Provisioned throughput Foundation Model APIs
Preview
This feature is in Public Preview and is supported in us-east1 and us-central1.
This article demonstrates how to deploy models using Foundation Model APIs provisioned throughput. Databricks recommends provisioned throughput for production workloads, and it provides optimized inference for foundation models with performance guarantees.
What is provisioned throughput?
Provisioned throughput refers to how many tokens worth of requests you can submit to an endpoint at the same time. Provisioned throughput serving endpoints are dedicated endpoints that are configured in terms of a range of tokens per second that you can send to the endpoint.
See the following resources for more information:
See Provisioned throughput Foundation Model APIs for a list of supported model architectures for provisioned throughput endpoints.
Requirements
See requirements. For deploying fine-tuned foundation models, see Deploy fine-tuned foundation models.
[Recommended] Deploy foundation models from Unity Catalog
Preview
This feature is in Public Preview.
Databricks recommends using the foundation models that are pre-installed in Unity Catalog. You can find these models under the catalog system in the schema ai (system.ai).
To deploy a foundation model:
Navigate to
system.aiin Catalog Explorer.Click on the name of the model to deploy.
On the model page, click the Serve this model button.
The Create serving endpoint page appears. See Create your provisioned throughput endpoint using the UI.
Deploy foundation models from Databricks Marketplace
Alternatively, you can install foundation models to Unity Catalog from Databricks Marketplace.
You can search for a model family and from the model page, you can select Get access and provide login credentials to install the model to Unity Catalog.
After the model is installed to Unity Catalog, you can create a model serving endpoint using the Serving UI.
Deploy fine-tuned foundation models
If you cannot use the models in the system.ai schema or install models from the Databricks Marketplace, you can deploy a fine-tuned foundation model by logging it to Unity Catalog. This section and the following sections show how to set up your code to log an MLflow model to Unity Catalog and create your provisioned throughput endpoint using either the UI or the REST API.
Requirements
Deploying fine-tuned foundation models is only supported by MLflow 2.11 or above. Databricks Runtime 15.0 ML and above pre-installs the compatible MLflow version.
Databricks recommends using models in Unity Catalog for faster upload and download of large models.
Define catalog, schema and model name
To deploy a fine-tuned foundation model, define the target Unity Catalog catalog, schema, and the model name of your choice.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Log your model
To enable provisioned throughput for your model endpoint, you must log your model using the MLflow transformers flavor and specify the task argument with "llm/v1/embeddings".
This argument specifies the API signature used for the model serving endpoint. Refer to the MLflow documentation for more details about the llm/v1/embeddings task and its corresponding input and output schemas.
The following is an example of how to log the model Alibaba-NLP/gte-large-en-v1.5 so that it can be served with provisioned throughput:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
After your model is logged in Unity Catalog, continue on Create your provisioned throughput endpoint using the UI to create a model serving endpoint with provisioned throughput.
Create your provisioned throughput endpoint using the UI
After the logged model is in Unity Catalog, create a provisioned throughput serving endpoint with the following steps:
Navigate to the Serving UI in your workspace.
Select Create serving endpoint.
