June 2021
These features and Databricks platform improvements were released in June 2021.
Note
Releases are staged. Your Databricks account may not be updated until a week or more after the initial release date.
Change to Feature Store permissions
June 28 - July 6, 2021: Version 3.49
Users with CAN_VIEW_METADATA permission on a feature table can now publish it to online stores.
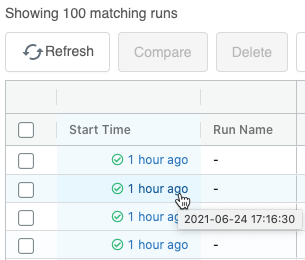
Improved access to results in the MLflow runs table
June 28 - July 6, 2021: Version 3.49
Changes to the MLflow runs table provide quicker access to results.
The Metrics columns now appear before the Parameters columns, making it easier to identify the best run.
The Start Time column now shows the age of the run, not the start time. This reduces the width of the column and allows more information to be visible without horizontal scrolling. To display the start time, hover over the value in the column.
Databricks ODBC driver 2.6.17
June 22, 2021
We have released version 2.6.17 of the Databricks ODBC driver (download). This release adds support for Cloud Fetch, which is a mechanism for fetching data in parallel through cloud storage to bring the data faster to BI tools. This release also reduces latency by removing unnecessary roundtrips between the client and the Databricks Runtime. See How We Achieved High-bandwidth Connectivity With BI Tools.
Databricks Runtime 7.5 series support ends
June 16, 2021
Support for Databricks Runtime 7.5, Databricks Runtime 7.5 for Machine Learning, and Databricks Runtime 7.5 for Genomics ended on June 16. See Databricks support lifecycles.
Registry-wide permissions for Model Registry
June 14-21, 2021: Version 3.48
You can now set default model permissions for all models in a workspace’s Model Registry. Permissions set at this level apply to all new and existing models registered in Model Registry in that workspace. For more information, see MLflow model ACLs.
A user’s home directory is no longer protected when you delete a user using the SCIM API
June 14-21, 2021: Version 3.48
When you delete a user using the SCIM API, the user’s home directory is no longer protected, and a workspace administrator can delete it. This behavior matches what happens when you delete a user using the admin console.
Store the path to a secret in a Spark configuration property
June 9, 2021
You can now store the path to a secret in a Spark configuration property. Retrieved secrets are redacted from notebook output and Spark driver and executor logs. See Manage secrets.
Databricks Runtime 8.3 and 8.3 ML are GA; 8.3 Photon is Public Preview
June 8, 2021
Databricks Runtime 8.3 and 8.3 ML are now generally available. 8.3 Photon is in Public Preview.
For information, see the full release notes at Databricks Runtime 8.3 (EoS) and Databricks Runtime 8.3 for ML (EoS).
Python and SQL table access control (GA)
June 8, 2021
Table access control lets you programmatically grant and revoke access to your data using the Databricks view-based access control model. Table access control is available in two versions: SQL-only and Python and SQL. Previously only SQL-only table access control was generally available. Now Python and SQL table access control is generally available. See Enable Hive metastore table access control on a cluster (legacy).
Jobs UI and API now show the owner of a job run
June 2-7, 2021: Version 3.47
The jobs UI and API now include the user that a job will run as, making it easier to understand, debug, and audit job permissions. This is a read-only value set to the job creator if job access control is disabled or the job’s is_owner permission if job access control is enabled. For more information about managing job permissions, see Control access to a job.
New Google Cloud region us-west4
June 7, 2021: Version 3.47
Databricks is now available in the region us-west4. See Databricks clouds and regions.
Single Node clusters are now available
June 2, 2021: Version 3.47
You can now create Single Node clusters. A Single Node cluster is a cluster that consists of a Spark driver and no Spark workers. Single Node clusters support Spark jobs and all Spark data sources, including Delta Lake. Single Node clusters are helpful for single-node machine learning workloads that use Spark to load and save data, and for lightweight exploratory data analysis.
Deliver cluster logs to a GCS bucket using a DBFS path
June 3, 2021: Version 3.47
You can now configure a cluster to deliver its Apache Spark cluster logs to a location specified as a DBFS path. Mount a GCS bucket as a DBFS mount and write the logs to a path on that mount. See Compute log delivery.
Cluster-scoped init scripts can now be accessed using a DBFS path
June 2, 2021: Version 3.47
Cluster-scoped init scripts can now use a DBFS path (dbfs:/) instead of a GCS path (gs://). Cluster-scoped init scripts in DBFS must be stored in the DBFS root GCS bucket. Databricks does not support storing init scripts in a DBFS directory created by mounting object storage. See Cluster-scoped init scripts.
Redesigned Workspace Settings UI
June 2-7, 2021: Version 3.47
The new Workspace Settings tab in the Admin Console replaces the Workspace Storage, Access Control Lists, and Advanced tabs for streamlined workspace configuration.
Updates to ListTokens and ListAllTokens database queries expired tokens
June 2-7, 2021: Version 3.47
Database queries ListTokens or ListAllTokens no longer return expired tokens. Indefinite tokens (those with expiryTime set to -1) are returned.
 icon.
icon.