Work with 特徴量テーブル in ワークスペース Feature Store (legacy)
注
このドキュメントでは、ワークスペースFeature Storeについて説明します。 Databricks では Unity CatalogのFeature Engineeringの使用を推奨しています。 ワークスペース Feature Storeは将来廃止される予定です。
Unity Catalogでの特徴量テーブルの操作に関する情報については、Unity Catalogでの特徴量テーブルの操作 を参照してください。
このページでは、ワークスペース Feature Storeで特徴量テーブルを作成して操作する方法について説明します。
注
ワークスペースで Unity Catalogが有効になっている場合、 Unity Catalog によって管理されるプライマリキーを持つテーブルは、自動的にモデル トレーニングと推論に使用できる特徴量テーブルになります。 セキュリティ、タグ付け、ワークスペース間のアクセスなど、すべての Unity Catalog 機能は、特徴量テーブルで自動的に使用可能になります。 Unity Catalog対応ワークスペースでの特徴量テーブルの操作については、「Unity Catalogでの特徴量テーブルの操作」を参照してください。
特徴量のリネージと鮮度の追跡に関する情報については、 ワークスペース Feature Store (legacy) の「機能の検出」と「特徴量のリネージの追跡」を参照してください。
注
データベース名と特徴量テーブル名に使用できるのは、英数字とアンダースコア (_) のみです。
特徴量テーブルのデータベースを作成する
特徴量テーブルを作成する前に、特徴量テーブルを格納するデータベースを作成する必要があります。
%sql CREATE DATABASE IF NOT EXISTS <database-name>
特徴量テーブルは Delta テーブルとして格納されます。 create_table (Feature Store クライアント v0.3.6 以降) または create_feature_table (v0.3.5 以下) で特徴量テーブルを作成する場合は、データベース名を指定する必要があります。 たとえば、次の引数は、データベース recommender_systemに customer_features という名前の Delta テーブルを作成します。
name='recommender_system.customer_features'
Databricks Feature Storeで特徴量テーブルを作成する
注
また、既存の Delta テーブル を特徴量テーブルとして登録することもできます。 「 既存の Delta テーブルを特徴量テーブルとして登録する」を参照してください。
特徴テーブルを作成するための基本的な手順は次のとおりです。
Python 関数を記述して、フィーチャをコンピュートします。 各関数の出力は、一意の主キーを持つ Apache Spark DataFrame である必要があります。 主キーは、1 つ以上の列で構成できます。
FeatureStoreClientをインスタンス化し、create_table(v0.3.6 以降) またはcreate_feature_table(v0.3.5 以下) を使用して特徴量テーブルを作成します。write_tableを使用して特徴量テーブルを設定します。
次の例で使用されるコマンドとパラメーターの詳細については、「 Feature Store Python API リファレンス」を参照してください。
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
既存の Delta テーブルを特徴量テーブルとして登録する
v0.3.8 以降では、既存の Delta テーブルを特徴量テーブル テーブル として登録できます。 Delta テーブルはメタストアに存在する必要があります。
注
登録済みの特徴量テーブルを更新するには、Feature Store Python API を使用する必要があります。
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
特徴量テーブルへのアクセスを制御する
「ワークスペース Feature Store (legacy)」の「特徴量テーブルへのアクセスを制御する」を参照してください。
特徴量テーブルを更新する
特徴量テーブルを更新するには、新しい特徴量テーブルを追加するか、主キーに基づいて特定の行を変更します。
次の特徴量テーブルのメタデータは更新できません。
プライマリーキー
パーティション キー
既存のフィーチャの名前またはタイプ
既存の特徴量テーブルへの新しい特徴量の追加
既存の特徴量テーブルに新しい特徴量を追加するには、次の 2 つの方法があります。
既存の特徴量計算関数を更新し、返された DataFrameで
write_tableを実行します。 これにより、特徴量テーブル スキーマが更新され、主キーに基づいて新しい特徴量テーブル値がマージされます。新しい特徴量計算関数を作成して、新しい特徴量を計算します。 この新しい計算関数によって返される DataFrame には、特徴量テーブルの主キーとパーティション キー (定義されている場合) が含まれている必要があります。 実行
write_tableDataFrame を使用して、同じ主キーを使用して、新しい特徴量テーブルを既存の特徴量テーブルに書き込みます。
特徴量テーブル内の特定の行のみを更新する
write_tableで mode = "merge" を使用します。write_table 呼び出しで送信された DataFrame に主キーが存在しない行は変更されません。
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
特徴量テーブルを更新するジョブをスケジュールする
特徴量テーブルの特徴量テーブルに常に最新の値が含まれるようにするために、 Databricks では、ノートブックを実行して特徴量テーブルを定期的に (毎日など) 更新するジョブを作成することをお勧めします。 スケジュールされていないジョブがすでに作成されている場合は、スケジュール済みジョブに変換して、機能値が常に最新の状態であることを確認できます。 「 ワークフローのスケジュールと調整」を参照してください。
特徴量テーブルを更新するコードでは、次の例に示すように、 mode='merge'を使用します。
