Configure compute (legacy)
Note
These are instructions for the legacy create cluster UI, and are included only for historical accuracy. All customers should be using the updated create cluster UI.
Note
The CLI feature is unavailable on Databricks on Google Cloud as of this release.
This article explains the configuration options available when you create and edit Databricks clusters. It focuses on creating and editing clusters using the UI. For other methods, see the Databricks CLI, the Clusters API, and Databricks Terraform provider.
For help deciding what combination of configuration options suits your needs best, see cluster configuration best practices.
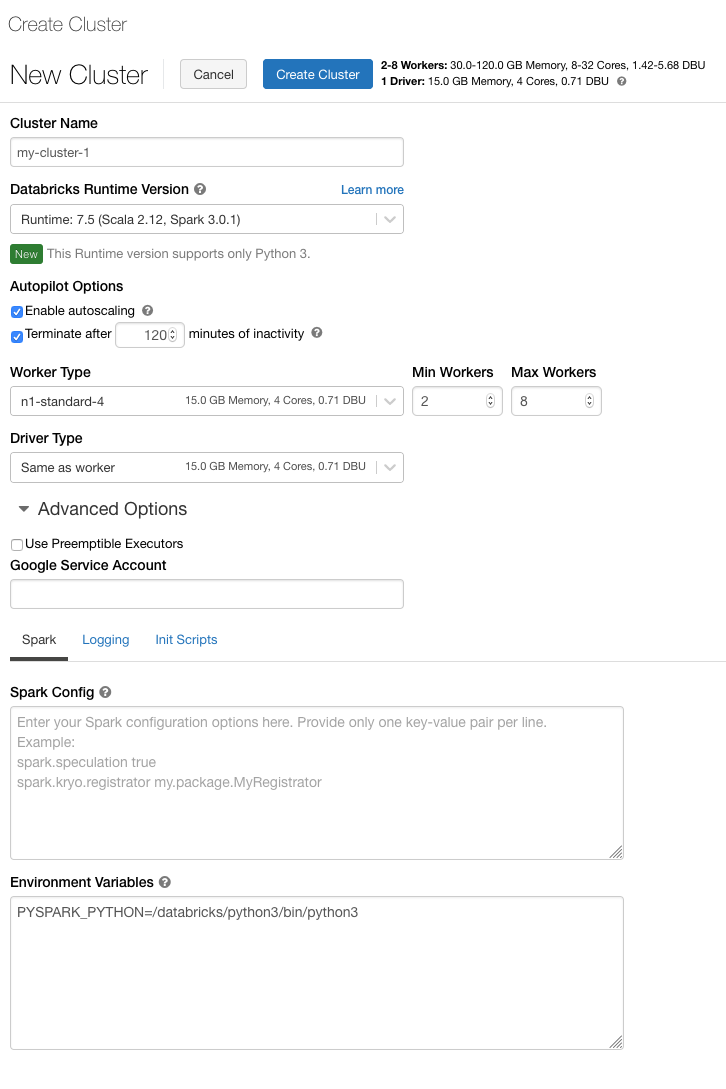
Cluster policy
A cluster policy limits the ability to configure clusters based on a set of rules. The policy rules limit the attributes or attribute values available for cluster creation. Cluster policies have ACLs that limit their use to specific users and groups and thus limit which policies you can select when you create a cluster.
To configure a cluster policy, select the cluster policy in the Policy drop-down.
Note
If no policies have been created in the workspace, the Policy drop-down does not display.
If you have:
Cluster create permission, you can select the Unrestricted policy and create fully-configurable clusters. The Unrestricted policy does not limit any cluster attributes or attribute values.
Both cluster create permission and access to cluster policies, you can select the Unrestricted policy and the policies you have access to.
Access to cluster policies only, you can select the policies you have access to.
Cluster mode
Databricks supports three cluster modes: Standard, High Concurrency, and Single Node. The default cluster mode is Standard.
Important
You cannot change the cluster mode after a cluster is created. If you want a different cluster mode, you must create a new cluster.
The cluster configuration includes an auto terminate setting whose default value depends on cluster mode:
Standard and Single Node clusters terminate automatically after 120 minutes by default.
High Concurrency clusters do not terminate automatically by default.
Standard clusters
Warning
Standard mode clusters (sometimes called No Isolation Shared clusters) can be shared by multiple users, with no isolation between users. If you use the High Concurrency cluster mode without Table ACLs, the same settings are used as Standard mode clusters. Account admins can prevent internal credentials from being automatically generated for Databricks workspace admins on these types of cluster. For more secure options, Databricks recommends alternatives such as high concurrency clusters with Table ACLs.
A Standard cluster is recommended for single users only. Standard clusters can run workloads developed in Python, SQL, R, and Scala.
