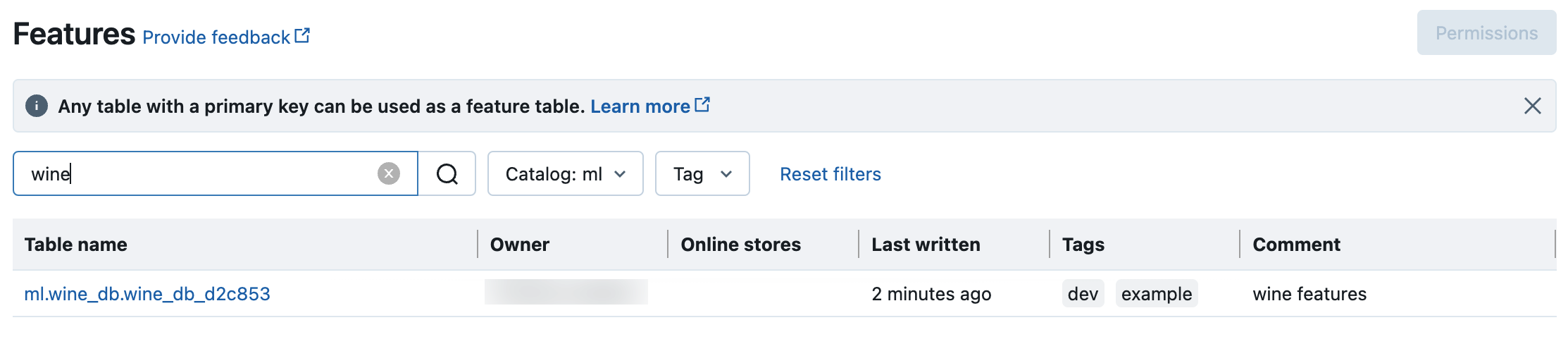
Pesquise e navegue nas tabelas de recursos no Unity Catalog
Use a interface do usuário de recursos para pesquisar ou navegar nas tabelas de recursos no Unity Catalog.
Clique
 recurso na barra lateral para exibir a UI do recurso.
recurso na barra lateral para exibir a UI do recurso.Selecione catálogo com o seletor de catálogo para view todas as tabelas de recursos disponíveis nesse catálogo. Na caixa de pesquisa, insira todo ou parte do nome de uma tabela de recursos, um recurso ou um comentário. Você também pode inserir toda ou parte da key ou valor de uma tag. O texto de pesquisa não diferencia maiúsculas de minúsculas.
Obtenha metadados de tabelas de recursos no Unity Catalog
Use get_table para obter os metadados da tabela de recursos.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
ft = fe.get_table(name="ml.recommender_system.user_feature_table")
print(ft.features)
Use tags com tabelas de recurso e recurso em Unity Catalog
O senhor pode usar tags, que são simples par chave-valor, para categorizar e gerenciar suas tabelas de recursos e recursos.
Para tabelas de recurso, o senhor pode criar, editar e excluir tags usando o Catalog Explorer, as instruções SQL em um editor de consultas Notebook ou SQL ou o recurso engenharia Python API.
Para recurso, o senhor pode criar, editar e excluir tags usando o Catalog Explorer ou as instruções SQL em um editor de consultas Notebook ou SQL.
Consulte Aplicar tags a Unity Catalog objetos seguros e recurso engenharia e espaço de trabalho repositório de recursos Python API .
O exemplo a seguir mostra como usar o recurso engenharia Python API para criar, atualizar e excluir a tabela de recursos tags.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Create feature table with tags
customer_feature_table = fe.create_table(
# ...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
# ...
)
# Upsert a tag
fe.set_feature_table_tag(name="customer_feature_table", key="tag_key_1", value="new_key_value")
# Delete a tag
fe.delete_feature_table_tag(name="customer_feature_table", key="tag_key_2")
Excluir uma tabela de recursos no Unity Catalog
O senhor pode excluir uma tabela de recurso em Unity Catalog excluindo diretamente a tabela Delta em Unity Catalog usando o Catalog Explorer ou usando o recurso engenharia Python API .
Observação
A exclusão de uma tabela de recursos pode levar a falhas inesperadas em produtores upstream e consumidores downstream (modelos, endpoint e Job agendado).
Quando você exclui uma tabela de recursos no Unity Catalog, a tabela Delta subjacente também é descartada.
drop_tablenão tem suporte no Databricks Runtime 13.1 ML ou abaixo. Use o comando SQL para excluir a tabela.
Você pode usar Databricks SQL ou FeatureEngineeringClient.drop_table para excluir uma tabela de recursos no Unity Catalog:
DROP TABLE ml.recommender_system.customer_features;
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.drop_table(
name='ml.recommender_system.customer_features'
)