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
日次特徴量の過去の値を保存する
複合主キーを持つ特徴量テーブルを定義します。 主キーに日付を含めます。 たとえば、特徴量テーブル store_purchasesの場合、効率的な読み取りのために複合主キー (date、 user_id) とパーティション キー date を使用できます。
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
その後、特徴量テーブルから date をフィルター処理して対象期間に読み取るコードを作成できます。
timestamp_keys 引数を使用して date 列をタイムスタンプ キーとして指定することで、 時系列特徴量テーブル を作成することもできます。
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
これにより、 create_training_set または score_batchを使用するときにポイントインタイムルックアップが可能になります。 システムは、指定された timestamp_lookup_key を使用して、タイムスタンプ時結合を実行します。
特徴テーブルを最新の状態に保つには、定期的にスケジュールされたジョブを設定して特徴を書き込むか、新しい特徴値を特徴テーブルにストリームします。
ストリーミング特徴量計算パイプラインを作成して特徴量を更新する
ストリーミング特徴量計算パイプラインを作成するには、ストリーミング DataFrame を引数として write_tableに渡します。 このメソッドは、 StreamingQuery オブジェクトを返します。
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
特徴量テーブルからの読み取り
read_table を使用してフィーチャ値を読み取ります。
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
特徴量テーブルの検索と参照
Feature Store UI を使用して、特徴量テーブルを検索または参照します。
サイドバーで、 [ 機械学習> Feature Store ] を選択して Feature Store UI を表示します。
検索ボックスに、特徴量テーブル、特徴量、特徴量計算に使用するデータソースの名前の全部または一部を入力します。 また、タグのキーまたは値の全部または一部を入力することもできます。検索テキストでは、大文字と小文字が区別されません。

特徴量テーブルのメタデータを取得する
特徴量テーブルのメタデータを取得する API は、使用している Databricks ランタイムのバージョンによって異なります。 v0.3.6 以降では、 get_tableを使用します。 v0.3.5 以前では、 get_feature_tableを使用します。
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
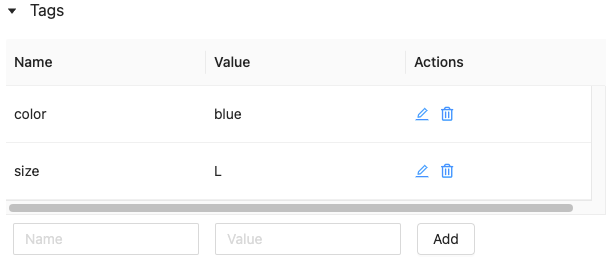
特徴量テーブルのタグの操作
タグは、 特徴量テーブルの検索に作成して使用できるキーと値のペアです。 タグの作成、編集、削除は、Feature Store UI または Feature Store Python API を使用して行うことができます。
UIで特徴量テーブルのタグを操作する
Feature Store UI を使用して、特徴量テーブルを検索または参照します。UI にアクセスするには、サイドバーで [機械学習] > Feature Storeを選択します。
 します。 タグ テーブルが表示されます。
します。 タグ テーブルが表示されます。
Feature Store Python APIを使用した特徴量テーブルのタグの操作
v0.4.1以降を実行しているクラスターでは、 Feature Store Python APIを使用してタグを作成、編集、削除できます。
特徴量テーブルのデータソースを更新する
Feature Store は、コンピュート機能に使用されるデータソースを自動的に追跡します。 Feature Store Python API を使用して、データソースを手動で更新することもできます。
Feature Store Python APIを使用したデータソースの追加
コマンドの例を次に示します。 詳細については、 API ドキュメントを参照してください。
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
Feature Store Python APIを使用してデータソースを削除する
詳細については、 API ドキュメントを参照してください。
注
次のコマンド は、ソース名に一致するすべての型 ("table"、"path"、および "custom") のデータソースを削除します。
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
特徴量テーブルを削除する
特徴量テーブルを削除するには、 Feature Store UI または Feature Store Python API を使用します。
注
特徴量テーブルを削除すると、上流のプロデューサーと下流のコンシューマー (モデル、エンドポイント、スケジュール済みジョブ) で予想外のエラーが発生する恐れがあります。
API を使用して特徴量テーブルを削除すると、基になる Delta テーブルも削除されます。 UI から特徴量テーブルを削除する場合は、基になる Delta テーブルを個別に削除する必要があります。
UIを使用した特徴量テーブルの削除
特徴量テーブルページで、 をクリックします。
 特徴量テーブル名の右側にある をクリックし、 [削除]を選択します。 特徴量テーブルに対する CAN MANAGE 権限がない場合、このオプションは表示されません。
特徴量テーブル名の右側にある をクリックし、 [削除]を選択します。 特徴量テーブルに対する CAN MANAGE 権限がない場合、このオプションは表示されません。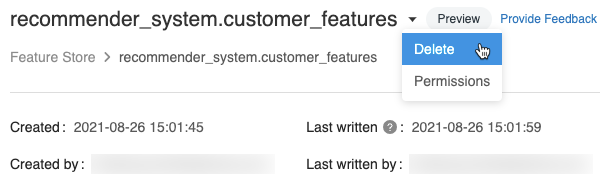
[フィーチャ テーブルの削除]ダイアログで、[ 削除 ]をクリックして確定します。
基になる Delta テーブルも削除する場合は、ノートブックで次のコマンドを実行します。
%sql DROP TABLE IF EXISTS <feature-table-name>;