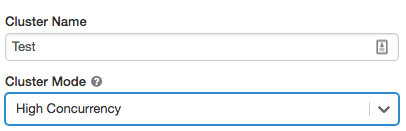
High Concurrency clusters
A High Concurrency cluster is a managed cloud resource. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies.
High Concurrency clusters can run workloads developed in SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala.
In addition, only High Concurrency clusters support table access control.
To create a High Concurrency cluster, set Cluster Mode to High Concurrency.
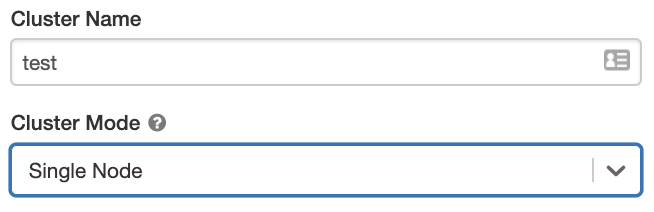
Single Node clusters
A Single Node cluster has no workers and runs Spark jobs on the driver node.
In contrast, a Standard cluster requires at least one Spark worker node in addition to the driver node to execute Spark jobs.
To create a Single Node cluster, set Cluster Mode to Single Node.
To learn more about working with Single Node clusters, see Single-node compute.
Pools
To reduce cluster start time, you can attach a cluster to a predefined pool of idle instances. The cluster is created using instances in the pool. If a pool does not have sufficient idle resources to create the requested driver or workers, the pool expands by allocating new instances from the instance provider. When an attached cluster is terminated, the instances it used are returned to the pool and can be reused by a different cluster.
See Pool configuration reference to learn more about working with pools in Databricks.
Databricks Runtime
Databricks runtimes are the set of core components that run on your clusters. All Databricks runtimes include Apache Spark and add components and updates that improve usability, performance, and security. For details, see Databricks Runtime release notes versions and compatibility.
Databricks offers several types of runtimes and several versions of those runtime types in the Databricks Runtime Version drop-down when you create or edit a cluster.
Photon acceleration
Photon is available for clusters running Databricks Runtime 9.1 LTS and above.
To enable Photon acceleration, select the Use Photon Acceleration checkbox.
If desired, you can specify the instance type in the Worker Type and Driver Type drop-down.
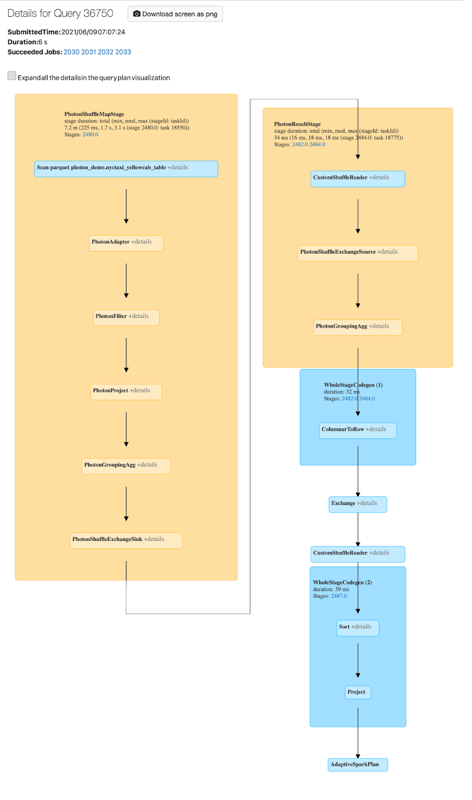
You can view Photon activity in the Spark UI. The following screenshot shows the query details DAG. There are two indications of Photon in the DAG. First, Photon operators start with “Photon”, for example, PhotonGroupingAgg. Second, in the DAG, Photon operators and stages are colored peach, while the non-Photon ones are blue.
Cluster node type
A cluster consists of one driver node and zero or more worker nodes.
You can pick separate cloud provider instance types for the driver and worker nodes, although by default the driver node uses the same instance type as the worker node. Different families of instance types fit different use cases, such as memory-intensive or compute-intensive workloads.
Driver node
The driver node maintains state information of all notebooks attached to the cluster. The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors.
The default value of the driver node type is the same as the worker node type. You can choose a larger driver node type with more memory if you are planning to collect() a lot of data from Spark workers and analyze them in the notebook.
Tip
Since the driver node maintains all of the state information of the notebooks attached, make sure to detach unused notebooks from the driver node.
Worker node
Databricks worker nodes run the Spark executors and other services required for the proper functioning of the clusters. When you distribute your workload with Spark, all of the distributed processing happens on worker nodes. Databricks runs one executor per worker node; therefore the terms executor and worker are used interchangeably in the context of the Databricks architecture.
