provisionamento throughput Foundation Model APIs
Visualização
Esse recurso está em Public Preview e é compatível com os sites us-east1 e us-central1.
Este artigo demonstra como implantar modelos usando o Foundation Model APIs provisionamento Taxa de transferência. Databricks recomenda o provisionamento de taxas de transferência para cargas de trabalho de produção e fornece inferência otimizada para modelos de fundação com garantias de desempenho.
O que é provisionamento Taxa de transferência?
provisionamento A taxa de transferência refere-se ao número de solicitações no valor de tokens que o senhor pode enviar a um endpoint ao mesmo tempo. provisionamento Taxa de transferência servindo endpoint são endpoints dedicados que são configurados em termos de um intervalo de tokens por segundo que o senhor pode enviar para o endpoint.
Consulte o recurso a seguir para obter mais informações:
Consulte provisionamento Taxa de transferência Foundation Model APIs para obter uma lista das arquiteturas de modelo compatíveis com o endpoint de provisionamento Taxa de transferência.
Requisitos
Veja os requisitos. Para modelos de fundação implantados com ajuste fino, consulte modelos de fundação implantados com ajuste fino.
[Recommended] implantado modelos de fundação de Unity Catalog
Visualização
Esse recurso está em visualização pública.
A Databricks recomenda o uso dos modelos básicos que estão pré-instalados no Unity Catalog. O senhor pode encontrar esses modelos no catálogo system no esquema ai (system.ai).
Implantar um modelo de fundação:
Navegue até
system.aino Catalog Explorer.Clique no nome do modelo a ser implantado.
Na página do modelo, clique no botão Servir este modelo.
A página Create serving endpoint é exibida. Consulte Criar seu provisionamento Taxa de transferência endpoint usando a UI.
modelos de fundação implantados a partir de Databricks Marketplace
Como alternativa, o senhor pode instalar modelos de fundação no Unity Catalog a partir de Databricks Marketplace.
O senhor pode pesquisar uma família de modelos e, na página do modelo, pode selecionar Get access (Obter acesso ) e fornecer credenciais de login para instalar o modelo no Unity Catalog.
Depois que o modelo for instalado em Unity Catalog, o senhor poderá criar um modelo de serviço endpoint usando a Serving UI.
implantou modelos de fundação ajustados
Se não for possível usar os modelos no esquema system.ai ou instalar modelos do site Databricks Marketplace, o senhor poderá implantar um modelo de base ajustado, registrando-o no site Unity Catalog. Esta seção e as seguintes mostram como configurar seu código para log um modelo MLflow para Unity Catalog e criar seu provisionamento Taxa de transferência endpoint usando a interface do usuário ou o REST API.
Requisitos
A implantação de modelos de fundação com ajuste fino é compatível apenas com o site MLflow 2.11 ou acima. Databricks Runtime 15.0 ML e o acima pré-instala a versão compatível do MLflow.
A Databricks recomenda o uso de modelos no Unity Catalog para upload e downloads mais rápidos de modelos grandes.
Definir o catálogo, o esquema e o nome do modelo
Para implantar um modelo de base bem ajustado, defina o catálogo de destino Unity Catalog, o esquema e o nome do modelo de sua escolha.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Registre seu modelo
Para habilitar o provisionamento Taxa de transferência para o seu modelo endpoint, o senhor deve log seu modelo usando a variante MLflow transformers e especificar o argumento task com "llm/v1/embeddings".
Esse argumento especifica a assinatura API usada para o modelo de serviço endpoint. Consulte a documentação do MLflow para obter mais detalhes sobre a tarefa llm/v1/embeddings e seus esquemas de entrada e saída correspondentes.
A seguir, um exemplo de como log o modelo Alibaba-NLP/gte-large-en-v1.5 para que ele possa ser servido com o provisionamento Taxa de transferência:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Depois que seu modelo for registrado em Unity Catalog, continue em Create your provisionamento Taxa de transferência endpoint usando a UI para criar um modelo de serviço endpoint com provisionamento Taxa de transferência.
Crie seu endpoint de provisionamento de taxa de transferência usando a interface do usuário
Depois que os modelos registrados estiverem no Unity Catalog, crie um endpoint de provisionamento de taxa de transferência com os seguintes passos:
Navegue até a UI de serviço em seu site workspace.
Selecione Criar endpoint de serviço.