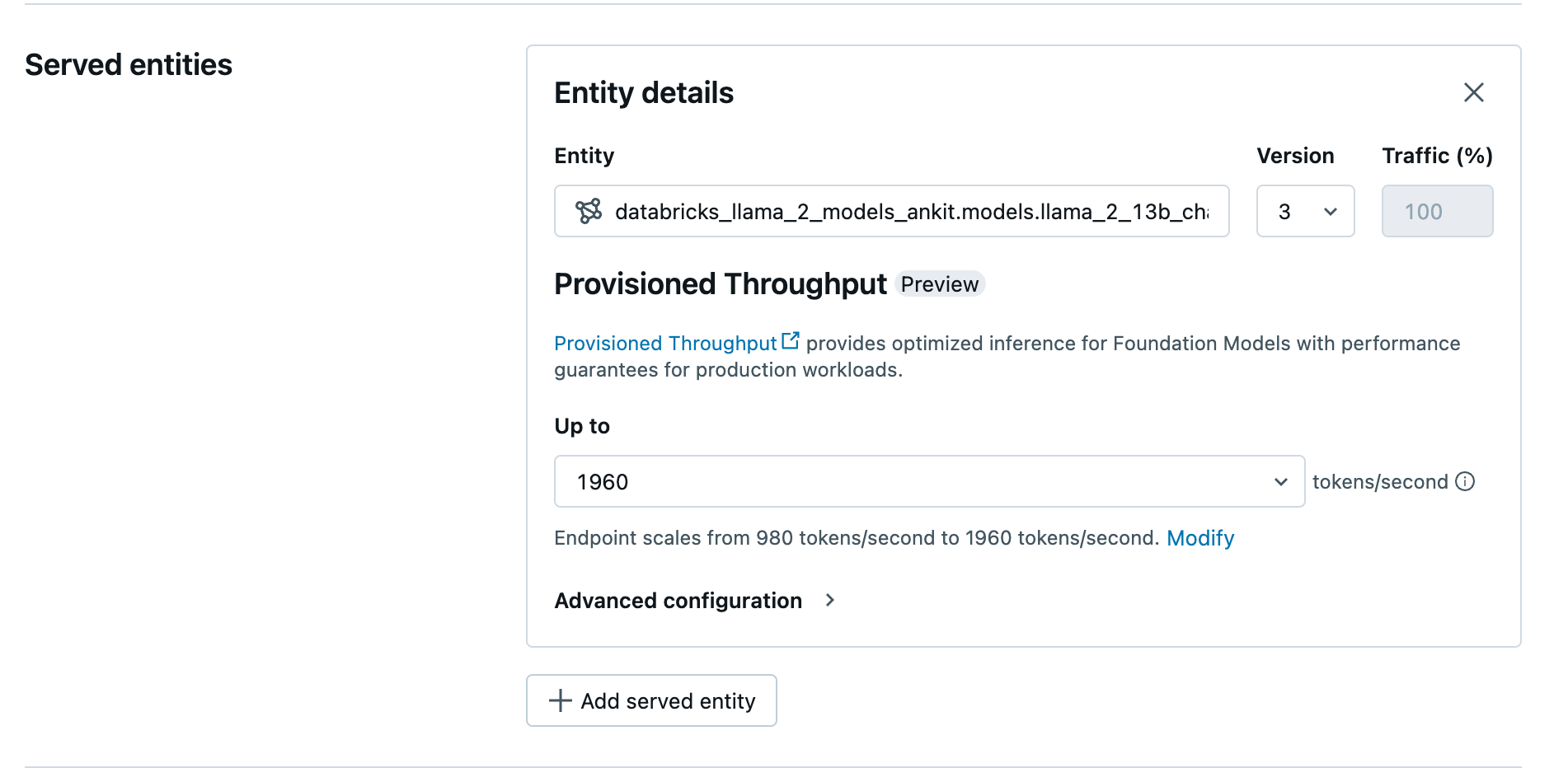
In the Entity field, select your model from Unity Catalog. For eligible models, the UI for the served entity shows the Provisioned Throughput screen.
In the Up to dropdown you can configure the maximum tokens per second throughput for your endpoint.
Provisioned throughput endpoints automatically scale, so you can select Modify to view the minimum tokens per second your endpoint can scale down to.
Create your provisioned throughput endpoint using the REST API
To deploy your model in provisioned throughput mode using the REST API, you must specify min_provisioned_throughput and max_provisioned_throughput fields in your request. If you prefer Python, you can also create an endpoint using the MLflow Deployment SDK.
To identify the suitable range of provisioned throughput for your model, see Get provisioned throughput in increments.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Get provisioned throughput in increments
Provisioned throughput is available in increments of tokens per second with specific increments varying by model. To identify the suitable range for your needs, Databricks recommends using the model optimization information API within the platform.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
The following is an example response from the API:
Notebook examples
The following notebooks show examples of how to create a provisioned throughput Foundation Model API:
Limitations
Model deployment might fail due to GPU capacity issues, which results in a timeout during endpoint creation or update. Reach out to your Databricks account team to help resolve.
Auto-scaling for Foundation Models APIs is slower than CPU model serving. Databricks recommends over-provisioning to avoid request timeouts.
Only the GTE v1.5 (English) and BGE v1.5 (English) model architectures are supported.
GTE v1.5 (English) does not generate normalized embeddings.