Tip
To run a Spark job, you need at least one worker node. If a cluster has zero workers, you can run non-Spark commands on the driver node, but Spark commands will fail.
GPU instance types
For computationally challenging tasks that demand high performance, like those associated with deep learning, Databricks supports clusters accelerated with graphics processing units (GPUs). For more information, see GPU-enabled compute.
Cluster instance types with local SSDs
For the latest list of instance types, the prices of each, and the size of the local SSDs, see the GCP pricing estimator.
Instance types that have local SSDs are encrypted with default Google Cloud server-side encryption.
Instance types with local SSDs automatically use disk caching for improved performance. Cache sizes on all instance types are set automatically, so you do not need to set the disk usage explicitly.
Cluster size and autoscaling
When you create a Databricks cluster, you can either provide a fixed number of workers for the cluster or provide a minimum and maximum number of workers for the cluster.
When you provide a fixed size cluster, Databricks ensures that your cluster has the specified number of workers. When you provide a range for the number of workers, Databricks chooses the appropriate number of workers required to run your job. This is referred to as autoscaling.
With autoscaling, Databricks dynamically reallocates workers to account for the characteristics of your job. Certain parts of your pipeline may be more computationally demanding than others, and Databricks automatically adds additional workers during these phases of your job (and removes them when they’re no longer needed).
Autoscaling makes it easier to achieve high cluster utilization, because you don’t need to provision the cluster to match a workload. This applies especially to workloads whose requirements change over time (like exploring a dataset during the course of a day), but it can also apply to a one-time shorter workload whose provisioning requirements are unknown. Autoscaling thus offers two advantages:
Workloads can run faster compared to a constant-sized under-provisioned cluster.
Autoscaling clusters can reduce overall costs compared to a statically-sized cluster.
Depending on the constant size of the cluster and the workload, autoscaling gives you one or both of these benefits at the same time. The cluster size can go below the minimum number of workers selected when the cloud provider terminates instances. In this case, Databricks continuously retries to re-provision instances in order to maintain the minimum number of workers.
Note
Autoscaling is not available for spark-submit jobs.
How autoscaling behaves
Scales up from min to max in 2 steps.
Can scale down even if the cluster is not idle by looking at shuffle file state.
Scales down based on a percentage of current nodes.
On job clusters, scales down if the cluster is underutilized over the last 40 seconds.
On all-purpose clusters, scales down if the cluster is underutilized over the last 150 seconds.
The
spark.databricks.aggressiveWindowDownSSpark configuration property specifies in seconds how often a cluster makes down-scaling decisions. Increasing the value causes a cluster to scale down more slowly. The maximum value is 600.
Enable and configure autoscaling
To allow Databricks to resize your cluster automatically, you enable autoscaling for the cluster and provide the min and max range of workers.
Enable autoscaling.
All-Purpose cluster - On the Create Cluster page, select the Enable autoscaling checkbox in the Autopilot Options box:

Job cluster - On the Configure Cluster page, select the Enable autoscaling checkbox in the Autopilot Options box:

Configure the min and max workers.

When the cluster is running, the cluster detail page displays the number of allocated workers. You can compare number of allocated workers with the worker configuration and make adjustments as needed.
Important
If you are using an instance pool:
Make sure the cluster size requested is less than or equal to the minimum number of idle instances in the pool. If it is larger, cluster startup time will be equivalent to a cluster that doesn’t use a pool.
Autoscaling example
If you reconfigure a static cluster to be an autoscaling cluster, Databricks immediately resizes the cluster within the minimum and maximum bounds and then starts autoscaling. As an example, the following table demonstrates what happens to clusters with a certain initial size if you reconfigure a cluster to autoscale between 5 and 10 nodes.
Initial size |
Size after reconfiguration |
|---|---|
6 |
6 |
12 |
10 |
3 |
5 |
Google Cloud configurations
When you configure a cluster’s Google Cloud instances you can specify Google Cloud-specific options.
Use Preemptible Instances
A preemptible VM instance is an instance that you can create and run at a much lower price than normal instances. However, Google Cloud might stop (preempt) these instances if it requires access to those resources for other tasks. Preemptible instances use excess Google Compute Engine capacity, so their availability varies with usage.
When you create a new cluster, you can enable preemptible VM instances in two different ways:
When you create a cluster using the UI, you can click preemptible instances next to the Worker Type details.
When you create an instance pool using the UI, you can set On-Demand/Preemptible to All preemptible, Preemptible with fallback GCP, or On demand GCP. If preemptible VM instances are not available, by default the cluster will fall back to using on-demand VM instances. To configure the fall-back behavior, set
gcp_attributes.gcp_availabilitytoPREEMPTIBLE_GCPorPREEMPTIBLE_WITH_FALLBACK_GCP. The default isON_DEMAND_GCP.