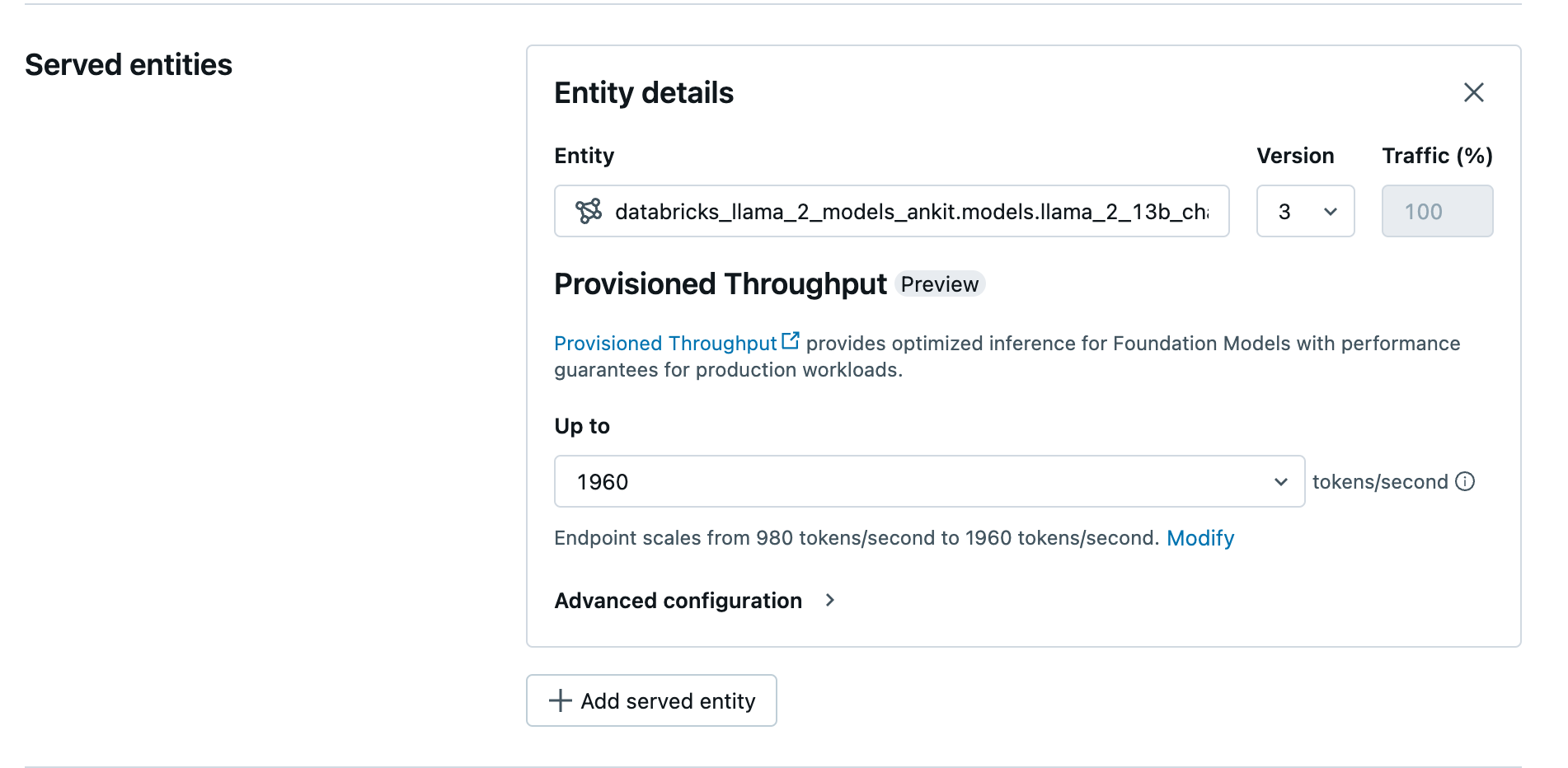
No campo Entity (Entidade ), selecione seu modelo no Unity Catalog. Para modelos qualificados, a interface do usuário da entidade atendida mostra a tela de provisionamento Taxa de transferência.
Em Up to dropdown, o senhor pode configurar a taxa máxima de transferência de tokens por segundo para o seu endpoint.
provisionamento Os pontos de extremidade da Taxa de transferência escalam automaticamente, portanto, o senhor pode selecionar Modificar para view o mínimo de tokens por segundo que seu endpoint pode escalar.
Crie seu endpoint de provisionamento da Taxa de transferência usando a API REST
Para implantar seu modelo no modo de provisionamento Taxa de transferência usando o site REST API, o senhor deve especificar os campos min_provisioned_throughput e max_provisioned_throughput em sua solicitação. Se preferir o Python, o senhor também pode criar um endpoint usando o MLflow Deployment SDK.
Para identificar a faixa adequada de provisionamento da Taxa de transferência para seu modelo, consulte Obter provisionamento da Taxa de transferência em incrementos.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Obter provisionamento Taxa de transferência em incrementos
O provisionamento Taxa de transferência está disponível em incrementos de tokens por segundo, com incrementos específicos que variam de acordo com o modelo. Para identificar o intervalo adequado às suas necessidades, a Databricks recomenda o uso da API de informações de otimização de modelos dentro da plataforma.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
A seguir, um exemplo de resposta da API:
Notebook exemplos
O Notebook a seguir mostra exemplos de como criar uma API Foundation Model de provisionamento Taxa de transferência:
Limitações
A implementação do modelo pode falhar devido a problemas de capacidade da GPU, o que resulta em um tempo limite durante a criação ou atualização do endpoint. Entre em contato com a equipe da Databricks account para ajudar a resolver o problema.
O escalonamento automático para APIs de modelos básicos é mais lento que o modelo de CPU instalado. A Databricks recomenda o provisionamento excessivo para evitar tempos limite de solicitação.
Somente as arquiteturas dos modelos GTE v1.5 (inglês) e BGE v1.5 (inglês) são suportadas.
O GTE v1.5 (inglês) não gera incorporações normalizadas.