{
"instance_pool_name": "Preemptible w/o fallback API test",
"node_type_id": "n1-highmem-4",
"gcp_attributes": {
"gcp_availability": "PREEMPTIBLE_GCP"
}
}
Next, create a new cluster and set Pool to a preemptible instance pool.
Google service account
To associate this cluster with a Google service account using Google Identity, click Advanced Options and add your Google service account email address in the Google Service Account field. This value is used to authenticate with the GCS and BigQuery data sources.
Important
The service account that you use to access GCS and BigQuery data sources must be in the same project as the service account that was specified when setting up your Databricks account.
Local disk encryption
Instance types that have local SSDs are encrypted with default Google Cloud server-side encryption. See Cluster instance types with local SSDs.
Spark configuration
To fine tune Spark jobs, you can provide custom Spark configuration properties in a cluster configuration.
On the cluster configuration page, click the Advanced Options toggle.
Click the Spark tab.
In Spark config, enter the configuration properties as one key-value pair per line.
When you configure a cluster using the Cluster API, set Spark properties in the spark_conf field in the Create new cluster API or Update cluster configuration API.
Retrieve a Spark configuration property from a secret
Databricks recommends storing sensitive information, such as passwords, in a secret instead of plaintext. To reference a secret in the Spark configuration, use the following syntax:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
For example, to set a Spark configuration property called password to the value of the secret stored in secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
For more information, see Manage secrets.
Environment variables
You can configure custom environment variables that you can access from init scripts running on a cluster. Databricks also provides predefined environment variables that you can use in init scripts. You cannot override these predefined environment variables.
On the cluster configuration page, click the Advanced Options toggle.
Click the Spark tab.
Set the environment variables in the Environment Variables field.
You can also set environment variables using the spark_env_vars field in the Create new cluster API or Update cluster configuration API.
Cluster tags
Cluster tags allow you to easily monitor the cost of cloud resources used by various groups in your organization. You can specify tags as key-value pairs when you create a cluster, and Databricks applies these tags to Databricks Runtime pods and persistent volumes on the GKE cluster and for use in Databricks DBU usage reports.
The Databricks billable usage graphs in the account console can aggregate usage by individual tags. The billable usage CSV reports downloaded from the same page also include default and custom tags. Tags also propagate to GKE and GCE labels.
For detailed information about how pool and cluster tag types work together, see Attribute usage using tags.
For convenience, Databricks applies four default tags to each cluster: Vendor, Creator, ClusterName, and ClusterId.
In addition, on job clusters, Databricks applies two default tags: RunName and JobId.
Warning
Do not assign a custom tag with the key Name to a cluster. Every cluster has a tag Name whose value is set by Databricks. If you change the value associated with the key Name, the cluster can no longer be tracked by Databricks. As a consequence, the cluster might not be terminated after becoming idle and will continue to incur usage costs.
You can add custom tags when you create a cluster. To configure cluster tags:
On the cluster configuration page, click the Advanced Options toggle.
At the bottom of the page, click the Tags tab.
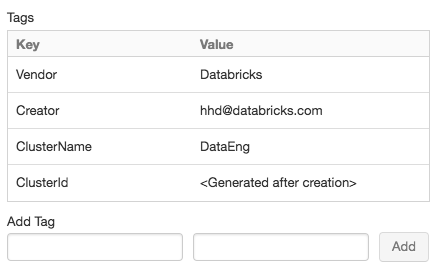
Add a key-value pair for each custom tag. You can add up to 54 custom tags.
SSH access to clusters
Cluster SSH is not supported in this release.
For a related feature, see Run shell commands in Databricks web terminal.
Cluster log delivery
When you create a cluster, you can specify a location to deliver the logs for the Spark driver node, worker nodes, and events. Logs are delivered every five minutes to your chosen destination. When a cluster is terminated, Databricks guarantees to deliver all logs generated up until the cluster was terminated.
The destination of the logs depends on the cluster ID. If the specified destination is
dbfs:/cluster-log-delivery, cluster logs for 0630-191345-leap375 are delivered to
dbfs:/cluster-log-delivery/0630-191345-leap375.
To configure the log delivery location:
On the cluster configuration page, click the Advanced Options toggle.
Click the Logging tab.
Select a destination type.
Enter the cluster log path.
The log path must be a DBFS path that begins with
dbfs:/.
Note
This feature is also available in the REST API. See the Clusters API.
Init scripts
A cluster node initialization—or init—script is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts. You can use init scripts to install packages and libraries not included in the Databricks runtime, modify the JVM system classpath, set system properties and environment variables used by the JVM, or modify Spark configuration parameters, among other configuration tasks.
You can attach init scripts to a cluster by expanding the Advanced Options section and clicking the Init Scripts tab.
For detailed instructions, see What are init scripts?.